




![]()

ZBrain Dynamic Knowledge Base Creation Agent automates the maintenance and continuous updating of organizational knowledge bases. Leveraging a Large Language Model (LLM) and advanced technologies, the agent ensures that knowledge repositories are always current by validating URLs, detecting content changes, and maintaining an up-to-date knowledge base.
The rapid evolution of information and the labor-intensive demands of manual updates often hamper most organizations' efforts to keep their knowledge bases accurate and current. This often leads to the dissemination of outdated or incorrect information, increased workload for staff managing content updates, delays in critical decision-making, and inconsistency across departmental information systems. Such challenges undermine efficiency, reduce productivity, and frustrate both employees and customers.
ZBrain Dynamic Knowledge Base Creation Agent transforms knowledge management by leveraging an LLM and advanced technologies to monitor, identify, and assimilate new data into existing knowledge bases without human intervention. By automating these processes, the agent eliminates manual errors, reduces team workload, and ensures that all stakeholders have access to the most current and accurate information. This not only improves decision-making and customer support but also fosters a more agile and responsive organizational structure.
The agent follows a structured, step-by-step process to ensure accuracy, prevent redundancy, and streamline knowledge management. Below is a detailed breakdown of how the agent processes documents.
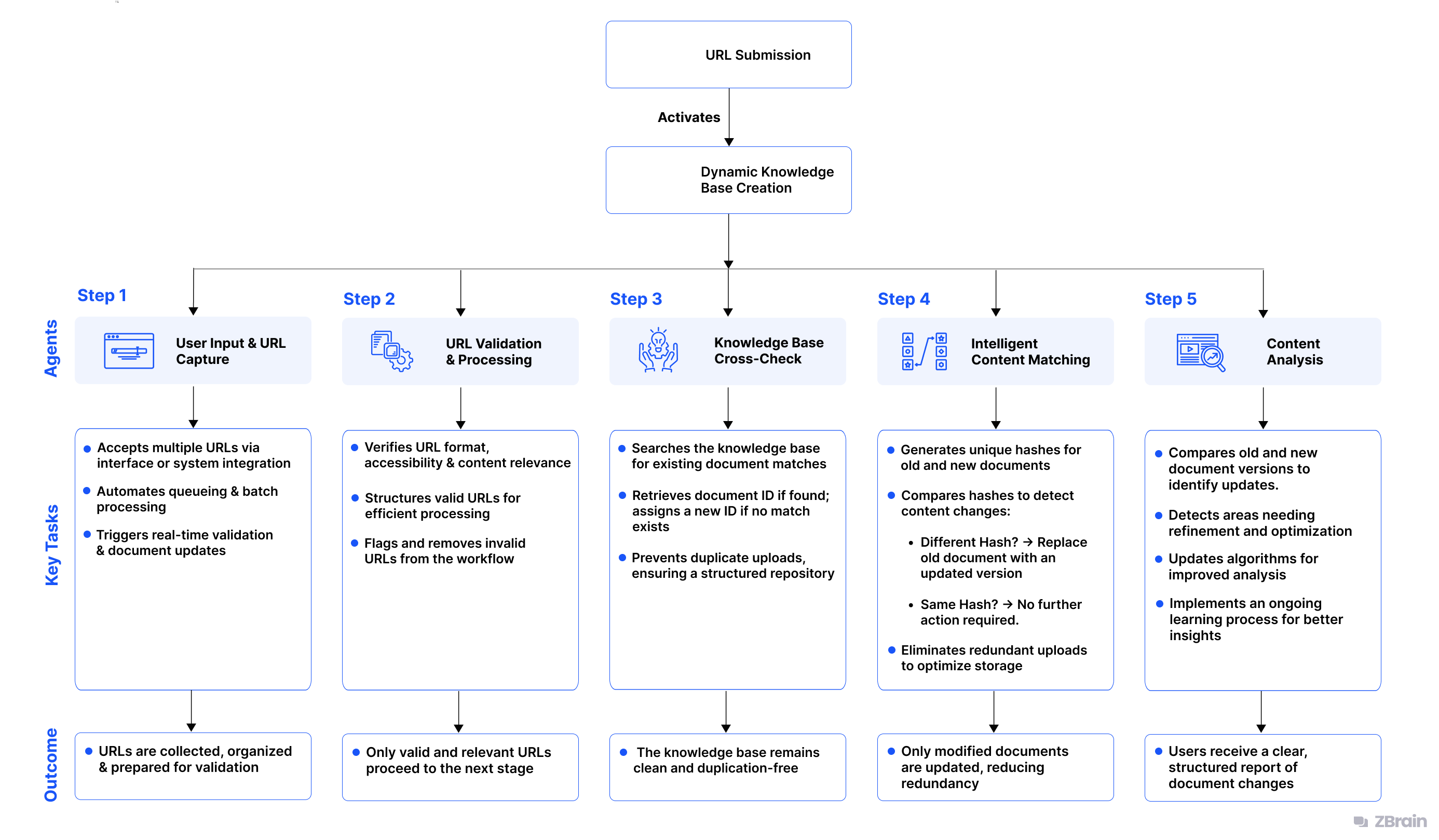
The process begins when a user submits a list of URLs that point to documents intended for addition or update in the knowledge base. These documents can include guidelines, policies, contracts, reports, or other essential digital files.
Key Tasks:
Outcome:
Once URLs are received, the agent validates them for correctness, accessibility, and relevance.
Key Tasks:
Outcome:
The agent scans the KB to check if a document corresponding to the submitted URL already exists.
Key Tasks:
Outcome:
For URLs linked to existing documents, the agent performs a hash comparison to determine whether the content has changed.
Key Tasks:
Outcome:
To confirm and summarize changes, the agent leverages a Large Language Model (LLM) for content comparison.
Key Tasks:
Outcome:
Sample of data set required for Dynamic Knowledge Base Creation Agent:
Source URL
Generative Artificial Intelligence: https://en.wikipedia.org/wiki/Generative_artificial_intelligence
Sample output delivered by the Dynamic Knowledge Base Creation Agent:
Knowledge Base: Generative Artificial Intelligence
Metadata
Generative Artificial Intelligence (Generative AI) refers to a class of AI systems capable of generating new content, such as text, images, audio, or video, based on patterns learned from existing data. This entry provides a summary of Generative AI, including its definition, applications, techniques, and ethical considerations.
Generative AI is a subset of artificial intelligence that focuses on creating new content rather than simply analyzing or interpreting existing data. It leverages machine learning models, particularly deep learning, to generate outputs that mimic human creativity.

Automatically generates detailed, user-adapted instructional guides, including step-by-step tutorials, troubleshooting advice, and contextual tooltips.

customer feedback or queries into comprehensive, solution-oriented tutorials to improve customer self-service and reduce support load.

Generates a simple outline for each feature flag, covering the overview, value proposition, and basic user flow.

Aggregates events from multiple calendar platforms into a unified, intelligent interface that offers real-time synchronization, context-aware summaries, and personalized scheduling recommendations.

Generates realistic and targeted synthetic data to train machine learning models for intelligent agents, ensuring the data aligns with specific use cases and workflows for better performance.

Leverages JQL and NLP to provide quick, context-driven insights from Jira tickets, attachments, and procedural documents.

Book a Demo
with Our AI Experts!
![]()