


How ZBrain breaks the trade-offs in the AI iron triangle

Listen to the article
In enterprise AI, every system faces a familiar dilemma: improve output quality, accelerate response times, or reduce operational costs—but never all three at once. These persistent trade-offs, often referred to as the “Iron Triangle,” has long defined the constraints of large-scale AI deployment. Traditional platforms force trade-offs: use larger models for accuracy and pay with latency and cost; optimize for speed and affordability, and watch answer fidelity degrade. For organizations building production-grade AI, this triangle isn’t just an operating constraint—it’s a strategic barrier.
But what if these trade-offs weren’t inevitable? What if modern architectures could treat quality, speed, and cost not as opposing forces, but as interdependent strengths? As AI moves from pilot to production, enterprise leaders are rethinking how infrastructure, orchestration, and governance intersect—and discovering that the rules of the triangle can, in fact, be bent.
This article examines how this shift is already underway—and how platforms like ZBrain Builder are enabling enterprises to rearchitect their AI strategies, breaking free from the traditional trade-off paradigm. From contextual grounding and agent-based flows to policy-aware execution and modular scaling, we’ll unpack the structural innovations that make simultaneous optimization possible—and the organizational perspective required to sustain it.
- Defining the iron triangle in the AI context
- Key metrics for quality, speed, and cost in AI
- How traditional AI platforms fall short of balancing the triangle
- The business impact of balancing quality, speed, and cost in AI
- Overcoming the iron triangle in AI systems with ZBrain Builder
- Interoperability of pillars – strengthening all sides simultaneously
- AI ownership at scale: Building a cross-functional enterprise capability
Defining the iron triangle in the AI context

The ‘iron triangle’, a concept originally drawn from project management, refers to the trade-offs between three interdependent constraints: quality, speed, and cost. Optimizing for any one of these factors tends to come at the expense of the others. In software or infrastructure projects, the triangle suggests that a system can only maximize two dimensions at a time — you can build something fast and affordable, but it likely won’t be high-quality; or something high-quality and fast, but it won’t be cheap.
In the context of AI, this triangle plays out with even sharper consequences due to the computational intensity, architectural complexity, and real-time user expectations of AI systems. The three sides of the triangle are defined as follows:
The three corners of the ‘iron triangle’
- Quality
Refers to the relevance, factual accuracy, coherence, domain fidelity and safety of an AI system’s outputs. In an enterprise setting, this means generating responses that are not only syntactically fluent but also contextually correct, grounded in proprietary data, and compliant with business rules.- Key challenges: hallucinations, lack of grounding, domain drift, misalignment with enterprise policies
- Performance metrics: accuracy score, retrieval precision, hallucination rate, context match %
- High-quality outputs often require:
- Advanced, large-scale models
- Extensive grounding in enterprise data via Retrieval-Augmented Generation (RAG)
- Complex multi-step reasoning or tool use
These quality-improving steps often increase inference time and cost.
- Speed
Encompasses the latency (response time), throughput (requests handled per second), and deployment agility (time to build/deploy new agents). This is critical for real-time customer interactions, agent workflows, or decision-making systems.- Key challenges: large model inference time, slow RAG pipelines, cold starts, orchestration overhead
- Performance metrics: tail latency (system responsiveness at the 95th/99th percentile), concurrency throughput, time-to-value
- Achieving fast responses typically involves:
- Running smaller or optimized models
- Caching, parallelism, and low-latency infrastructure
But maximizing speed can mean reducing context windows, skipping validation layers, or sacrificing deeper reasoning — potentially lowering quality.
- Cost
Includes both infrastructure costs (e.g., tokens per API call, compute resources) and development costs (e.g., time and skill required to build, fine-tune, and maintain models and apps). Enterprises operating at scale must closely manage usage patterns to avoid increasing cloud bills or lengthy development cycles.- Key challenges: overuse of large models, under-optimized routing, vendor lock-in
- Performance metrics: token usage efficiency (cost per 1,000 tokens), cost per session, engineering hours per agent, retraining frequency
- To keep costs low, enterprises may:
- Use smaller open-source models
- Limit input context windows
- Avoid multi-agent workflows or complex orchestration
Yet these optimizations can reduce answer fidelity or coverage.
Why this triangle matters in AI
Most AI systems can optimize for two dimensions—but not all three simultaneously due to fundamental technical and economic constraints:
- Prioritizing quality and speed usually requires larger or more complex models, which increase compute, cost, and latency.
- Optimizing speed and cost may use low-compute models or caching, often reducing output accuracy and lacking domain grounding or reasoning depth, which lowers quality.
- Focusing on quality and cost via grounding, validation, or multi-agent workflows improves quality but slows latency and adds system complexity.
This situation presents a fundamental dilemma: optimizing one aspect of the triangle frequently compromises the others. A system designed to minimize cost and latency may produce hallucinations; conversely, a system optimized for accuracy and reasoning may incur increased latency and expense. Consequently, this necessitates a continual trade-off in production environments.
For example, a legal research assistant might need high-quality, fully grounded answers (quality), but using GPT-5 for every query in real time would strain both cost and latency budgets. Conversely, a customer service chatbot might require low-latency responses at scale (speed + cost), but without contextual grounding, output quality will suffer.
Enterprise implications
In production settings, failing to balance the triangle can lead to:
- Underperforming user experiences (slow, generic, or error-prone responses)
- Cost overruns due to inefficient model use
- Compliance risks when governance layers are skipped to save time
Researchers and vendors are actively exploring ways to bend this rule – from model optimizations to new architectures – but today the ‘iron triangle’ remains a central challenge in AI solution design.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
Key metrics for quality, speed, and cost in AI

To make informed decisions in this iron triangle, enterprises rely on metrics to quantify each dimension. Some of the key metrics and KPIs used in enterprise AI applications include:
Quality metrics:
These measure how accurate, relevant, and useful the AI’s outputs are. Common metrics depend on the task:
- Accuracy & error rates: For factual or analytical tasks, the error rate or an accuracy percentage is used. For example, in code generation, one might track the percentage of generated code that runs correctly (pass rate), or in chatbots, the rate of correct answers vs. mistakes.
- Benchmark scores: Standardized benchmarks like MMLU (knowledge test), TruthfulQA (factual correctness), BLEU/ROUGE (for text generation fidelity to references), etc., provide quantitative quality scores. For instance, text generation quality can be approximated by perplexity (confidence/fluency of model text) or BLEU/ROUGE for comparing to reference texts. In image generation, metrics like FID (Fréchet Inception Distance) gauge realism.
- Human evaluation: Often, the ultimate judge of quality is human evaluators. Metrics here include average user rating of responses, pairwise preference tests (what % of users prefer AI output vs. a baseline), or more specific criteria. For chatbots, conversational coherence and staying on topic can be measured by human review or through automated checks for relevance.
- Task success rate: Measures whether the AI’s output achieved the intended goal. For example, in a support chatbot, the resolution rate (cases fully resolved by the bot without human hand-off) is a key quality KPI. In generative search or QA, precision/recall of correct info might be tracked. In coding, metrics like pass@N (chance a generated code passes tests) are used.
- Hallucination and safety rates: Especially for enterprise AI, teams track how often the model produces non-factual statements (hallucination rate) or inappropriate content. Lower is better, and improvements here indicate higher quality/trustworthiness.
Speed metrics:
These capture how fast and efficiently the AI system responds and scales:
- Latency: The response time per request, often measured in milliseconds or seconds. Teams look at average latency and tail latency (95th or 99th percentile) to ensure not only fast typical responses but also that upper-bound delays are within an acceptable range. For real-time applications, even a couple of seconds can matter. It’s also noted that consistency of latency is important – e.g., consistently ~2s responses may be preferable to wildly varying 0.5–5s responses, even if the average is similar.
- Throughput: The number of requests or generative tasks the system can handle per second or per minute. At scale, throughput (QPS – queries per second) indicates if the system meets volume demands. This often relates to how well the solution can parallelize and scale out.
- Token generation speed: In text models, a detailed metric is the number of tokens generated per second. For example, an optimized model might generate 50 tokens/second versus a baseline of 20 tokens/second. Faster token throughput generally means lower latency for long outputs.
- System scalability measures: Metrics like concurrent users supported or requests per day can indicate speed at scale. If adding more users starts increasing latency, that’s a sign of hitting a scalability limit.
- Iteration time: In a development sense, one might also measure time to update or fine-tune the model (how quickly can a new version be trained and deployed). While not user-facing speed, a faster iteration cycle speeds up improvement and is sometimes tracked as engineering efficiency.
Cost metrics:
These quantify the financial and resource costs of running the AI solutions:
- Cost per request: A crucial metric for production use – how many dollars does each AI call or generation cost? For API-based models, this is directly tied to token pricing. (e.g., “$0.002 per 1k tokens input, $0.004 per 1k output” – one would compute an average per query). In self-hosted scenarios, the cost per query can be estimated from infrastructure costs divided by queries served.
- Token consumption: Monitoring the tokens used per query is important, as it drives cost on many platforms. Optimizing prompts to be shorter or reducing overlong responses can cut costs. Teams often track the average tokens per request and seek to minimize it without hurting quality.
- Compute utilization: How efficiently resources are used. Metrics such as GPU utilization %, memory usage, and instance hours consumed per day relate to cost. Cloud providers’ bills (GPU-hours, etc.) are the bottom line, but granular metrics help attribute cost to specific parts of the pipeline.
- Overall AI spend vs budget: At a higher level, enterprises track monthly or annual spend on AI services and ensure it stays within ROI targets. Metrics like “AI spend reduction (%)” after optimizations are used to quantify improvements. FinOps tools for AI suggest measuring unit economics, such as cost per 1,000 requests, and how these costs change with optimizations.
- Cost of errors or rework: A frequently overlooked cost aspect is the downstream cost of poor quality. For example, if an AI answer is wrong and a human has to manually fix it, that incurs a cost. Some ROI models factor in the savings from higher accuracy (fewer corrections needed). Similarly, the cost of maintaining the system (e.g., having humans in the loop to review outputs) is considered – if a more inexpensive model requires double the human oversight, it may nullify the pure runtime savings. So businesses sometimes quantify cost per successful outcome (taking into account rework).
- Infrastructure vs API cost trade: Metrics to decide build vs buy: e.g., comparing on-prem GPU cost per million inferences to API cost per million can guide strategy. If self-hosting small models yields significantly lower cost per result (as many report, like Llama 2 being 30× cheaper per summary than GPT-4 with similar accuracy in that task), that metric can drive adoption of a different approach.
It’s worth noting that often composite metrics are used to capture trade-offs. For instance, “quality per dollar” or “inferences per second per $100 of infrastructure” combine dimensions. Teams also align these metrics with business KPIs: e.g., in customer support, average handle time (speed) and first-call resolution (quality) together determine customer satisfaction, and the cost per ticket determines ROI. In sum, having clear metrics for each facet of the triangle helps identify where improvements or compromises are needed.
How traditional AI platforms fall short of balancing the triangle

Legacy AI platforms, designed primarily for isolated machine learning workflows or basic automation, are not equipped to meet the simultaneous demands of quality, speed, and cost that modern AI applications require. These early-generation stacks tend to optimize for one or two sides of the ‘iron triangle’ at the expense of the third—forcing trade-offs that limit scalability, responsiveness, and business impact. Conventional AI platforms and architectures are inherently limited by structural constraints, compelling organizations to accept compromises rather than achieve seamless integration.
1. Heavy reliance on custom code and scripting
Many traditional AI systems require extensive custom coding to build even basic workflows. This increases time-to-market, introduces brittle logic paths, and inflates the cost of maintenance. Each new use case often demands its own bespoke integration script, model configuration, or data pipeline, slowing iteration cycles and increasing engineering overhead.
2. Poor data context and fragmented knowledge sources
High-quality outputs depend on rich, relevant, and up-to-date context. Yet many legacy platforms lack mechanisms to unify or retrieve knowledge from disparate systems (e.g., CRMs, ERPs, internal documents). Incomplete or noisy data degrades model performance, leads to hallucinations or errors, and requires costly post-processing or human oversight to correct—impacting both quality and cost.
3. Siloed and static model deployment
Older platforms tend to lock enterprises into single-model deployments, typically routing all queries—regardless of complexity—to the same general-purpose model. This inflates inference costs for simple queries and slows performance under load. Without flexible model routing or fallback logic, quality, cost, and speed remain rigidly coupled.
4. Lack of modularity in workflow design
AI pipelines are often hardcoded as end-to-end flows with limited ability to plug in new tools, data, or logic without overhauling the entire system. This monolithic design inhibits experimentation, complicates debugging, and makes even minor changes expensive—hampering both agility and cost efficiency.
5. Manual and disconnected governance
Traditional stacks often treat compliance, risk controls, and access policies as afterthoughts. Auditing, PII redaction, or performance evaluation may be managed in external tools or spreadsheets. This not only slows deployment but also increases the chance of errors slipping through, potentially compromising quality and exposing the organization to regulatory penalties.
6. Inflexible infrastructure and scaling
AI workloads are typically hosted on fixed infrastructure or proprietary cloud stacks that don’t scale dynamically. High-traffic spikes result in latency issues or throttling, while idle resources burn budget unnecessarily. Without intelligent scaling or hybrid deployment options, enterprises either overpay for reliability or suffer degraded user experiences.
7. Limited observability
Many legacy AI platforms lack integrated dashboards or real-time metrics on how models and workflows perform. This makes it difficult to understand why an agent failed, which inputs triggered cost spikes, or how changes affect user outcomes. The absence of feedback loops slows learning, inflates troubleshooting costs, and weakens confidence in AI-driven processes.
8. Duplicated efforts and lack of reusability
AI development in traditional settings is often siloed—each team builds its own models, pipelines, and integrations. This leads to inconsistent performance, duplicated engineering, and rising support costs. The lack of shared components or centralized orchestration makes cross-functional scaling nearly impossible.
Traditional AI platforms, while sufficient for prototyping or narrow use cases, fall short when it comes to delivering scalable, cost-effective, and high-quality AI across the enterprise. Their dependence on manual coding, rigid architectures, and disconnected systems reinforces the trade-offs inherent in the Iron Triangle. Enterprises seeking to operationalize AI must move beyond these architectures to platforms that embrace dynamic orchestration, agentic intelligence, and policy-aware execution.
The business impact of balancing quality, speed, and cost in AI
Breaking the iron triangle of AI, traditionally defined by the trade-offs between quality, speed, and cost, represents a pivotal milestone for enterprise-scale adoption. When organizations succeed in harmonizing all three dimensions simultaneously, the impact goes beyond technical gains. It enables durable, cross-functional transformation that reshapes how businesses innovate, scale, and govern their AI initiatives. Below are the key advantages unlocked when these trade-offs are no longer an operational constraint:
1. High-fidelity outputs at scale
Organizations can deliver AI outputs that are accurate, relevant, and aligned with internal policies—without incurring excessive operational costs or latency penalties. With better tuning practices and integration of context, AI becomes reliable across a wider range of sensitive and high-impact solutions.
Benefit: Fewer errors, stronger regulatory alignment, and increased trust in AI decisions across critical domains like healthcare, legal, and finance.
2. Real-time responsiveness
Achieving speed without quality degradation enables AI to support real-time decision-making and customer-facing use cases. Whether handling dynamic queries or supporting live operations, AI systems can act without bottlenecks or information loss.
Benefit: Improved user satisfaction, operational agility, and responsiveness in fast-paced business environments.
3. Sustainable cost optimization
Rather than simply cutting costs, balanced systems make smarter use of compute and workflows. Matching resource allocation to task complexity ensures financial efficiency while preserving system effectiveness.
Benefit: Controlled AI expenditures, better ROI, and the ability to scale without unsustainable infrastructure or licensing growth.
4. Faster innovation and deployment
Minimizing complexity in integration and iteration empowers teams to move from ideation to production more quickly. Business units can collaborate more directly on AI-driven initiatives, shortening time-to-value.
Benefit: Accelerated go-to-market cycles, reduced backlog, and broader participation in AI development across roles.
5. Embedded governance and control
When oversight mechanisms are part of the system design—not layered on after deployment—organizations can enforce policies more consistently and respond to compliance needs with agility.
Benefit: Streamlined audits, proactive risk management, and confidence in scaling AI across regulated environments.
6. Long-term flexibility and ecosystem choice
Balanced architectures tend to be more modular, making it easier to switch tools, adopt new technologies, or evolve AI strategies over time. This enables organizations to respond to change without having to overhaul entire systems.
Benefit: Reduced vendor dependency, adaptability to emerging standards, and long-term resilience in a rapidly shifting tech landscape.
7. Unified scalability across teams
When AI systems perform reliably across use cases and departments, adoption becomes self-reinforcing. Shared infrastructure and common design patterns allow organizations to extend benefits broadly without reinventing the wheel.
Benefit: Efficient reuse of AI components, standardized practices across teams, and a cohesive enterprise AI foundation.
Ultimately, breaking the ‘iron triangle’ allows AI to evolve from experimental utility to enterprise backbone—delivering measurable impact with clarity, control, and confidence.
Overcoming the iron triangle in AI systems with ZBrain Builder

ZBrain Builder is an enterprise-grade agentic AI orchestration platform that enables organizations to rapidly build, deploy, manage, and scale custom AI solutions—such as intelligent agents, assistants, and automated workflows—grounded in proprietary data. Built to deliver high performance, adaptability, and operational scalability, it serves as a centralized platform for building secure, domain-aware, and production-ready solutions that integrate seamlessly into enterprise environments.
ZBrain’s architecture directly challenges the conventional AI trade-off model—the notion that enhancing one aspect inevitably compromises another. Instead of accepting these trade-offs, ZBrain Builder reimagines them as mutually reinforcing capabilities through a composable, orchestrated platform.
The system is built on three interdependent pillars that map to each corner of the triangle:
- Contextual quality and governance
- Agentic speed and automation
- Agnostic efficiency & optimization
Each pillar is designed to enhance its respective domain—ensuring high-quality outputs, rapid development and execution, and optimized, resource-efficient operations—while simultaneously amplifying the others. The result is a strategic AI framework where improvements in one area contribute positively to the others, enabling enterprise-grade solutions that are fast, accurate, and financially sustainable at scale.
The sections below explore each of these pillars in detail and how they combine to form a resilient architecture that breaks through the conventional limitations of the Iron Triangle.
Pillar 1: Contextual quality & governance
To address the quality dimension of the Iron Triangle, ZBrain Builder emphasizes contextual intelligence and governance-first design. Its quality-focused architecture ensures that AI outputs are grounded in real enterprise data, rigorously evaluated for safety and correctness, and tailored to user context. Rather than relying excessively on large models or costly human oversight, ZBrain Builder enhances quality through orchestration that follows enterprise policies, automated checks, and deep contextual grounding. The table below summarizes the key capabilities supporting this quality-first approach.
|
Capability |
Description |
Quality impact |
|---|---|---|
|
Domain grounding |
Integrates proprietary enterprise data directly into AI workflows through a semantically indexed knowledge base. Agents retrieve authoritative, real-time knowledge (e.g, policy documents from SharePoint), enabling fact-based answers. |
Produces accurate, data-backed outputs by minimizing hallucinations and generic responses; enables “context engineering” to constrain models with real knowledge. |
|
Automated quality checks & guardrails |
Built-in evaluation suite and guardrails validate outputs for factuality, policy compliance, and hallucination risk. Automated rewriting or human flagging is triggered when outputs deviate. A human-in-the-loop feedback mechanism continuously improves quality over time. |
Increases output safety, consistency, and enterprise compliance. Prevents inappropriate or low-quality responses from reaching users. Enhances trust and reduces rework or downstream risk. |
|
Multi-model ensemble for quality |
Supports routing sub-tasks to specialized models and verification passes with secondary LLMs or rule-based agents. It challenges the assumption that high quality requires large models. Instead, it emphasizes that quality emerges from the intelligent orchestration of models and knowledge. |
Delivers higher-quality outputs through selective, task-specific ensembling—improving accuracy without relying solely on large, expensive models. |
|
User personalization |
Integrates session history to tailor outputs based on prior interactions and conversation context. By enabling context memory and multi-turn dialogues with history, ZBrain Builder ensures the AI doesn’t give one-size-fits-all answers. |
Increases perceived relevance and quality of responses without additional compute overhead. |
|
Context-oriented prompt orchestration |
Aligned with its context engineering philosophy, ZBrain Builder dynamically assembles all necessary elements—prompts, conversation history, relevant knowledge, tool outputs, and business rules—at runtime so the LLM has what it needs to respond correctly. Maintains long-term and session memory. |
Enhances consistency, continuity, and factual grounding in multi-step conversations and workflows. |
|
Governance & policy enforcement |
Organizations can define and enforce business rules, access controls, and encode policies as guardrails or system instructions. |
Ensures AI agents remain secure, compliant, and auditable—critical for enterprise trust and risk mitigation. |
Together, these capabilities ensure high-quality AI performance. Every answer from a ZBrain agent relies on the right context and data, follows policies, and improves through feedback. This pillar focuses on quality by maximizing accuracy, consistency, and trust in AI outputs without slowing development or increasing costs. Strong context and governance also reduce errors and rework, supporting the other pillars (speed and cost) as explained later.
Pillar 2: Intelligent speed through agentic orchestration
To overcome the speed constraints of the Iron Triangle, enterprises need AI systems that can operate, adapt, and scale in real time without creating fragility. ZBrain Builder addresses the speed dimension through an agentic architecture that prioritizes automation, concurrency, and continuous optimization. Rather than treating AI as a sequence of isolated interactions, ZBrain Builder models workflows as intelligent, orchestrated processes that think and act in parallel. By combining low-code composition, multi-agent coordination, and deep system integration, it enables organizations to move from static chatbots or point solutions to truly responsive, autonomous systems that can handle complex, end-to-end business tasks.
|
Capability |
Description |
Speed impact |
|---|---|---|
|
Low-code, rapid development |
ZBrain Builder shortens AI development cycles through Flows—its low-code visual interface for building AI apps and agents—allowing teams to orchestrate business logic with minimal coding using modular components. It offers a library of pre-built AI agents (through its Agent Store) for common functions that can be deployed immediately or easily customized. |
Accelerates time-to-value and iteration cycles. Reduces dependency on specialized developer resources, enabling rapid experimentation and deployment of AI solutions. |
|
Multi-agent orchestration & parallelism |
Supports concurrent execution by orchestrating multiple agents (“agent crews”) that divide and delegate subtasks in parallel under the coordination of a supervisor agent. Integrates with frameworks like LangGraph and Google ADK to manage branching, conditional logic, and memory across agents. |
Reduces total task latency and enables faster execution for complex workflows. Parallel task handling ensures real-time responsiveness, even for multi-step, computationally intensive processes. |
|
Intelligent workflow automation |
ZBrain agents automate not just responses but end-to-end processes. They connect with enterprise systems (CRM, ERP, ITSM, etc.) via APIs to fetch and update data, take actions, and complete multi-step business tasks autonomously. |
Minimizes human-in-the-loop steps. Shrinks business cycle time dramatically by auto-executing workflows and tasks that traditionally required multiple approvals or handoffs. |
|
Rapid iteration & monitoring |
Provides observability into agent execution via dashboards (inputs, outputs, internal reasoning, token usage, latency) and allows live tuning. Modular architecture means prompts, logic, and agents can be updated independently. AppOps monitors application health and ensures continuous operation. |
Enables real-time optimization and debugging without full redeployments. Maintains responsiveness and system agility even during updates or operational changes. |
|
Component-based scaling |
Rather than scaling the entire system, ZBrain Builder supports the selective scaling of resource-intensive components, such as vector databases or LLM endpoints. It allows horizontal scaling based on workload needs, preserving low-latency operation without overprovisioning. |
Maintains low-latency performance under high traffic through targeted component scaling, concurrent multi-agent execution, and shared context reuse to reduce compute overhead. Prevents degradation during peak usage; avoids system slowdowns through targeted scalability. |
|
High availability & reliability |
The platform supports resilient performance through observability dashboards, continuous evaluations, a modular fail-safe design, and built-in guardrails, enabling early issue detection, fault isolation, and safe updates without disrupting overall operations.
|
Minimizes downtime or request failures. Guarantees stable and predictable response times, which are critical for maintaining user trust and meeting enterprise SLAs. |
This pillar ensures that enterprises achieve velocity without losing control. By embedding automation and orchestration at every layer, teams can iterate, deploy, and optimize continuously, thereby shortening innovation cycles while maintaining stability. The result is autonomous execution at scale, where business processes execute as fast as they can be created, users experience real-time responsiveness, and developers can evolve systems instantly without re-architecting. Speed here isn’t just about latency—it’s about organizational agility, operational resilience, and the capacity to scale AI-driven innovation seamlessly across the enterprise.
Pillar 3: Agnostic efficiency & optimization
The cost dimension of the iron triangle challenges enterprises to maintain scalability and performance without inflating compute or infrastructure spend. ZBrain Builder approaches this through agnostic efficiency—an architectural philosophy that favors flexibility, reuse, and intelligent optimization over indiscriminate scaling. Instead of locking organizations into a single vendor, model, or stack, ZBrain Builder allows them to orchestrate the most efficient combination of components for each task. Every workflow, model call, and retrieval step is optimized to minimize redundancy and maximize value, ensuring that AI deployment remains sustainable and delivers measurable ROI.
|
Capability |
Description |
Cost impact |
|---|---|---|
|
Agnostic orchestration architecture |
ZBrain Builder is agnostic across models, tools, data sources, vector stores, and deployment environments. It enables routing across LLMs based on task complexity, supports multiple vector DBs and RAG pipelines, and allows cloud, on-prem, or hybrid hosting. This flexibility prevents vendor lock-in, maximizes reuse of existing infrastructure, and lets teams select the most efficient components for each use case. |
Maximizes cost efficiency by enabling component-level optimization, vendor negotiation, and resource reusability. Avoids platform over-dependence and supports long-term pricing leverage. |
|
Optimized workflow execution |
Shares context across agents using a unified memory common knowledge base, avoiding redundant prompt expansion or repeated data ingestion. It caches intermediate results (like retrieved data or computation outcomes), reducing external API calls. Agents can use conditional logic to skip unnecessary steps, while guardrails and evaluation tools prevent runaway compute from loops or errors. |
Prevents token bloat and unnecessary API/model calls. Lowers compute waste in multi-agent flows and improves overall cost per task completed. |
|
Low-code efficiency & reusability |
The low-code interface, Flows, and the Agent Store allow teams to assemble logic without writing code from scratch. Once developed, agents and integrations can be reused across multiple applications or departments, thereby avoiding duplicated development and the associated long-term support burdens. |
Cuts engineering and maintenance costs. Accelerates development cycles while spreading investment across more use cases. |
|
Transparent cost monitoring |
ZBrain Builder’s agent dashboards provide per-agent/session analytics on token usage, model calls, and compute time. Teams can monitor which agents consume the most resources and adjust configurations to reduce unnecessary load or rework. |
Enables real-time cost visibility, allowing teams to detect and respond to inefficiencies proactively. Helps manage budgets more accurately across teams and departments. |
By operationalizing cost efficiency through orchestration, observability, and reusability, enterprises can finally achieve sustainable AI economics. This pillar transforms cost from a limiting factor into a competitive advantage, enabling the smarter allocation of compute, faster experimentation within budget, and greater ROI per model deployed. Agnostic optimization ensures that AI investments remain future-proof, portable, and adaptable as technology evolves. Together, these capabilities make efficiency not just about saving money, but about sustaining innovation and resilience across the enterprise AI ecosystem.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
Interoperability of pillars – strengthening all sides simultaneously
A defining strength of ZBrain Builder is the architectural cohesion across its three pillars—each enhancing the others to deliver balanced, enterprise-grade AI performance. Rather than treating quality, speed, and cost as trade-offs, ZBrain Builder’s architecture aligns them into a self-reinforcing system where gains in one dimension amplify the rest:
- Quality ⇄ Speed: High-quality context and governance (Pillar 1) actually enable greater speed. Because ZBrain agents have access to rich, relevant knowledge and well-defined rules, they require less trial and error to get things right, even when operating autonomously. This means fewer slowdowns due to errors or uncertainty. Conversely, the rapid orchestration (Pillar 2) enables the real-time retrieval of fresh data and instantaneous reasoning, thereby maintaining output quality in dynamic situations. Fast iteration cycles also enable quality enhancements (such as prompt tweaks or policy updates) to be deployed quickly across all agents. In short, better context leads to faster correct answers, and faster orchestration provides more opportunities to inject the right context.
- Quality ⇄ Cost: The governance and context mechanisms that ensure quality also drive cost efficiency. By grounding responses in precise data and monitoring outputs, ZBrain Builder avoids the costly consequences of AI mistakes (such as compliance fines or manual rework). The platform’s emphasis on relevant context means it doesn’t waste tokens on irrelevant information, directly controlling LLM usage costs. Meanwhile, cost optimizations (Pillar 3) like model routing can enhance quality: routing a query to a domain-specialized model or a larger model when needed results in a more accurate answer without permanently incurring the cost of using the largest model for everything. Thus, targeted spending on quality where it matters and optimizing costs where it doesn’t – a virtuous cycle of maintaining high accuracy within budget.
- Speed ⇄ Cost: ZBrain Builder’s automation and parallelism accelerate results, but they do so in a cost-aware manner that maximizes ROI. By dividing tasks among specialized agents, workloads are completed faster (reducing expensive compute time on any single model) and with potentially lower-spec models handling sub-parts, which can be cheaper than one model handling the entire task. Additionally, the efficiency pillar ensures that the push for speed does not lead to wasteful resource use; for example, parallel agents share a common knowledge base rather than each loading the same data (avoiding duplicated costs). And when workload spikes, the model-agnostic design can scale out using cost-effective infrastructure to meet demand quickly. In essence, ZBrain Builder turns the typical speed-cost trade-off into a speed-cost interoperability: smart orchestration delivers faster outcomes for the same or lower cost than traditional serial processing.
Overall, ZBrain Builder’s three pillars for the iron triangle function as an integrated “architecture of equilibrium” for AI. By balancing contextual quality, agentic speed, and agnostic efficiency, ZBrain Builder doesn’t force enterprises to choose one dimension at the expense of others. Instead, it strengthens all three sides of the iron triangle simultaneously, converting potential trade-offs into complementary advantages. AI leaders and architects can treat ZBrain Builder not just as a platform, but also as a mental model for orchestrating enterprise-grade AI: each pillar addresses a key strategic requirement (trustworthy intelligence, rapid deployment, and efficient scaling), and together they create a resilient, high-performance AI ecosystem.
AI ownership at scale: Building a cross-functional enterprise capability
As AI moves from experimentation to mission-critical deployment, enterprises must re-evaluate not just how AI is built—but who owns, governs, and stewards it. Traditional ownership models, where AI is siloed within data science or IT, are insufficient for the dynamic, cross-functional demands of modern AI applications.
The iron triangle of quality, speed, and cost introduces inherent trade-offs that cannot be managed in isolation. Navigating these trade-offs effectively requires shifting AI from being a departmental initiative to a core organizational capability—integrated across strategy, operations, and governance. This shift involves several key implications:
1. AI ownership must be cross-functional
Ownership can no longer rest solely with a single department. AI initiatives now intersect with legal, compliance, finance, product, marketing, HR and more. As a result, enterprises must establish cross-functional governance models where:
- Data teams ensure the integrity, freshness, and relevance of data used for AI.
- Product owners define use-case goals and quality thresholds for AI outcomes.
- Engineers/developers provide scalable, reliable implementation and infrastructure.
- Compliance and legal experts embed oversight (especially in regulated industries).
- AI/ML specialists handle modeling, fine-tuning, and ongoing model improvement.
- Operations (IT/Ops) monitors system performance and observability for AI services.
Joint ownership frameworks—such as AI Centers of Excellence (CoEs) are becoming essential to align priorities and enforce accountability. An effective CoE fosters collaboration across business and technical units and sets governance practices to manage ethical and compliance issues. By involving diverse functions, enterprises can ensure AI deployments are well-rounded and responsible from all angles.
2. Strategy teams must frame AI in terms of business outcomes
Rather than measuring success purely in technical metrics (latency, token cost, BLEU scores), enterprise AI ownership must focus on value-driven KPIs such as:
- Time-to-resolution: How quickly does an AI system help resolve customer queries or internal issues?
- Revenue uplift: How much new revenue or sales growth is driven by AI-enabled products or insights?
- Efficiency gains: Reduction in manual processing time or cost savings due to AI automation.
- Compliance incident rate: Decrease in policy or compliance violations because of AI safeguards.
Executive sponsors must ensure that AI programs are directly tied to business objectives, rather than being treated as R&D experiments detached from their core impact.
3. Risk and policy ownership become ongoing, not reactive
In the age of autonomous agents and dynamic retrieval systems, compliance can’t be an afterthought. Enterprises must embed policy-as-code and continuous evaluation mechanisms from the outset. Risk teams need to evolve from static audit models to real-time governance, capable of detecting drift, hallucination risks, or policy violations as they happen—not months later.
Additionally, ownership of AI explainability and user-facing transparency (e.g., disclosure, recourse, audit trails) must be clearly defined—particularly as regulators begin enforcing accountability for algorithmic decisions.
4. IT and platform teams take on AI infrastructure as a shared utility
As AI scales horizontally across the business, infrastructure teams must treat LLM orchestration, vector databases, and retrieval pipelines not as bespoke projects but as shared services—similar to cloud or identity platforms. This includes provisioning, monitoring, cost management, and uptime guarantees for AI systems.
Clear ownership models for system reliability, observability, and performance SLAs are needed—especially in production scenarios where AI response times or outages can directly affect customers or business continuity.
5. AI literacy must be distributed, not centralized
Lastly, strategic AI ownership requires broad organizational enablement. Business users, designers, and analysts are increasingly working with AI interfaces daily. Without appropriate training and understanding, they risk misuse, misinterpretation, or underutilization.
This implies an investment in AI fluency—through documentation, sandbox environments, or certification tracks—so that all stakeholders understand both the capabilities and limitations of AI systems. Democratizing AI safely depends on elevating the collective literacy across roles.
By rethinking ownership structures, enterprises can ensure that AI is not only deployed effectively but also aligned, resilient, and accountable at scale. The organizations that succeed will treat AI not as a tool, but as an enterprise-wide capability shaped through shared strategy, governance, and continuous stewardship.
Endnote
Breaking the iron triangle isn’t just a technical achievement—it’s a strategic imperative for enterprises that see AI as a core lever of growth, efficiency, and differentiation. As organizations transition from experimentation to full-scale deployment, the need for architectural flexibility, operational resilience, and strategic alignment becomes increasingly clear. Achieving all three dimensions simultaneously is no longer a theoretical exercise, but a practical necessity for sustaining innovation, trust, and competitive advantage in a rapidly evolving AI landscape. ZBrain Builder embodies this shift: an orchestration-first platform designed to manage complexity without introducing it—turning rigid pipelines into dynamic systems and fragile prototypes into production-grade solutions.
Ultimately, breaking the iron triangle is not about eliminating constraints, but about designing around them with intent. It requires reframing AI deployment as an interconnected system—one where technical, operational, and strategic factors align. As the landscape evolves, enterprises that succeed will be those that prioritize flexibility, enforceable policy, and a strong foundation for experimentation. In doing so, they position themselves not just to build better AI, but to deliver meaningful, long-term value from it.
Looking to scale AI without compromising on speed, quality, or control? Explore how ZBrain Builder empowers your team to design, deploy, and manage intelligent AI solutions—efficiently, securely, and without trade-offs.
Listen to the article
Author’s Bio


CEO LeewayHertz
An early adopter of emerging technologies, Akash leads innovation in AI, driving transformative solutions that enhance business operations. With his entrepreneurial spirit, technical acumen and passion for AI, Akash continues to explore new horizons, empowering businesses with solutions that enable seamless automation, intelligent decision-making, and next-generation digital experiences.
Table of content
- Defining the iron triangle in the AI context
- Key metrics for quality, speed, and cost in AI
- How traditional AI platforms fall short of balancing the triangle
- The business impact of balancing quality, speed, and cost in AI
- Overcoming the iron triangle in AI systems with ZBrain Builder
- Interoperability of pillars – strengthening all sides simultaneously
- AI ownership at scale: Building a cross-functional enterprise capability
Share Article


Frequently Asked Questions
What is the iron triangle in the context of enterprise AI?
The iron triangle refers to the inherent trade-off between three core goals of AI systems: quality, speed, and cost. Traditionally, optimizing for two of these dimensions comes at the expense of the third. For example, achieving high-quality outputs quickly often results in increased operational costs. It’s a strategic trade-off that limits scalability and production-readiness in AI deployments.
Why do traditional AI platforms struggle to balance quality, speed, and cost?
Legacy platforms typically rely on rigid, monolithic pipelines, static workflows, and tightly coupled infrastructure. These architectures force organizations to prioritize one or two sides of the triangle while sacrificing the third. They often lack orchestration flexibility, modularity, or embedded governance mechanisms to harmonize all three dimensions effectively.
What makes ZBrain Builder "agnostic" and why is that important?
ZBrain Builder is agnostic across LLMs, cloud providers, data sources, and vector stores. This means teams can use their preferred components and swap them as needed without being locked into a single ecosystem. Agnosticism ensures future-proofing, vendor independence, and greater flexibility in optimizing cost-performance trade-offs.
How is ZBrain Builder different from custom in-house AI orchestration builds?
Custom builds require significant engineering effort, longer development cycles, and often rely on disjointed tooling. ZBrain Builder, as a low-code agentic AI orchestration platform, streamlines this process by enabling teams to visually design, deploy, and manage multi-agent systems with modular components, built-in governance, and real-time observability—significantly reducing development overhead while accelerating time-to-value.
How does ZBrain Builder manage compliance, risk, and governance?
ZBrain Builder integrates governance directly into its orchestration logic. Teams can define access controls, apply guardrails, enforce usage policies, and monitor systems through dashboards—ensuring AI operations remain compliant, secure, and auditable.
How can parallel agent execution reduce latency in complex workflows?
Parallel agent orchestration allows multiple subtasks—like document parsing, summarization, and data retrieval—to execute concurrently. This drastically reduces the end-to-end processing time while maintaining a high degree of task specialization and accuracy.
How does ZBrain Builder enable teams to evolve their AI stack without re-architecting?
With its modular and agnostic design, ZBrain allows teams to upgrade or replace specific components (models, vector stores, APIs) independently. This decoupled architecture supports long-term scalability without requiring disruptive reengineering.
What are typical symptoms of an unbalanced AI triangle in production?
Common signs include high hallucination rates (quality issues), slow or inconsistent responses (latency bottlenecks), and excessive token/API costs (poor cost control). These indicators often point to architectural rigidity and suboptimal routing strategies.
What is the benefit of separating context memory from model memory?
Externalized memory (via knowledge bases or session histories) allows models to be stateless yet context-aware. This reduces dependence on fine-tuning, lowers inference cost, and improves scalability across varied use cases.
How does ZBrain Builder avoid duplicated computation in multi-agent systems?
ZBrain agent crew uses shared memory and intermediate caching so agents can reuse data, retrieved content, or decisions. This avoids unnecessary reprocessing and minimizes latency and token waste.
How does effective observability support long-term triangle optimization?
By providing visibility into every layer—inputs, outputs, model calls, latency, and errors—observability allows teams to continuously detect and rebalance inefficiencies, enabling adaptive AI systems that improve over time.
How do we get started with ZBrain™ for AI development?
To begin your AI journey with ZBrain™:
-
Contact us at hello@zbrain.ai
-
Or fill out the inquiry form on zbrain.ai
Our dedicated team will work with you to evaluate your current AI development environment, identify key opportunities for AI integration, and design a customized pilot plan tailored to your organization’s goals.
Insights
Loop Engineering for AI Agents: Building Reliable Autonomous Systems
Loop engineering is the practice of designing, operating, and improving the feedback systems that let an AI agent plan, act, observe the results, and revise its approach until a goal is reached without a human driving every turn.
The AI Trust Gap: Why Governance Architecture Determines Enterprise Value
The trust gap surrounding enterprise AI is fundamentally an architectural challenge, and its solution is increasingly well understood.
The AI ROI illusion: Why enterprises struggle to measure AI impact
Organizations with stronger measurement discipline are better positioned to link AI deployments to measurable business outcomes, prioritize high-impact use cases across the enterprise, allocate capital more effectively, and continuously refine models using real-world performance feedback.
The agentic enterprise: Why AI success requires an operating model redesign
Organizations that redesign their operating models around agentic AI are beginning to outperform those that apply AI only incrementally.
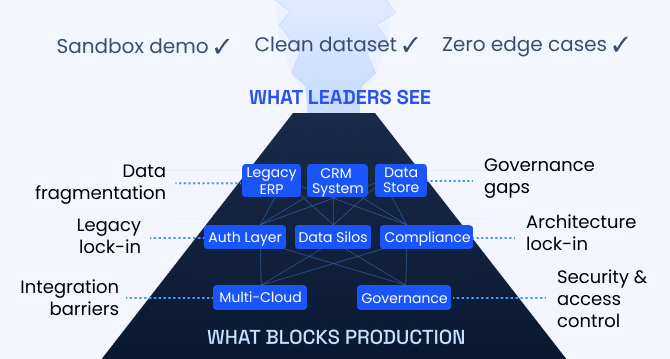
Enterprise AI pilot-to-production gap: Root causes & how to address them
The underlying cause is structural. In many enterprises, AI pilots are developed on infrastructure that was not designed to support production deployment.
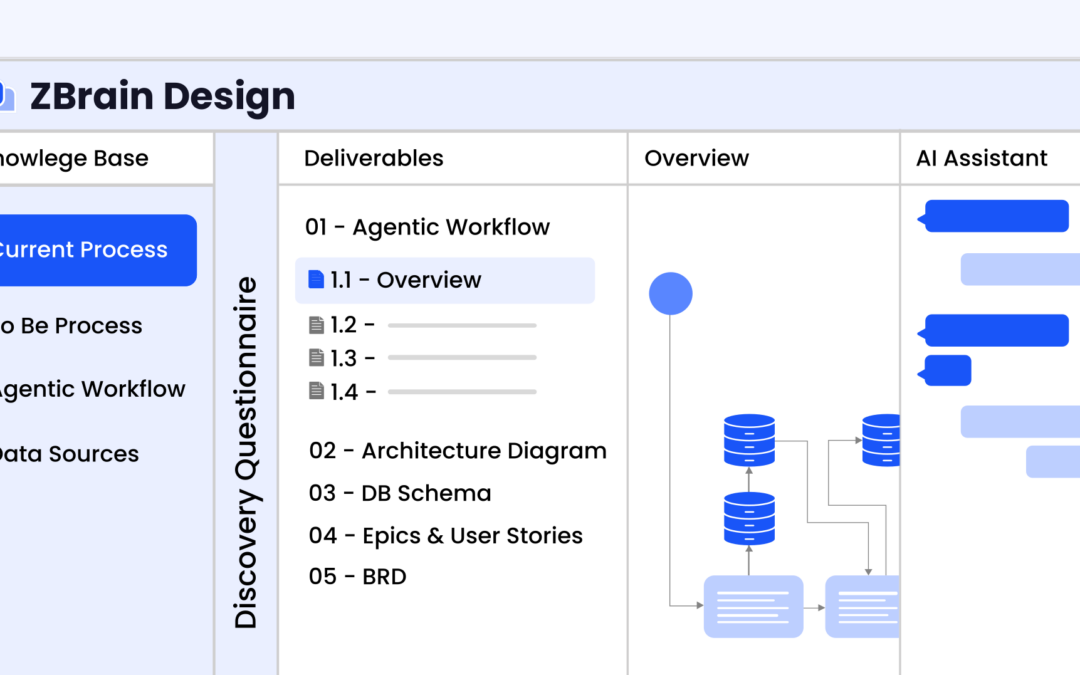
Solution architecture best practices: A guide for enterprise teams
The architecture design process culminates in a set of documented artifacts that communicate the solution to development, operations, and business teams.

Common solution architecture design challenges and solutions
Solution architecture must evolve from fragmented documentation practices to a structured, collaborative, and continuously validated design capability.

Why structured architecture design is the foundation of scalable enterprise systems
Structured architecture design guides enterprises from requirements to build-ready blueprints. Learn key principles, scalability gains, and TechBrain’s approach.
Intranet search engine guide: How it works, use cases, challenges, strategies and future trends
Effective intranet search is a cornerstone of the modern digital workplace, enabling employees to find trusted information quickly and work with greater confidence.
