


The role of knowledge graphs in building agentic AI systems: Architecture, reasoning, and ZBrain’s implementation

Listen to the article
In 2025, roughly 85% of enterprises are expected to incorporate AI agents into their workflows, signaling a shift toward autonomous systems that can plan, act, and adapt rather than passively respond.
Agentic AI refers to autonomous, goal-driven systems that go beyond responding to prompts. Instead, these agents evaluate conditions, formulate strategies, call APIs or databases for information, iterate on feedback, and dynamically adjust actions. In contrast, traditional LLM assistants are reactive—they wait for user input. Agentic agents proactively initiate tasks, making them more akin to digital collaborators than one-time Q&A tools.
However, even the most advanced LLMs have limitations. They are inherently stateless and constrained by context windows (often just a few thousand tokens). This means earlier conversations, user preferences, or evolving knowledge often fall out of scope. More alarmingly, LLMs are prone to hallucinations—they can generate plausible-sounding but incorrect statements when pushed beyond training data. As a result, relying on LLMs alone leaves gaps in memory, verification, and continuity.
To bridge these gaps, agents need a structured memory layer—something persistent, queryable, and trustworthy. Enter knowledge graphs (KGs). A KG encodes entities (nodes) and relationships (edges) into a semantic network of facts. When integrated into an agentic AI stack, the graph provides the agent with grounded memory: it can reference real-world facts, perform logical queries, and retain context across sessions. The LLM continues to handle language and inference, but with the graph as a source of truth, ambiguity and error are reduced.
In this article, we will discover how knowledge graphs elevate agentic AI—enabling persistent memory, multi-hop reasoning, disambiguation, and collaborative agents—and how platforms like ZBrain Builder put these principles into practice.
- Why agentic AI needs knowledge graphs
- Anatomy of knowledge graphs in agentic AI
- Knowledge graphs as the backbone of agentic AI architectures
- Integration patterns: KGs + LLMs + agent frameworks
- ZBrain Builder’s context: Operationalizing knowledge graphs for AI agents
- Challenges and limitations of implementing knowledge graphs for agentic AI
Why agentic AI needs knowledge graphs
Agentic AI systems rely on memory, context, and reasoning to operate autonomously across complex tasks. Knowledge graphs provide the structured relationships and semantic context needed for agents to make informed decisions, collaborate effectively, and adapt to evolving inputs. They enable agents to go beyond isolated prompts—linking facts, goals, and actions into coherent, goal-driven workflows.
Here are key benefits:
Long-term, persistent memory
One of the clearest advantages of integrating a knowledge graph is enabling AI agents with long-term memory. Traditional LLM agents without external memory forget everything once a conversation or task ends; they have no memory of past interactions beyond the prompt.
Crucially, KGs store facts in a structured, queryable form. An agent can look up a specific relationship (e.g., User A → purchased → Product X on date Y) or traverse a chain of events in the graph. This is far more precise than prompting an LLM with a huge text blob of past conversation and hoping it picks out relevant parts. In a knowledge graph, the agent can locate the needed data through a direct query. The result is a stateful agent that accumulates knowledge over time. Knowledge graphs provide a structured form of memory for agents, allowing them to store and retrieve explicit facts and relationships on demand. Whether it’s remembering a client’s settings or the outcome of a multi-step workflow from last week, the KG becomes the agent’s “long-term memory bank.” This persistent memory transforms the agent from a mere reactive responder into something closer to a consistent assistant or colleague that learns over weeks, months, or years.
Contextual grounding
Knowledge graphs also serve as anchor points for context and meaning, grounding the agent’s understanding in unambiguous references. Language is often ambiguous – consider the classic example of the term “Apple.” To a human or an AI, “Apple” could mean the technology company or the fruit, and an LLM might mix contexts if it’s unclear. A knowledge graph helps disambiguate such terms by linking them to specific entities. If a user query mentions “Apple,” an agent can check the KG for entities named “Apple” and see one node for Apple Inc. (the company) and another for apple (the fruit). The relationships in the graph (like “Apple Inc. – type – Company” or connections to tech industry concepts) provide cues to pick the correct interpretation. By grounding words in a semantic graph of entities, an agent reduces misunderstanding and hallucination. In fact, by relying on the KG’s facts, the agent is less likely to generate inaccurate responses —it can retrieve the exact factual information from the graph rather than guessing. As an example, using a knowledge graph can mitigate hallucinations by providing a structured, factual lookup for queries instead of purely probabilistic output.
Beyond disambiguation, KGs provide contextual background, ensuring the agent’s responses remain accurate. Suppose an agent is asked: “What policies apply to project Alpha in Europe?” A well-populated knowledge graph might have nodes for Project Alpha, Compliance Policy X, Region = Europe, and relationships linking them (maybe Project Alpha – governedBy → Policy X, and Policy X – applicableRegion → Europe). The agent can traverse these links to understand that Policy X is relevant. Without a graph, an LLM might not connect “Alpha” to the right policy, or it may hallucinate a policy name. The knowledge graph serves as a contextual grounding layer, ensuring the agent references the correct entities and relationships during its reasoning process. It essentially grounds the conversation in reality: every time the agent is uncertain about a term or a fact, it can consult the KG for a definitive answer or relationship. This greatly reduces errors. In practice, organizations find that using a KG as a knowledge layer leads to far more trustworthy outputs, because the LLM’s answers can be traced back to real, disambiguated entities and data. The knowledge graph thus becomes the agent’s guardrail against misunderstanding – anchoring its language generation in a well-defined semantic context.
Multi-hop reasoning and planning
Many tasks require an AI agent to connect the dots across multiple pieces of information—a form of multi-hop reasoning. Knowledge graphs are inherently designed for this, as they explicitly link entities in a network. An agent can leverage graph traversal to perform logical inferences that would be hard for an LLM alone to do reliably. For instance, consider an agent tasked with assessing a compliance risk: “Does Policy ABC introduce any risks for Project Alpha?” This might be a multi-step logic: Policy ABC is overseen by Department X; Project Alpha is run by Department Y; and perhaps Department Y falls under some regulation related to Policy ABC. Answering this requires joining the dots: Policy → which department owns it → whether that department intersects Project Alpha → relevant risks. In a knowledge graph, each of these facts is a link the agent can follow. The agent might traverse: Policy ABC – ownedBy → Dept X – oversees → Project Alpha, and then find Dept X – flaggedRisk → “Data Privacy Risk”. By walking this chain, the agent uncovers an indirect connection: Project Alpha could have a data privacy risk via Policy ABC’s department.
This kind of reasoning over relationships is where KGs shine. Instead of hoping that one document or one chunk of text contains the whole inference, the agent can pull together facts from different parts of the graph. Graph traversal makes answering multi-hop queries straightforward – e.g., finding how Person A is connected to Company B is just a matter of traversing edges between their nodes. The graph inherently encodes the path (“Person A → works for → Subsidiary of Company B”), so the agent doesn’t rely on any single text passage containing that whole chain. It mimics human logical reasoning: step by step, following relations. Another example: Graph RAG can handle questions like “Who approved X under policy Y?” by finding the node for X, then following an approvedBy relation to a person, and checking if that action is linked to Policy Y. A plain vector search might miss such an answer if the text doesn’t literally spell it out, but a KG can assemble the answer from multiple hops.
Beyond Q&A, multi-hop traversal underpins planning and workflow reasoning. Agents often need to plan sequences of actions: for example, if an agent is orchestrating a task, it must know that Task A must be done before Task B because A provides input to B. These dependency relationships can be modeled in a graph (nodes for tasks, edge “A → prerequisiteFor → B”). The agent’s planner can query the KG to find the order of steps or to discover what resources are needed for a given task. In multi-agent systems, knowledge graphs play a crucial role in representing inter-agent dependencies. When one agent generates information that another agent must consume—such as a policy identifier, customer profile, or workflow decision—the knowledge graph records this as a structured relationship between entities. This linkage isn’t just a data transfer; it’s a semantic connection that preserves meaning, provenance, and context. As a result, agents can coordinate more effectively, accessing shared facts and understanding how their outputs relate to broader objectives, workflows, or other agents’ responsibilities. An orchestration engine uses the graph to ensure prerequisites are met before a dependent task runs. In summary, knowledge graphs enable complex, multi-step reasoning by providing a structural map of relationships. Agents can perform logical inferences and planning by graph search and traversal, retrieving connected facts across several hops to reach a conclusion. This capability is foundational for agentic AI, which frequently must reason not just “one step” but through chains of implications to achieve its goals.
Collaboration across agents
When you deploy multiple AI agents that need to work together, a shared knowledge graph becomes the central hub of knowledge for their collaboration. In a multi-agent setup (often called an “agent crew”), each agent may handle different subtasks – but they all need a shared understanding of the same information to stay aligned. A knowledge graph can act as that shared memory and blackboard, where agents read information. Instead of each agent operating in a silo, the KG provides a global context.
This yields coordinated behavior. Each agent contributes its expertise (one extracts info, another analyzes, another executes actions) while all updates go into the knowledge graph. The next agent in line picks up those updates from the KG, ensuring nothing falls through the cracks. Researchers describe this as a “collective memory”: the graph accumulates the knowledge and results from all agents, enabling asynchronous collaboration.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
Anatomy of knowledge graphs in agentic AI
Core components

A knowledge graph might sound complex, but at its heart, it consists of a few core components that map neatly to how we think about knowledge. Nodes represent entities or concepts – these could be real-world objects, such as a User, Product, or Policy, or abstract entities, such as a Topic or Event. Edges represent the relationships or connections between these entities – for example, owns, reportsTo, relatedTo, dependsOn. Each edge typically has a label indicating the type of relationship and, if applicable, its direction. Together, nodes and edges form a graph data model (often a collection of subject-predicate-object triples). This structure lets us represent facts: e.g., (Alice – supervises – Bob) or (Project Alpha – hasStatus – “Delayed”).
In addition, both nodes and edges can carry attributes or properties. Nodes can have attributes describing the entity (a user node might have an email, a role, a creation date), and edges can have attributes such as a timestamp (when the relationship was established). These attributes provide metadata that enriches the graph’s information. For example, an edge completedTask might have an attribute dateCompleted, or a relationship purchased could include quantity or purchaseDate. Attributes allow the graph to capture not just that two things are related, but additional context about that relation.
Another important element is the schema or data model, which we discuss more in the next subsection. But even at the basic level, nodes belong to certain types (e.g., User vs. Product) and edges have defined types (e.g., assignedTo, locatedIn). This provides consistency. To summarize the anatomy: a knowledge graph is a network of entities (nodes) connected by relationships (edges), often with properties/attributes on both nodes and edges to add detail. This structured representation enables the graph to serve as a rich knowledge store – it’s not just raw text or vectors, but a semantic network the agent can navigate. Because the graph is structured, an agent can perform precise queries like “find all Product nodes that are related to User Alice via a purchased edge in the last 30 days” – something very hard to do with unstructured data alone. These core components (nodes, edges, attributes) are the building blocks that make knowledge graphs powerful but also interpretable as a knowledge source for AI.
Ontologies and schemas
To manage a knowledge graph at scale, especially in a complex domain, you need a well-defined ontology or schema. An ontology is essentially the blueprint or vocabulary for the graph: it defines the types of entities that exist, the types of relationships between them, and the rules or constraints for how they can connect. In other words, the ontology answers: What kinds of nodes can we have, and how can they relate? For example, an ontology might specify that User and Product are entity classes, and there is a relationship type purchased(User, Product), meaning a User can purchase a Product. It might also encode hierarchy (e.g., Manager is a subtype of User) or domain-specific rules (e.g., a Project can dependOn another Project, but a Project cannot dependOn a User, etc.).
Having a schema/ontology is crucial for consistency and logical reasoning. It provides a shared vocabulary so that all data in the graph follows the same format. Ontologies standardize the vocabulary and structure of the graph: they define the entity types and valid relationships, establish interpretation rules, and enable reasoning across the data. For instance, an ontology might assert that a Car is a subclass of Vehicle, and Vehicle must have a hasEngine relationship to an Engine entity. With that in place, an agent or reasoning engine can infer things (if you see an instance of Car, it inherits properties of Vehicle, etc.). Ontologies help the AI understand context – e.g., if the graph knows “Alice is a Manager” and the ontology says Manager is a kind of User, the agent can treat Alice as a User in relevant queries automatically.
In practice, ontologies can be quite rich: they might include definitions for dozens or hundreds of entity types and relationships, perhaps even logic rules (like “if a Person is employedBy a Company and that Company is locatedIn Country X, then that Person is locatedIn Country X, unless overridden”). This provides a layer of domain knowledge on top of raw data. It ensures the knowledge graph aligns with real-world constraints and domain concepts. The benefit is two-fold: interoperability (different systems or agents can share the graph because the schema is well-defined) and reasoning power (the agent can leverage the ontology’s structure to make inferences). For example, through an ontology, an agent might deduce that if entity E is a Car, and Car is defined to have 4 wheels, then E hasPart Wheel (x4) even if not explicitly stated – that’s an inference from schema knowledge.
However, building an ontology is a non-trivial task. It requires carefully modeling the domain with input from subject matter experts. In this context, “modeling” refers to the process of structuring and formalizing knowledge about a specific domain so that it can be represented within an ontology. In dynamic environments, ontologies need to evolve as new concepts emerge (more on that in the Challenges section). The key point here is that ontology = the schema and semantic rules of the knowledge graph. It’s what turns a collection of facts into a coherent knowledge model. In agentic AI, a good ontology provides agents with an understanding of the domain and ensures the knowledge graph remains consistent and unambiguous as it grows. It’s essentially the contract that all knowledge in the graph adheres to, thereby preventing chaos and enabling advanced reasoning and validation on the graph’s content.
Hybrid memory: Graphs + Vectors
It’s important to note that knowledge graphs don’t replace other knowledge stores but rather complement them. Modern agent architectures often use a hybrid memory approach: combining the precise, symbolic recall of a graph with the broad, semantic recall of vector embeddings. Each has strengths: vector databases (embedding stores) are excellent for searching unstructured text or finding semantically similar items (e.g., “find documents related to this query even if wording differs”), while knowledge graphs excel at structured queries and logical joins (e.g., “find items that are specifically related via a defined relationship chain”). By using both, an agent can cover all bases – this is called Graph-RAG (Graph-based Retrieval Augmented Generation) when applied to LLM context retrieval.
A common integration pattern is to use the knowledge graph to identify context, then use vector search for details within that context. For example, suppose an agent gets a complex question: “What were the outcomes of Project Alpha, and who supervised the project manager of Alpha?” The agent might first query the KG to find the specific node for Project Alpha, discover that Project Alpha – hadOutcome → OutcomeXYZ (some summary of outcomes) and also find Project Alpha – projectManager → Alice – supervisor → Bob. Now the agent knows from the graph that OutcomeXYZ is a relevant document or entry (maybe a report) and that Bob is the supervisor it needs to mention. It can then use a vector store to retrieve the full text of OutcomeXYZ (since the KG might store just a pointer or summary) and maybe any additional details about Bob from profiles. This two-stage retrieval means the knowledge graph provides focus (narrowing down the relevant entities and their relationships), and the vector store provides depth (detailed unstructured information, such as passages from reports or emails). The result is more precise and efficient: the graph ensures the agent doesn’t expend time searching the whole corpus blindly – it knows exactly which entities and connections matter – and the vector DB then gives rich content related to those.
This hybrid approach has been shown to significantly improve both the accuracy and efficiency of retrieval. The knowledge graph acts as a semantic filter, constraining the LLM’s context window to only high-relevance, ontologically linked information—reducing noise and improving factual consistency. Meanwhile, the vector search ensures no important unstructured context is missed (like the actual wording of an outcome or the content of a policy document). In essence, graphs and vectors together create a powerful memory synergy: the knowledge graph provides the skeletal structure of knowledge (the who-what-how of facts), and the vector store provides the muscle and flesh (detailed descriptions, raw text). Agentic AI platforms like ZBrain Builder explicitly embrace this, using both to implement what could be called a “memory vault” that’s part symbolic and part semantic. We will see more in later sections how this combination is orchestrated in practice (Graph-RAG and hybrid retrieval pipelines). The takeaway here is that hybrid memory leverages the best of both worlds: the precision and logic of knowledge graphs plus the flexibility of vector semantic search, yielding a robust knowledge foundation for agents.
Knowledge graphs as the backbone of agentic AI architectures
Contextual awareness
In dynamic environments, context is king – and knowledge graphs give agentic AI strong contextual awareness by constantly providing relevant background info and situational data to the agent. An agent with access to a knowledge graph can always enrich its understanding of the current situation by pulling context from the graph in real time.
In practice, agentic systems often perform a KG lookup as a first step upon receiving a query or trigger. If the input mentions any entities (people, products, IDs, etc.), the agent queries the graph to pull related info: attributes of those entities, linked records, and recent updates. This retrieved subgraph (contextual slice of the full knowledge graph) can then be injected into the LLM’s prompt or inform the agent’s next actions. For instance, ZBrain’s Graph RAG approach will search the knowledge graph for nodes relevant to a user’s question and include that structured data in the context given to the language model. The effect is that the LLM is “aware” of the context beyond the user’s immediate prompt – it has the actual data or identifiers at hand, reducing ambiguity.
Consider a concrete scenario: an agent gets a request, “Order 4729 is delayed, what’s the status?” The raw LLM might not know what Order 4729 is, but the agent can query the KG for the Order 4729 node, find it’s linked to Shipment ABC, which has status “In Customs”. It then knows to answer that the order is delayed due to customs clearance, and maybe even identify which customer it belongs to via another link. All of that context (order status, cause, customer) can be gathered via graph queries in milliseconds and provided to the LLM to formulate a precise answer. Without the KG, the model might give a generic or incorrect answer (i.e., hallucinate some status). With the KG, the answer is grounded in the actual context.
In essence, the KG acts as the agent’s eyes and ears on the state of the world, beyond what’s explicitly in the current prompt. It continuously provides the relevant situational data, keeping the agent’s behavior context-appropriate and accurate. This dramatically reduces mistakes due to a lack of context or outdated knowledge, and it enables a form of real-time situational awareness that LLMs lack. The agent always has a reference point to consult for “what do we already know about this?” – and that makes its outputs far more precise and contextually grounded.
Reasoning and planning with graphs
When it comes to complex reasoning and planning, knowledge graphs function as the agent’s logic engine or the data foundation for performing reasoning steps. As discussed earlier, an agent can follow paths in the graph to answer multi-hop questions; this is essentially the agent performing a reasoning chain step by step. In agentic workflows, especially in enterprise scenarios, you often need to enforce business logic or infer implications. KGs can explicitly encode these logical relations, enabling the agent to derive conclusions by traversing or querying the graph. For example, a graph might encode a rule via relationships: “If a project is high-risk, and high-risk projects require executive approval, and Project X is high-risk, then Project X requires Exec Approval.” The agent could deduce that by seeing Project X – riskLevel → High and a separate small subgraph that says HighRisk – requiresApprovalFrom → ExecutiveTeam. By linking those, the agent infers a new needed action (seek approval). This kind of rule-based reasoning is much more transparent with a KG because the relationships are there to validate the inference. Some advanced knowledge graphs even support embedding rule engines or ontological reasoning (e.g., OWL reasoning) to automatically infer such facts.
For planning, knowledge graphs help an agent determine the sequence and dependencies of the actions needed. For instance, the graph might capture a causal chain: Delayed shipment -> missed deadline -> customer churn. If an agent is planning how to mitigate a delay, it can see this chain in the graph and realize that if it doesn’t address the delay, it could lead to churn, prompting it to take preventative action (maybe expedite shipping or inform account managers). In another scenario, a graph of tasks might show that Task B depends on Task A; an orchestration agent will then ensure Task A is completed (by either the same agent or another) before B starts. Essentially, the graph provides a sort of roadmap of the problem space, including constraints and cause-and-effect links, which an agent can use to chart a course of action.
Agents can also use graph algorithms to aid planning – for example, shortest path algorithms to find an optimal connection between two nodes (like the shortest chain of intermediaries in a supply chain graph that links component A to supplier B), or network centrality to find key influencers in an organizational graph when planning a communication strategy. These are classic graph computations that can guide the agent’s plan formulation.
In practical terms, frameworks like LangGraph (an offshoot of LangChain) explicitly model an agent’s plan as a directed graph of steps, where the agent traverses nodes (actions/decisions) and has a shared state passed along. While that’s more of a flowchart for the agent’s internal logic, it reflects the same principle: graph structures make flexible, conditional plans easier to manage than linear scripts.
In summary, knowledge graphs provide agents a structure to reason with and a map to plan with. By following edges, an agent can logically combine pieces of knowledge (reasoning), and by reading subgraphs that represent processes or dependencies, it can determine what to do next (planning). This leads to more sophisticated problem-solving – the agent can handle scenarios where it needs to put together indirect clues or adhere to business rules that span multiple entities. Without a KG, it would rely on the LLM to infer all that, which is error-prone. With the KG, the agent does explicit reasoning using the graph’s connections as guideposts, resulting in much more reliable and explainable reasoning chains.
Tool and action guidance
Another vital role of knowledge graphs in an agentic architecture is guiding which tools or actions the agent should use to accomplish its goals. In complex systems, an agent often has access to numerous tools (APIs, databases, functions) – deciding which one to call in a given situation can itself be a challenge. Knowledge graphs can encode the relationships between tasks and the tools or capabilities needed for those tasks, enabling the agent to query the graph to figure out its next action. For example, imagine a KG that includes nodes representing various APIs or services (email API, CRM database, weather service) and edges that link those to the kind of information or task they are associated with (perhaps CRM API – handles → customer data or WeatherAPI – provides → weather forecast). When an agent formulates a plan like “get customer contact info and then send notification”, it can look at the graph and see that “to get customer contact info” one should use the CRM API, and for “send notification” one should use the Email service. Essentially, the KG can act as a directory of capabilities where the relationships tell the agent, “for this type of query or entity, this is the relevant tool.”
Overall, knowledge graphs help encode procedural knowledge and system knowledge that guides agent actions. By querying the graph, an agent can answer: What should I do next? Which API deals with this entity? Has this action already been done? Who is responsible for this type of request? – all crucial for autonomous operation. Without a KG, these would either be hardcoded or learned implicitly (and unreliably) by the LLM. With the KG, the agent effectively consults a structured playbook or configuration that is easily updateable and inspectable. This ensures that agentic AI actions remain correct, efficient, and in alignment with organizational processes, since the knowledge graph can encode those processes and map tasks to tools accordingly. It also aids in compliance – for example, the graph might encode that “to approve expense > $1000, call ApprovalService”, so the agent will know to route such cases rather than handling them itself, following the rules encoded in the knowledge graph.
Integration patterns: KGs + LLMs + agent frameworks
Retrieval-Augmented Generation with graphs (Graph-RAG)
One of the most powerful patterns to emerge for combining LLMs with knowledge graphs is Retrieval-Augmented Generation (RAG) using graphs – often dubbed Graph-RAG. In a traditional RAG setup, when the LLM needs to answer a question, it retrieves relevant documents (via vector search) and stuffs them into the prompt as context. Graph-RAG enhances this by retrieving knowledge graph content (entities, relationships, summaries) as part of the context, not just raw documents. The pipeline typically works like this: given a user query, the system first links the query to the knowledge graph – e.g., identifies which entities are mentioned or implied. It then searches the graph for a subgraph relevant to the query. This could involve finding the specific node and its neighbors, or traversing to gather facts that form the “answer path.” Because the graph is structured, it can answer certain queries directly: for example, a deterministic question like “How is A related to B?” can be solved by graph traversal without even involving the LLM. For more open-ended questions, the graph can provide a skeleton of the answer – key facts and connections – which are then passed to the LLM.
Once the relevant graph information is retrieved, it is transformed into a form that the LLM can use. This might be a set of triples, a text summary of a subgraph, or a list of facts. ZBrain’s Graph RAG, for instance, can provide community summaries or neighboring node facts as context. The LLM then generates the answer using both the graph-derived info and any additional vector-retrieved text if needed (often it’s a hybrid: graph narrows the scope, then vectors fetch specific passages in that scope). The result is an answer grounded in the organization’s structured knowledge and ideally citing the pertinent facts. The knowledge graph (KG) encodes semantic connections, enabling the large language model (LLM) to establish relationships more effectively. It acquires these connections directly from the graph rather than inferring them from unrelated text.
Graph-RAG has shown significant benefits in factual accuracy and efficiency. By leveraging the graph’s ability to filter and relate information, the system often needs to feed far fewer tokens into the LLM context window than a pure vector approach. Graph-RAG can use fewer tokens for the same queries, since it supplies a concise representation of relevant info. Fewer tokens means faster responses and lower cost.
Another advantage of Graph-RAG is transparency and traceability. Since the graph provides an “evidence trail” of relationships, the answer can often be explained by citing that trail (e.g., “Project Alpha is high-risk because it’s linked to Regulation Z via Policy Y” – an explanation that mirrors a path in the graph). In enterprise settings, this is gold: stakeholders get not just answers but the reasoning, increasing trust. Indeed, Graph-RAG delivers “path-based evidence, making outcomes traceable and auditable”. Many implementations will highlight which nodes or facts led to the answer, almost like showing your thought process. This is much harder to do with purely vector-based RAG, where it’s unclear how pieces of text relate logically. With Graph-RAG, the logical relationships are explicit.
In summary, Graph-RAG adds the strengths of knowledge graphs with LLM generation. The KG acts as a precise filter and context provider, and the LLM uses that context to produce contextually accurate responses. This pattern ensures that answers are both grounded in real data (reducing hallucinations) and comprehensive (since the graph can pull in disparate but related facts). ZBrain Builder, for example, uses such an approach to great effect in enterprise search, yielding more precise answers and dramatically cutting resolution times for complex queries. For anyone implementing agentic AI, Graph-RAG is a key architectural pattern to achieve factual, context-rich generation by leveraging structured knowledge.
Orchestration via agent frameworks
Integrating knowledge graphs into the agent’s reasoning loop is greatly facilitated by modern agent frameworks and orchestration libraries. Frameworks such as LangChain, LangGraph, and Semantic Kernel provide abstractions that allow an LLM agent to call external tools or queries (like a database or KG query) as part of its decision-making. In these frameworks, you can define the knowledge graph as a tool or resource that the agent can use. During the agent’s reasoning (often realized as an iterative loop of thinking and acting), the agent can decide, “I should query the knowledge graph for X”, perform that query via the integration, and then incorporate the result into its next step.
For example, LangChain supports custom tools where the tool could be “Query_KG” – the agent’s LLM, when prompted with a certain situation, might output an action like Query_KG["find user preferences for John Doe"], and the framework will execute that, get the results, and feed them back into the LLM’s context. This is a form of dynamic orchestration: the agent isn’t just a single prompt/response; it’s an autonomous loop that chooses actions like querying the KG, calling an API, etc., based on the current state. In such a setup, knowledge graphs become seamlessly integrated into the agent’s cognition. Whenever a structured piece of information is needed, the agent uses the KG.
LangGraph, as mentioned earlier, is an agent framework that inherently uses a graph structure to define agent logic. It maintains a shared state that persists across the agent’s flow, which could include a knowledge graph. Semantic Kernel (by Microsoft) provides the concepts of “planner” and “memory,” where a graph or another store can back the memory. In ZBrain’s architecture, they mention that orchestration frameworks such as LangGraph or Semantic Kernel enable state (including long-term memory from vectors or graphs) to pass seamlessly through the agent’s workflow. This means that if one step of the agent added a fact to the KG, a later step can easily retrieve it, because the framework manages that continuity.
Another aspect is multi-agent orchestration (agent crews). Here, frameworks coordinate multiple agents—for instance, using ZBrain’s Agent Crew or Microsoft’s Autonomous Agents framework. These orchestrators often use the knowledge graph as the shared memory and coordination medium. They might implement logic such as: after Agent A finishes task 1, write results to KG; then Agent B (monitoring the KG or prompted by the orchestrator) sees new info in KG and starts task 2. Such orchestration ensures that the state is not lost between agents, and the KG often plays the central role in that state management.
In summary, modern agent frameworks are designed to integrate LLM reasoning with internal knowledge sources like KGs. They provide the plumbing and patterns (function calls, tools, memory managers) so that developers can attach a knowledge graph without reinventing the wheel. The result is that an LLM agent can effectively “think, look up in KG, think more, call a tool, update KG, think again…” and so on – a powerful loop that harnesses both the neural and the symbolic. ZBrain’s architecture, for instance, leverages this: their low-code platform lets you attach knowledge bases (vector or graph) to agents, and the agents automatically query those during execution. By using these platforms, integrating a KG becomes less about complex engineering and more about configuration—you tell the agent “here’s your knowledge graph tool” and maybe give it some prompt instructions on when to use it. The agent then learns to use the KG as part of its reasoning. This tight integration is what enables agents to be both smart and knowledgeable, leveraging LLM capabilities alongside structured data queries in a fluid way.
Shared state graphs for multi-agent crews
We have discussed multi-agent collaboration earlier; now, let’s focus on how exactly shared knowledge graphs facilitate it at an architectural level. In an “agent crew” (multiple agents working together on a task), the shared state graph is often the linchpin that holds the team’s knowledge and progress together. Architecturally, one can think of the knowledge graph as a shared blackboard or database accessible to all agents. Each agent may have its own LLM instance or process, possibly specialized for certain tasks, but they don’t operate in isolation—the graph is their collective memory and state.
For example, ZBrain’s Agent Crew framework explicitly uses a centralized orchestrator and a shared knowledge base to enable coordination. In many cases, this knowledge base is hybrid (both a vector store and a graph), but the graph component is crucial for structured information.
The shared graph also helps maintain consistency. If one agent updates a fact (e.g., marks a task as completed in the graph), all other agents see the single source of truth and won’t duplicate work or contradict each other. In a sense, the KG becomes the authority on the current state of the world that the agents are operating in. In distributed AI systems, avoiding divergent views of state is hard, but a shared knowledge graph addresses that by design – everyone literally queries the same graph database.
In practical design, an agent crew orchestrator might implement loops where, after each agent does something, the shared state (graph) is updated, and optionally the orchestrator or another agent evaluates whether the goal is met or what the next step is. The graph thus serves as the message-passing medium as well, with the advantage that those “messages” persist as knowledge.
In summary, a shared knowledge graph is foundational for multi-agent systems. It provides a unified memory and state that all agents trust and update. This leads to coherent teamwork among agents – much like a well-coordinated human team that shares notes and knowledge – and it ensures that even as agents specialize or become dynamic, the overall “brain” (the graph) retains the knowledge. Enterprises adopting agent crews will find that without a shared knowledge layer, agents may interfere with each other or lose context. With this layer, they operate in concert, significantly improving collective performance.
Explainability and traceability
One of the unsung strengths of knowledge graphs in the context of AI agents is how they improve the explainability and traceability of the system’s decisions. In industries like finance, healthcare, or any enterprise setting, it’s often not enough for an AI to answer – it must also provide reasoning or be auditable after the fact. Knowledge graphs, by their nature, provide a structured record of what the AI knew and how it pieced together an answer.
Consider an agent answering: “Can we fast-track Project Alpha under current policy?” If it answers “No, because Project Alpha is classified as High Risk and Policy 123 forbids fast-tracking high-risk projects,” a knowledge graph would allow you to trace that reasoning: the agent likely checked the graph and found Project Alpha – riskLevel → High, and an edge or rule in the graph that Policy123 – prohibits → fastTrack (for riskLevel=High). Thus, the answer isn’t just a black box – it’s explicitly supported by graph facts. If an auditor or the user asks “Why?”, the agent can show those relationships as justification. This is essentially path-based evidence. In Graph-RAG based solutions, for instance, the output often includes the path or nodes that led to the answer, making the answer transparent and auditable.
Knowledge graphs also log interactions and derived facts. Each time an agent writes something to the graph (like “Outcome of Task X = Y” or “User confirmed preference Z”), that becomes part of the record. Later, one can inspect the graph to see how the agent arrived at a conclusion or what information it had at each step. This is immensely useful for debugging and building trust. If the agent made a wrong decision, you might find it was because a wrong fact was in the graph or a relationship was missing, which you can then correct. Without a KG, an agent’s reasoning process remains largely hidden within the LLM and is temporary. With a KG, a lot of the intermediate reasoning is externalized as graph updates or traversals, which you can monitor.
In enterprise governance, this traceability maps to requirements for compliance and accountability. Companies can maintain audit logs linked to the KG’s state. For instance, if an agent gave financial advice, the KG might log which data points (nodes/edges) it considered, and you can later justify that advice by referencing those data points.
Additionally, because knowledge graphs enforce a schema, they prevent a lot of garbage-in reasoning. If some data doesn’t fit the schema, it’s either not allowed in or marked as such, preventing the agent from using malformed data. This consistency means the agent’s reasoning is less likely to run on incorrect or contradictory information, which, in turn, makes its decisions more explainable (since they follow a consistent logic).
For explainability to end-users, one approach is to present a visual subgraph of how the answer was deduced. An AI agent could similarly show, “Here’s how I answered: [Customer] –linked to– [Project Alpha] –hasStatus→ Delayed; [Policy] –appliesTo→ HighRisk projects; etc.” This gives confidence to the user that the agent didn’t just make it up – it followed a chain of known facts.
In summary, knowledge graphs provide a built-in mechanism for explainable AI. The connections an agent follows in the KG serve as the rationale for its outputs, which can be inspected and understood by humans. It transforms the agent’s decision-making from an ambiguous neural process into a more logical, stepwise process that mirrors human reasoning. This not only improves trust but is often essential for organizations that need to justify AI decisions to regulators or stakeholders.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
ZBrain Builder’s context: Operationalizing knowledge graphs for AI agents
ZBrain’s architecture overview
ZBrain’s agentic AI orchestration platform provides a concrete example of how knowledge graphs are integrated into a real-world agent architecture. In the ZBrain Builder’s stack, the knowledge graph is part of the platform’s structured memory layer. ZBrain’s architecture has multiple modules (perception, cognitive, action, memory, etc.), and within the Memory module, knowledge graphs play a key role alongside vector stores. Specifically, ZBrain maintains a shared knowledge repository that combines vector embeddings for unstructured data and a knowledge graph for structured facts.
In ZBrain Builder, agents can be organized into crews (a supervisor and sub-agents). The shared memory/knowledge base is central to that crew’s functioning – it’s how agents share context. Shared memory (a knowledge repository) serves as a centralized hub for information sharing, enabling coordinated strategies among multiple agents.
ZBrain’s low-code interface likely lets designers define the schema for their knowledge graph according to their domain (e.g., entities for “Ticket”, “Customer”, “Product”, etc. in a support scenario). This ensures that the KG captures domain-specific knowledge consistently. The platform has a component for “Knowledge Base” where one can connect data sources or upload knowledge, which then get structured into the graph or vector index as appropriate. ZBrain shows guides on creating a knowledge base using a knowledge graph – suggesting it provides tools to ingest data into the KG.
An agent built with ZBrain inherently has access to long-term memory via the knowledge graph. In a sense, ZBrain’s architecture treats the knowledge graph and vector DB as integral layers of its data and reasoning stack. This aligns with the philosophy of stateful agents: using long-term vector databases and knowledge graphs to explore how state management is practical for real-world solutions. In summary, ZBrain’s stack illustrates how, in an enterprise agent platform, the KG sits at the heart of memory and context, feeding into the agent’s reasoning cycle at every step and persisting knowledge between steps and sessions.
Hybrid retrieval in practice
ZBrain’s implementation of knowledge retrieval provides a great example of the hybrid Graph+Vector approach discussed earlier. In practice, when a ZBrain agent needs information, it retrieves using vector search, a graph query, or both, depending on the query complexity. Simple, broad queries often use the vector store when a quick semantic match is sufficient, but for more complex, relationship-based queries, graph is invoked. ZBrain Builder leverages vector indices and knowledge graphs in a cohesive manner. If a user’s query is something like “What are the latest updates on project Omega?”, that might be answered by vector search pulling the latest status document. But a query like “Which compliance policies apply to Project Omega’s region and domain?” involves multiple factors (project → region → policies), which the graph is better at.
In a compliance scenario, for example, ZBrain might store structured data about policies: each policy node could have relationships like appliesToRegion, appliesToDepartment, etc. The agent can find the Project Omega node in the graph, see its region (say Europe) and department (Finance), then traverse to find any Policy nodes that have Region: Europe or Dept: Finance. This structured filtering is much easier and more accurate via KG than trying to parse it from text with an LLM.
In summary, ZBrain’s practical retrieval system uses KGs for what they are best at (structured, multi-hop queries, filtering) and vectors for what they excel at (semantic similarity in unstructured text), orchestrating them together. The agent uses both as needed, resulting in robust retrieval pipelines that can handle simple FAQ-type queries and complex analytical queries with equal ease. This hybrid retrieval is a cornerstone of how ZBrain solution delivers contextual precision in answers, as well as the ability to do multi-hop reasoning over enterprise knowledge seamlessly.
Contextual precision and multi-hop reasoning
ZBrain Builder leverages knowledge graphs to improve contextual precision and enable reliable multi-hop reasoning in its agent responses. In an enterprise context, queries often require drawing on multiple data points and ensuring the answer is contextualized correctly (e.g., distinguishing between similar terms or applying the right policy to the right scenario). The KG in ZBrain provides a kind of contextual filter or anchor for the LLM, so that the model injects exactly the right facts. This minimizes the risk of the model guessing or hallucinating, as it always refers back to an authoritative context in the KG.
Take the example of policy compliance reasoning we’ve been using. Without a KG, if asked “Is Project Alpha compliant with Policy Z?”, an LLM might not truly “know” what Project Alpha or Policy Z are – it might try to infer from name similarity or general knowledge, likely producing a generic answer. With ZBrain’s KG, the agent can find Project Alpha in the graph, see all its attributes (region, risk level, etc.) and find Policy Z node, then explicitly check relationships: maybe Policy Z – requires – SecurityReview for HighRisk projects. If Project Alpha is marked HighRisk in the KG, the agent concludes it’s not compliant (no security review done yet). It can then answer with that reasoning, and importantly cite the specific facts: “Project Alpha is High Risk, and Policy Z requires extra review for High Risk projects, hence non-compliant.” This level of contextual accuracy – using the exact classification of the project and the exact clause of the policy – is made possible by the KG’s structured representation. The agent isn’t relying on the LLM’s training to recall policy rules (which could be wrong or outdated); it’s pulling the current, specific rule from the graph, ensuring correctness.
Multi-hop reasoning is also robustly handled. If a question spans departments and consequences (like the earlier “policy → department → risk” chain), ZBrain’s KG can be traversed to answer that in a step-by-step deterministic way. The platform encodes organization hierarchies, project statuses, risk assessments, etc., within the graph. The LLM essentially uses the KG to do what we would call a chain-of-thought: but it’s not guessing the chain – it’s literally traversing it. For example, the agent might do:
- Hop 1: Find Project Alpha node, get its attributes (Dept = Finance, Risk = High).
- Hop 2: Find Policy Z node, check if it has any rules applying to Finance or High risk.
- Hop 3: If needed, traverse to see what consequence or action is linked (e.g., “requires approval from CFO”).
Each hop corresponds to a graph query, and the results inform the next step. This explicit multi-hop is both faster and more reliable than making the LLM read volumes of text, hoping it will implicitly perform the reasoning.
ZBrain’s use of Graph RAG demonstrates reduced hallucinations because the model isn’t left to fill gaps – the graph covers the needed connections, so the model doesn’t invent them.
An interesting point is enforcing context accuracy. If the KG states that X is related to Y, the agent should trust this over any conflicting information in an unrelated document. Graph context can override what the LLM might otherwise assume from generic knowledge. For instance, generically, an LLM might “know” a product is discontinued (from training data), but if the company’s KG says that product was relaunched, the agent should use the KG fact. ZBrain’s design presumably ensures the KG facts are given priority in the prompt or via function calls, thereby grounding the LLM in the latest truth.
In multi-hop enterprise scenarios like policy → department → compliance risk, ZBrain’s KG essentially acts like a reasoning scaffold. The LLM can step through each relation with certainty, and thus the final answer has the correct context at each part. This prevents those situations where an LLM might otherwise mix contexts or apply a rule to the wrong entity. The enforcement of context accuracy also comes from how KGs disambiguate similar entities (like two projects named “Apollo” in different divisions – the graph would have them as separate nodes with different attributes, ensuring queries target the right one).
To sum up, ZBrain Builder uses the KG to achieve contextual accuracy and reliable multi-hop logic in answers:
- It disambiguates entities and terms in the query (so the agent knows exactly what the user means).
- It supplies all necessary intermediate facts (so the agent doesn’t guess them).
- It anchors the reasoning at each step in actual data (so the agent’s chain-of-thought is valid).
- It thereby reduces hallucination and error, giving answers that are both correct and contextually appropriate for the enterprise environment (no irrelevant or outdated info injected).
This is critical in enterprise settings – an AI that gives a confidently wrong answer about compliance or mis-contextualizes a situation can cause serious issues. ZBrain’s approach shows that knowledge graphs are a key antidote to those problems by enforcing a contextual truth that the agent must adhere to.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
Challenges and limitations of implementing knowledge graphs for agentic AI
Scalability
As powerful as knowledge graphs are, one major challenge in implementing them for agentic AI is scalability – both in terms of building the graph and querying it efficiently as it grows. Enterprise knowledge graphs can easily span millions of nodes and edges (imagine a graph node for every customer, product, employee, document, etc., and all their interrelations). Querying such a large graph with low latency is non-trivial. Simple graph queries (like find a node by ID) are fine, but more complex traversals or pattern matches can become slow as the graph size increases, especially if not indexed properly. Without careful design, an agent’s request that triggers a multi-hop traversal could time out if the graph is huge or densely connected.
Moreover, graph construction and updates at scale are challenging. Ingesting data from diverse sources into a coherent graph requires entity resolution (identifying that two mentions refer to the same entity), which can be computationally intensive.
Graph database performance is another factor. Traditional graph databases (like Neo4j, JanusGraph, Neptune, etc.) each have different performance profiles and indexing capabilities. Choosing the right one and optimizing it is key. It’s agnostic to the underlying store and that enterprise graphs can scale with graph databases. Techniques like indexing or caching common traversals, limiting path lengths, and precomputing frequent join results to improve performance. For example, if “shortest path between any two people” is a common query in an org graph, you might cache those results rather than recompute them each time.
Another aspect is distributed architecture: very large graphs might need sharding or partitioning across multiple servers. Ensuring the agent’s queries run in a distributed manner without excessive overhead is complex. Some modern graph systems use distributed processing (Spark GraphX, etc.), but then latency can suffer.
In summary, teams need to anticipate that as the knowledge graph grows, they will need strategies for:
- Efficient data ingestion (perhaps streaming updates rather than batch rebuilds).
- Proper indexing of nodes/edges for the most frequent query patterns (like if your agent always looks up by a certain property, index that).
- Possibly layer the graph—e.g., keep a high-level abstraction graph for the agent to consult first (with aggregated or community nodes), and then deeper subgraphs for details.
- Monitoring query performance and tuning (adding cache, rewriting queries, denormalizing certain info into edge properties to avoid long traversals).
Additionally, security and access control can affect scalability. In an enterprise, not everyone/agent can see the whole graph. Applying access controls at query time can add overhead – some graph DBs support this natively (attribute-based access on nodes/edges), which must be configured carefully.
In short, scaling a knowledge graph to enterprise-grade size while keeping agent response times low is a major engineering challenge. Solutions involve using high-performance graph databases, clever data modeling, caching, and sometimes accepting trade-offs (maybe real-time graph updates are limited in scope or certain very expensive queries are disallowed). Starting with a subset or simpler schema implies that pragmatically, one might not mirror the entire universe in the KG at once, but rather incrementally expand it, ensuring that performance is managed at each stage. It’s a balance of ambition and practicality – the knowledge graph should be as comprehensive as needed, but not so massive or complex that it bogs down the agent.
Ontology and schema evolution
Another challenge with knowledge graphs, especially in dynamic business environments, is ontology and schema evolution. Designing the initial ontology/schema is hard enough, but over time, businesses change: new product lines, new organizational structures, new types of data to model. The KG’s schema needs to adapt without breaking the existing setup. This presents a challenge: it is essential for the graph to maintain flexibility; however, excessive free-form design may compromise consistency. Conversely, if the structure is overly rigid, it may struggle to adapt to changes effectively.
One aspect is governance vs. agility. Enterprises often set up data governance committees to oversee the ontology (to avoid chaos of everyone modeling things differently). This governance ensures consistency (like one canonical definition of “customer” entity, not five slightly different ones). However, governance can also slow down changes – if a new concept arises, it might need approval or lengthy discussions to incorporate. Meanwhile, an agentic AI might need that concept now. Finding the right balance – maybe a core ontology that’s tightly governed plus extension mechanisms for new stuff – is important.
Schema evolution might involve:
- Adding new entity types or relationship types.
- Changing definitions or constraints (say, a relationship that was one-to-one might become one-to-many).
- Merging or splitting classes (maybe what used to be one category needs to be split into two, e.g., splitting “Partner” into “Reseller” and “TechnologyPartner”).
Each of these can cause issues. If you add a new relation type but don’t backfill it on existing data, queries might miss relevant links. If you change a class hierarchy, some inference or queries might produce different results than before (affecting the agent’s behavior).
There’s a concept of schema drift – over time, if the ontology isn’t updated to reflect how people actually use the graph, queries become brittle. For example, if you query for “Vehicle” and later add “Drone” as a subclass of Vehicle, an ontology-driven system should still find Drones in that query without you rewriting it. This is great, but it requires designing the ontology with such reasoning in mind.
Another challenge is versioning. Some organizations maintain multiple versions of an ontology for backward compatibility – but an agent can’t easily juggle multiple schema versions at once. It generally needs one coherent view. So updates must be rolled out carefully.
ZBrain Builder’s context likely involves working with enterprises that have existing data schemas. They might have to map those to the knowledge graph ontology. If the enterprise changes its data model, the KG ontology may need to be updated accordingly. This requires coordination and perhaps migration of the KG data to the new schema (which can be non-trivial if the change is major).
Tooling support for evolving ontologies is still a developing area. Ideally, one wants ontology management systems that can suggest changes, highlight impacts, migrate data, etc. Without those, it’s often manual and error-prone.
Finally, governance is also about ensuring the ontology doesn’t degrade. In a free-for-all environment, different teams might add their own edges or nodes in whatever way, and soon the graph becomes inconsistent (e.g., two nodes that should be merged but aren’t, or an edge used in conflicting ways). Governance processes (or automated validation with something like Shapes Constraint Language (SHACL)) need to catch those.
In short, maintaining the ontology is a continuous task, not a one-time set-and-forget. Enterprises must plan for a dynamic knowledge graph that evolves with their business. This means dedicating effort to knowledge engineering: monitoring how the schema is used, updating it as new requirements come, and doing so in a controlled manner so agents don’t get confused by sudden changes. There’s also a cultural shift: people interacting with the graph (even indirectly via the agent) need to understand that it’s based on a model that might need updating when business concepts shift. For example, if “Customer” was modeled as an individual but now you have customer organizations, you must extend the schema – and ensure your agent queries take that into account.
To sum up, schema evolution is a challenge of balancing flexibility with governance. A schema that is too rigid becomes obsolete; one that is too loose becomes disorganized and inconsistent. Evolving it requires processes and perhaps smart ontology reasoning to minimize disruptions. Enterprises adopting knowledge graphs should be prepared to treat their ontology as a living asset, with dedicated owners, rather than a static diagram filed away. Done right, the ontology can adapt and continue to provide value; done poorly, it can become a bottleneck or source of confusion for the AI agents.
Data freshness and real-time updates
Knowledge graphs are only as useful as the information they contain – and in a fast-paced environment, ensuring the graph’s data is up to date and reflects current reality is a big challenge. Unlike an LLM’s training, which might be static for months, a knowledge graph is expected to update continuously: new facts added, old facts deprecated, changes applied as they happen. For agentic AI, this is crucial because the agent should rely on the KG for up-to-date knowledge. If the KG lags behind, the agent might give outdated recommendations (like referencing a policy that was changed last week or missing a newly hired employee in a workflow).
Continuous ingestion pipelines are needed to feed the KG. This could mean streaming data from databases, APIs, sensors, etc., into the graph as changes occur. For example, if a new support ticket is created, it should show up as a node/relationship in the KG immediately (or near-real-time) so the support agent AI knows about it. This can be technically complex: one might use change data capture on operational DBs to trigger KG updates, or periodic sync jobs. There’s always a risk of latency – maybe the KG is updated every hour for some data source, meaning within that hour the agent might not know something. Depending on the use case, that might or might not be acceptable.
ZBrain’s enterprise angle likely deals with data that is frequently changing (e.g., a sales pipeline KG will have deals moving stages daily). They must ensure their KG and vector indices are updated continuously – they probably have connectors to various data sources as part of their platform (indeed they list many integrations). Keeping the KG in sync might involve an update queue and ensuring no partial updates break the consistency (if two related edges must update together, that’s a concern).
Real-time update handling also means the agent should be able to ingest new information during operation. If mid-conversation, the user says “Actually, here’s new data,” the agent could insert that into the KG and then use it. But doing that on the fly requires fairly sophisticated orchestration (to ensure the LLM also knows to incorporate it).
Another challenge: removing stale or incorrect data. If something in the KG is wrong (perhaps a faulty sensor reported an incorrect reading, or an assumption was retracted), the graph needs an update or deletion. Agents should not keep using a fact that has been invalidated. Implementing a mechanism for that – maybe marking nodes/edges as deprecated or having the agent verify critical facts via an API call – might be necessary to maintain accuracy.
There’s a concept of graph decay: over time, if not curated, a KG can accumulate a lot of outdated facts which can mislead reasoning (e.g., an agent might see two different values for an entity’s status, one old, one new, if the old wasn’t removed). Policies for archiving or tagging old info are important. For example, an agent might prioritize facts with the latest timestamp.
Finally, the more real-time the KG, the more stress on systems. High-frequency updates (like IoT data every second) in a knowledge graph can be tough – many graphs aren’t optimized for constant writes at huge scale. In such cases, one might store raw streaming data elsewhere and only push summarized or important events to the KG (to avoid overload).
In summary, ensuring data freshness in the knowledge graph requires:
- Robust integration pipelines for continuous data flow.
- Mechanisms for temporal representation and querying.
- Strategies for expiring or updating stale data.
- Possibly rate-limiting or filtering updates to what the AI really needs to know, to balance load.
If done well, the agent always operates on the latest knowledge and can handle time-based queries (like “what changed since yesterday?”) elegantly. If done poorly, the KG might become a lagging reflection of the truth, reducing the agent’s effectiveness or even causing mistakes because it’s using outdated info. It’s an ongoing effort – essentially treating the KG like a live database that requires the same diligence as any critical data store in the enterprise.
Complexity and operational overhead
Using a knowledge graph alongside LLMs and other components introduces many moving parts, which can increase system complexity and operational overhead. Let’s break down some aspects:
Architecture complexity: Instead of just an LLM (which itself might be a managed API), you now have a graph database, a vector database, orchestration logic, data pipelines feeding the graph, etc. The overall system is more complex to design and build. Developers or engineers need expertise in multiple areas: NLP, graph modeling, database tuning, etc. Not every team has a graph expert on hand; there might be a learning curve to effectively engineer and query a knowledge graph. Proficiency in the relevant query language, such as SPARQL, Cypher, or an equivalent, is also required when working with the knowledge graph.
Operational load: Running a KG + vector DB + LLM orchestration means more infrastructure. Graph databases can be memory-heavy. Vector DBs might need GPUs or specialized indexes. LLM calls might be external and have to be managed. All of this must be orchestrated reliably. There’s overhead in monitoring each component’s performance, scaling them (e.g., if your knowledge graph grows, you might need to add more nodes to your graph DB cluster), and ensuring they all communicate properly. The system’s failure modes also multiply—if the graph DB goes down or lags, the agent might fail or return incomplete answers; if the sync pipeline breaks, KG data might become irrelevant.
Maintenance: Knowledge graphs and ontologies need maintenance, as discussed. That’s an ongoing overhead – someone (or a team) has to curate and update the graph and handle data quality issues. Vector database needs periodic re-embedding or cleaning of old vectors perhaps. The LLM prompts might need adjustment as knowledge is updated (though with function calling to KG, that’s more stable). So there’s a lot of “care and feeding” required for the integrated system versus a standalone AI model.
Integration effort: Integrating with existing enterprise systems can be a big project. To populate the knowledge graph, you may need to integrate with CRM, ERP, databases, etc. That means dealing with APIs, data cleaning, and possibly sensitive data (PII), which raises compliance concerns. Each integration has to be maintained if the source system changes. This is why products like ZBrain Builder position themselves as offering connectors out of the box – because doing it from scratch is effort-heavy.
Cost and performance trade-offs: More components can also mean more latency unless optimized. For example, an agent query might involve: call vector DB, call KG, then call LLM. Each hop adds latency. If not well-architected, this could slow responses. You might mitigate by caching some KG query results or pre-fetching, but that’s extra complexity. Also, running these components can be costly (graph DB licenses or cloud instances, vector DB hosting, etc.). For smaller-scale problems, a pure LLM solution (with caching of answers) might be cheaper and “good enough,” so one has to justify the additional cost/complexity of adding a KG.
Debugging: When the system produces a wrong answer, debugging it is now a multi-step ordeal – was the error because the KG had wrong data? Or because the LLM ignored the KG data? Or a vector retrieval missed something? It can take time to pinpoint where the pipeline failed. You might need specialized logging to trace what the agent did (ZBrain Builder emphasizes traceability, which helps here).
Security & access control: With multiple components, ensuring security is also more complex. The KG might have sensitive info, so you need access control at that layer (who or which agent can read what). Data pipelines need to handle permissions. The orchestration must ensure that, say, a marketing agent can’t see HR data if not allowed. Managing those permissions across the system is overhead and if misconfigured, can either block needed info (hobbling the agent) or leak data (strictly prohibited).
Expertise requirement: Not all organizations have data scientists or knowledge engineers familiar with knowledge graphs. They might have to acquire new talent or train existing staff, which is a non-trivial overhead. Without the right expertise, projects can falter in implementation.
ZBrain’s architectural approach as an orchestration platform is likely meant to hide some complexity (they provide the platform to manage these pieces). Even so, implementing it in an enterprise means someone has to configure the KG, load data, define an ontology, etc., which requires effort.
In summary, adding a knowledge graph and associated systems to AI introduces considerable system and organizational complexity:
- More components to build/monitor.
- Need for specialized knowledge.
- More complex data governance.
- Potentially higher costs.
Organizations must weigh these against the benefits. In many high-stakes or complex domains, the benefits (accuracy, context, compliance) far outweigh the overhead. This is not an instantaneous solution; it necessitates a sustained commitment to the upkeep of the knowledge infrastructure.
Latency trade-offs
Knowledge graphs, while improving reasoning and accuracy, can sometimes introduce additional latency compared to direct vector or LLM-only pipelines. Each graph query or traversal is an extra step that takes time, and if an agent has to do multiple hops or combine graph and vector queries, the overall response might slow down. In interactive applications, response speed is crucial for user experience.
For instance, a vector search might retrieve documents in, say, 100ms, whereas a SPARQL query on a huge KG might take 300ms, and a multi-hop traversal could take longer if not optimized. If the agent does one after the other, that adds up. Additionally, graph queries might not be as easily parallelizable as some vector searches.
Breaking tasks into multiple calls (e.g., when consulting a KG, calling an LLM, or calling an API) can introduce latency. Suggested mitigations are:
- Only invoke tools (like a KG query) when needed – i.e., if a direct response from the large language model is adequate, utilize it; consult the knowledge graph exclusively for complex scenarios. This implies that the system might have a heuristic or a classifier to decide whether the graph is needed.
- Parallelize where possible – perhaps query the vector DB and KG at the same time if they are independent, then merge results.
- Caching frequent graph query results – for example, cache the subgraph for a particular common entity so next time it’s immediate.
Another idea is layered retrieval: maybe use a quick vector search to narrow down a relevant part of the KG (like identify relevant entities) and then only traverse that small part of the graph, rather than searching the whole graph.
Memory constraints: LLM context windows can also cause latency if overstuffed. Graph RAG tends to reduce context size by providing only succinct relevant facts, which ironically can reduce latency by shortening the prompt (fewer tokens to process). In that sense, adding a graph step can save time if it eliminates the need to push 10 documents into the prompt.
However, if the graph queries themselves are slow, it could bottleneck. That’s why caching is stressed. If the agent frequently asks similar questions (like “who is Bob’s manager?”), caching the answer avoids hitting the graph DB repeatedly. Also, some graph DBs allow keeping certain subgraphs in memory for fast access.
Another trade-off: sometimes, instead of doing a fancy multi-hop query at query time (which is slow), you can precompute certain connections offline and store them as direct relationships. E.g., if queries often ask “how is A connected to C?”, you might precompute a property or node that represents that connection. Essentially, trading storage/preprocessing for query speed.
The complexity of the query matters too. A 1-hop lookup (find a node by ID, get an attribute) is usually extremely fast. A complex pattern match (“find all X such that X has relation1 to something that has relation2 to Y”) might be slower. If the agent’s typical queries are simple, the latency from KG is negligible. If they require deep reasoning, you may have to accept some delay or redesign the approach (maybe break it into steps, each manageable, as the agent can do iterative queries).
In high-frequency or real-time scenarios, an LLM+KG approach might be too slow entirely – that’s not usually where you’d apply an agentic AI, though, at least not in the critical path.
So the strategies include:
- Use KG when necessary (don’t do needless graph ops).
- Optimize graph queries (indexes, limit traversal depth as ZBrain Builder suggests).
- Parallelize (utilize concurrency for independent fetches).
- Cache results (with appropriate TTLs to avoid stale data issues).
- Possibly maintain a simplified summary of the KG for quick lookups (like how ZBrain clusters and summarizes communities, so broad queries hit summary rather than raw graph).
- Scale infrastructure: ensure the graph DB is well-resourced or use in-memory graph engines if needed.
In conclusion, while knowledge graphs add another step that can increase latency, careful system design (caching, parallelizing, limiting expensive operations) can mitigate this. It’s a trade-off between the richness of reasoning vs. speed. Enterprises often will accept slightly higher latency for far better answers, up to a point. As technology and implementations improve, the latency penalty is shrinking. Still, developers of agentic AI need to be mindful not to let the pipeline get so slow that it hinders adoption – hence all the best practices ZBrain Builder and others mention about smart tool use and caching. Ultimately, the goal is to achieve real-time or near-real-time agent responses with the added intelligence the KG provides, and that’s feasible with the right engineering and resources.
Conclusion
Agentic AI marks a new era of autonomy—where AI systems can plan, reason, and act independently. Yet, large language models alone can’t deliver this intelligence. They lack persistence, structure, and verifiable context. Knowledge Graphs fill this gap, providing the long-term memory, context anchoring, and logical framework needed to transform reactive models into proactive, reasoning agents.
For enterprises, this isn’t theoretical—it’s foundational. Knowledge Graphs ensure accuracy, transparency, and continuity across intelligent workflows, enabling AI that truly understands and evolves with business context. While they add engineering complexity, the reward is scalable, trustworthy AI that reasons like a domain expert.
ZBrain Builder embodies this hybrid vision—merging LLMs with Knowledge Graphs to deliver contextual, explainable, and collaborative Agentic AI systems. As organizations build toward autonomous systems, investing in structured knowledge is no longer optional—it’s what will define the next generation of enterprise intelligence.
Evolve your LLMs into agents capable of structured reasoning and task execution. Book a demo and explore how ZBrain Builder operationalizes Knowledge Graphs for enterprise-ready Agentic AI systems.
Listen to the article
Author’s Bio


CEO LeewayHertz
An early adopter of emerging technologies, Akash leads innovation in AI, driving transformative solutions that enhance business operations. With his entrepreneurial spirit, technical acumen and passion for AI, Akash continues to explore new horizons, empowering businesses with solutions that enable seamless automation, intelligent decision-making, and next-generation digital experiences.
Table of content
- Why agentic AI needs knowledge graphs
- Anatomy of knowledge graphs in agentic AI
- Knowledge graphs as the backbone of agentic AI architectures
- Integration patterns: KGs + LLMs + agent frameworks
- ZBrain Builder’s context: Operationalizing knowledge graphs for AI agents
- Challenges and limitations of implementing knowledge graphs for agentic AI
Share Article


Frequently Asked Questions
What is a Knowledge Graph, and how is it different from a database?
A Knowledge Graph (KG) represents information as interconnected entities (nodes) and relationships (edges), forming a semantic network of knowledge. Unlike traditional databases that store data in tables, KGs encode meaning and context — showing how concepts relate to one another.
For example, a relational database might store user and product data separately, while a KG can express that “User A purchased Product B, which belongs to Category C.”
This structure enables reasoning, inference, and multi-hop queries — making KGs ideal for agentic AI systems that need contextual understanding and logical reasoning.
Why are Knowledge Graphs critical for agentic AI systems?
Agentic AI involves autonomous systems capable of planning, reasoning, and acting toward goals. To do this effectively, agents need long-term memory and contextual awareness — two capabilities that traditional LLMs lack.
Knowledge Graphs provide this foundation by serving as a persistent, structured memory layer. They enable agents to recall past interactions, disambiguate entities (e.g., “Apple” as company vs. fruit), and connect related information through reasoning chains. This structured knowledge helps reduce hallucinations and ensures factual accuracy in AI-driven decisions.
How do Knowledge Graphs complement Large Language Models (LLMs)?
LLMs excel at understanding and generating natural language but struggle with precision and memory persistence. Knowledge Graphs, on the other hand, specialize in structured reasoning and factual recall.
Together, they form a hybrid architecture:
-
The LLM interprets, generates, and communicates naturally.
-
The KG grounds those responses in verified, structured data.
This combination—referred to as Graph-RAG (Graph-based Retrieval-Augmented Generation)—ensures that outputs are both fluent and factually anchored.
How does ZBrain Builder integrates KG in the solutions built on it?
In ZBrain Builder, Knowledge Graphs form part of the structured memory layer that powers both Flows and AI agents.
ZBrain Builder integrates KGs alongside vector indices, allowing hybrid retrieval:
-
Vector stores handle unstructured semantic search (e.g., similarity-based queries).
-
Knowledge Graphs handle structured reasoning (e.g., entity relationships, hierarchies, or dependencies).
This dual-layer retrieval enables ZBrain’s agents to answer complex enterprise questions with precision.
What are the key components of a Knowledge Graph in agentic AI systems?
A typical Knowledge Graph in ZBrain Builder or similar platforms includes:
-
Nodes: Represent entities like users, products, policies, or documents.
-
Edges: Represent relationships (e.g., belongsTo, dependsOn, authoredBy).
-
Attributes: Metadata such as timestamps.
-
Ontologies and schemas: Define the rules and structure of how entities relate, ensuring domain consistency.
Together, these components enable semantic queries and reasoning, forming the cognitive layer for intelligent agents.
What benefits do Knowledge Graphs bring to enterprise AI beyond reasoning?
For enterprises, KGs provide several strategic advantages:
-
Data unification: Integrates fragmented data sources under a single semantic model.
-
Explainability: Every inference is traceable through the graph structure, supporting AI transparency.
-
Collaboration: Serves as a shared knowledge base for multiple AI agents and human teams.
-
Governance: Incorporates metadata for permissions, lineage, and data quality management.
By combining reasoning and governance, KGs help enterprises operationalize trustworthy AI.
How do multi-agent systems leverage shared Knowledge Graphs?
In multi-agent (“Agent Crew”) architectures, a shared Knowledge Graph acts as the coordination center.
Each agent—whether specialized in compliance, analytics, or automation—can read from the same KG, ensuring consistent context across all operations. For example, one agent might extract new policy data, another might generate compliance summaries—all using the same shared graph.
This synchronized memory enables scalable, cooperative intelligence across enterprise workflows.
What challenges exist in maintaining enterprise Knowledge Graphs?
Common challenges include:
-
Ontology evolution: Keeping schemas relevant as business domains change.
-
Data freshness: Continuously syncing new information without breaking existing relations.
-
Scalability: Managing millions of edges while maintaining low-latency queries.
-
Operational overhead: Integrating graph storage, vector databases, and LLMs cohesively.
Platforms like ZBrain Builder mitigate these issues through governed updates, automated ingestion pipelines, and visual graph management tools for maintenance and debugging.
How should enterprises prepare for adopting Knowledge Graphs in agentic AI?
Enterprises should approach KGs as strategic assets, not just data models. Recommended steps include:
-
Define ontology early: Capture entities and relationships aligned with business goals.
-
Integrate gradually: Start by connecting key data systems (CRM, ERP, documents) to the KG.
-
Adopt a hybrid retrieval approach: Combine structured KG reasoning with unstructured semantic search.
-
Govern proactively: Enforce access controls, versioning, and data lineage tracking.
ZBrain Builder simplifies this adoption through its knowledge base creation tools, schema management, and seamless integration between LLMs, KGs, and workflows, allowing enterprises to operationalize agentic AI efficiently.
How do we get started with ZBrain for AI development?
To begin your AI journey with ZBrain:
-
Contact us at hello@zbrain.ai
-
Or fill out the inquiry form on zbrain.ai
Our dedicated team will work with you to evaluate your current AI development environment, identify key opportunities for AI integration, and design a customized pilot plan tailored to your organization’s goals.
Insights
A guide to intranet search engine
Effective intranet search is a cornerstone of the modern digital workplace, enabling employees to find trusted information quickly and work with greater confidence.

Enterprise knowledge management guide
Enterprise knowledge management enables organizations to capture, organize, and activate knowledge across systems, teams, and workflows—ensuring the right information reaches the right people at the right time.
Company knowledge base: Why it matters and how it is evolving
A centralized company knowledge base is no longer a “nice-to-have” – it’s essential infrastructure. A knowledge base serves as a single source of truth: a unified repository where documentation, FAQs, manuals, project notes, institutional knowledge, and expert insights can reside and be easily accessed.
How agentic AI and intelligent ITSM are redefining IT operations management
Agentic AI marks the next major evolution in enterprise automation, moving beyond systems that merely respond to commands toward AI that can perceive, reason, act and improve autonomously.

What is an enterprise search engine? A guide to AI-powered information access
An enterprise search engine is a specialized software that enables users to securely search and retrieve information from across an organization’s internal data sources and systems.
A comprehensive guide to AgentOps: Scope, core practices, key challenges, trends, and ZBrain implementation
AgentOps (agent operations) is the emerging discipline that defines how organizations build, observe and manage the lifecycle of autonomous AI agents.
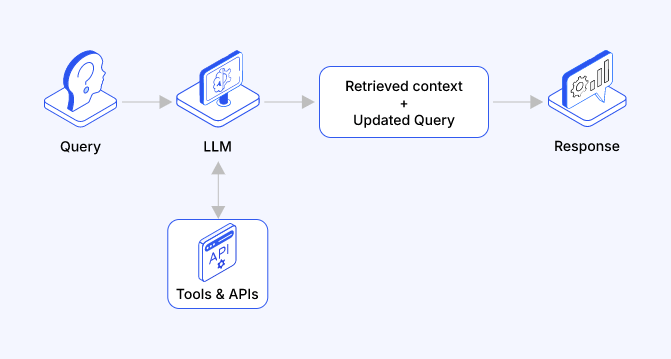
Adaptive RAG in ZBrain: Architecting intelligent, context-aware retrieval for enterprise AI
Adaptive Retrieval-Augmented Generation refers to a class of techniques and systems that dynamically decide whether or not to retrieve external information for a given query.
How ZBrain breaks the trade-offs in the AI iron triangle
ZBrain’s architecture directly challenges the conventional AI trade-off model—the notion that enhancing one aspect inevitably compromises another.
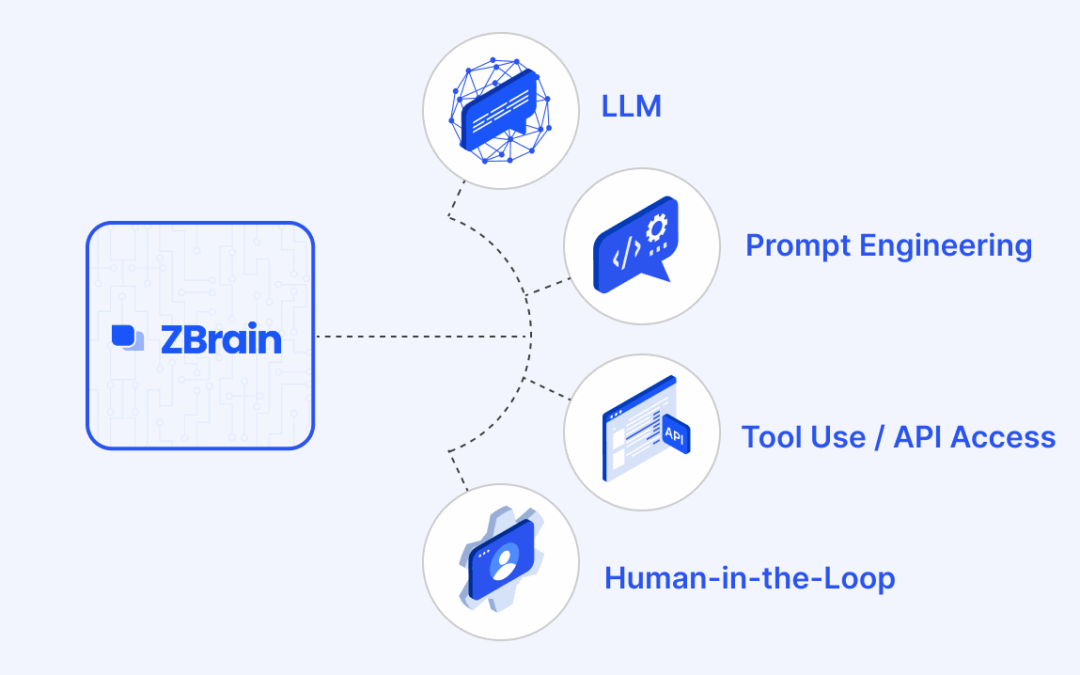
ZBrain Builder’s AI adaptive stack: Built to evolve intelligent systems with accuracy and scale
ZBrain Builder’s AI adaptive stack provides the foundation for a modular, intelligent infrastructure that empowers enterprises to evolve, integrate, and scale AI with confidence.
