


How ZBrain enhances knowledge retrieval with intelligent reranking

Listen to the article
Enterprise search systems, which enable employees to locate information across internal documents, databases, and communications, often struggle to deliver relevant and precise results for user queries. Traditional enterprise search engines, based on keyword matching or static ranking algorithms, frequently return a flood of results, leaving users to sift through numerous irrelevant items to find what they need. The challenge is exacerbated by the prevalence of unstructured data in organizations (such as emails, reports, and wikis) and the nuanced way users pose questions in natural language. These shortcomings underscore the need for more context-aware and intelligent retrieval methods to enhance search quality.
One promising solution is reranking, the process of refining and re-ordering an initial set of search results to boost relevance. Instead of relying solely on the first-pass search (which might be a text keyword search or a semantic vector search), a reranking stage applies deeper linguistic and contextual analysis to identify which results truly answer the user’s query. This second-stage ranking is critical for accuracy and context-awareness: it ensures that the top results are not just somewhat related to the query, but are the most relevant and useful to the user’s intent. As NVIDIA observes, “re-ranking has emerged as a pivotal technique to enhance the precision and relevance of enterprise search results” (Enhancing RAG Pipelines with Re-Ranking | NVIDIA Technical Blog) by using neural relevance models to align results with the user’s true intent and context. In practice, reranking can dramatically improve search effectiveness, turning a list of vaguely related documents into a focused set of answers.
This article examines how ZBrain Builder leverages intelligent rerankers to enhance the precision and relevance of enterprise search. We will explore the technology behind reranking, examine its benefits in addressing the challenges of traditional search systems, and discuss practical considerations for its implementation. By the end of the article, readers will understand how advanced reranking methods enhance the precision and relevance of search results and empower organizations to harness their internal knowledge more effectively.
- What is a reranker?
- How reranking works in ZBrain’s search pipeline
- ZBrain’s RAG-integrated workflow
- How to build a ZBrain application with integrated reranking?
- How to optimize document retrieval before reranking using the knowledge base creation wizard?
- The road ahead: Smarter, adaptive, and hybrid re‑ranking
What is a reranker?

Re-ranking is a secondary stage in the search pipeline that refines initial results for higher accuracy and relevance. In today’s enterprise environments, where users demand precise answers from vast, unstructured data, rerankers ensure the top results truly match user intent. By leveraging AI models that understand context and semantics, reranking bridges the gap between broad recall and focused precision, making search faster, smarter and more helpful.
Before diving deeper, it’s important to clarify a few key concepts:
-
Enterprise search: The technology and practice of searching through an organization’s internal data repositories (documents, intranet pages, emails, databases) to retrieve information for users. Enterprise search solutions must handle diverse data types, security controls, and domain-specific language.
-
Vector retrieval: A modern search technique that uses numerical embeddings (vector representations of text) to find relevant documents based on semantic similarity rather than exact keyword matches. For example, a query and a document can be converted into high-dimensional vectors, and relevance is measured by the closeness of these vectors (using metrics like cosine similarity).
-
Re‑ranking: A secondary retrieval step that takes an initial list of results and re‑orders (or filters) them using more sophisticated analysis. Typically, a re‑ranker uses an AI model to read each candidate result in the context of the query and assign a new relevance score, thus promoting or demoting items based on a deeper understanding.
Several industry trends have converged to make re‑ranking especially pertinent now:
-
AI‑driven semantic search: Companies are increasingly adopting AI for search, using techniques like natural language processing and vector embeddings to go beyond keyword matching. This semantic approach increases recall of relevant items but also demands better ranking to sort true matches from loosely related content.
-
Context‑aware retrieval: Modern search and question‑answering systems consider context (such as the user’s role, preferences, or the context of a conversation) to deliver results that are tailored and precise. Simple one‑size‑fits‑all ranking is giving way to context‑sensitive retrieval that can discern what a user really means.
-
Retrieval-Augmented Generation (RAG): A fast-growing trend is emerging to integrate search with large language models to generate answers backed by retrieved data. In RAG pipelines, the quality of the final answer depends directly on the relevance of the retrieved supporting documents. Reranking bridges the gap between raw retrieval and accurate generation, enhancing both search result pages and AI-driven Q&A experiences.
Examples of reranker solutions
-
Voyage AI re‑ranker: A lightweight transformer cross‑encoder fine‑tuned to judge query–document relevance in enterprise contexts, balancing speed and precision.
-
Cohere rerank: A specialized API that ranks searched passages by scoring their alignment with the query, ideal for augmenting vector-based retrieval.
-
OpenAI reranker: An embedding‑based reranking endpoint that refines search outputs via a trained ranking model, often used alongside their semantic search offering.
-
Microsoft Turing Reranker: Part of Azure Cognitive Search, this model uses the Turing family of transformers to re‑score results for relevance.
-
Pinecone smart rerank plugin: Adds a transformer‑based reranking layer on top of your Pinecone index, boosting precision for top‑k retrieval.
-
Elasticsearch query rescorer: An add-on that lets you plug in a neural model (e.g., BERT) to rescore the top results of a keyword search, combining BM25 recall with AI precision.
These examples illustrate how various vendors offer reranking modules, each leveraging cross-encoders or similar architectures, to transform a rough retrieval pass into a pinpoint, context-aware result set.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
How reranking works in ZBrain’s search pipeline
Enterprise search in ZBrain Builder is a two-stage process: an initial retrieval stage surfaces searched results, followed by a re-ranking step that refines these results for optimal semantic relevance.
Model-agnostic integration
ZBrain’s reranking layer is architected with model agnosticism at its core, enabling seamless integration with a broad spectrum of reranker models. This flexibility allows teams to tailor the reranking stage to specific performance targets, content types, and enterprise needs.
The effectiveness of this layer depends on the characteristics of the chosen model. For example, when a transformer-based cross-encoder is used, where the query and retrieved item are jointly encoded, the system can perform deep semantic matching that captures subtle contextual cues. This enables a more accurate and relevance-driven ordering of retrieved results, especially in complex search scenarios.
Capabilities
When equipped with modern cross-encoder models, ZBrain’s reranking module can support:
|
Capability |
Description |
|---|---|
|
Joint encoding |
Simultaneous processing of query and retrieved item for higher semantic accuracy. |
|
Fine-grained semantic matching |
Captures deep semantic relationships and contextual nuances that simpler models may miss. |
|
Token-level attention |
Uses attention across all tokens in both query and document, enabling more precise relevance judgments. |
|
Support for long input sequences |
Accommodates lengthy documents and complex queries, depending on the model’s max token limit |
|
Multilingual comprehension |
Understands and scores content in multiple languages, assuming the model was trained on multilingual data. |
|
Contextual disambiguation |
Differentiates meaning based on context |
This reranking setup ensures ZBrain remains adaptable to the evolving landscape of retrieval models, enabling enterprises to adopt the latest innovations without being locked into a specific provider.
ZBrain’s reranking workflow
- Retrieve: Top K candidates are fetched from the first-stage retriever (e.g., keyword or vector-based).
- Batch: Searched items are paired with the user query.
- Rerank: These pairs are sent to the configured cross-encoder endpoint over TLS.
- Sort: Returned scores are used to reorder the candidates by semantic relevance.
Strategic value
By abstracting the reranker behind a standard API, ZBrain delivers:
- High precision: Deep contextual understanding of each query-result pair.
- Scalability: Efficient batch processing and latency-optimized variants support enterprise throughput.
- Future-proofing: Ability to plug in new or improved rerankers as they emerge.
- Operational simplicity: Seamless integration with external reranking models—no need to manage hosting or infrastructure.
ZBrain’s RAG-integrated workflow
Understanding how reranking fits into ZBrain’s larger search pipeline is key to appreciating its architectural value. ZBrain employs a retrieval-augmented architecture to orchestrate the interaction between its search components. Here is how a typical query flows through ZBrain’s system:
- Initial retrieval via vector database: When a user submits a search query (for example, “Find guidelines on data retention policy”), ZBrain first converts the query text into a vector embedding. This embedding is used to query a vector database that indexes the organization’s content, where each document or passage is stored with a pre-computed embedding. The vector database rapidly returns the top K candidate documents that are closest to the query vector in the embedding space. This is an efficient first pass that yields a manageable set of plausible results out of potentially millions of documents. The similarity measure is typically cosine similarity on the embeddings, which is computationally cheap to compute. At this stage, we prioritize recall – capturing anything that might be relevant.
- Reranking stage: The top retrieved results are then passed to ZBrain’s reranker module for a second-stage evaluation. The reranking system takes each result and the original query text as input. For each pair, it computes a relevance score as discussed earlier. This is a more computationally expensive step than the initial retrieval (since a transformer model is applied), but because it’s only applied to a limited number of results, it remains feasible in an interactive setting. The reranker then produces a reordered list, typically prioritizing a subset (e.g., the top 5 or 10 with the highest scores). Less relevant results from the initial set may be demoted or even filtered out entirely if their scores fall below a defined threshold. This step ensures that only high-quality, contextually relevant content is retained.
- Integration with the RAG Pipeline: After reranking, the refined result set is integrated into ZBrain’s Retrieval-Augmented Generation (RAG) pipeline for the final stage. In modern enterprise search applications—especially those evolving into conversational assistants or question-answering systems—this stage typically involves a generative AI component. In ZBrain’s architecture, a generative LLM (such as an advanced GPT-based model) takes the top reranked results as context. The RAG orchestrator feeds the LLM with both the query and the supporting content, enabling the model to generate a precise answer or summary grounded in the enterprise’s actual data.
In traditional search interfaces, this stage may involve presenting the reranked results directly to the user, ordered by relevance. Increasingly, however, this is coupled with an answer snippet or synthesized response generated by the LLM. In either case, the user benefits from immediate access to the most pertinent information. As a whole, this pipeline exemplifies retrieval-augmented generation in action: retrieve, rerank, and generate.
How to build a ZBrain application with integrated reranking?
To set up a ZBrain application with reranking capabilities, follow these steps:
Create a new app

Go to ZBrain’s Apps page, choose Create an App, then select your App Type, App Access Type, and Orchestration Method (Knowledge Base or Flow).

Configure the bot
- If you are using a Knowledge Base, select the one from which you want to retrieve information.
- Enable Advanced Reasoning by checking the box.
- Enter your system instructions.

Add a reranker:
- Click Edit under Manual Configuration.
- In the Reranking Model dropdown, select the AI re‑ranker that best fits your requirements.
With these steps, your ZBrain app will seamlessly integrate reranking for context‑aware, highly relevant search experiences.


Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
How to optimize document retrieval before reranking using the knowledge base creation wizard?
ZBrain puts key re‑ranking controls right at your fingertips in the Data Refinement Tuning step during knowledge base creation. Here’s how each setting shapes the two‑stage retrieval + rerank process:

- Search mode selection
- Vector search (default): Runs your chosen embedding model against the vector index and then hands the top candidates off to the reranker.
- Hybrid search: Executes both vector and full‑text lookups in parallel, then invokes the re‑rank API to choose the best matches.
Choosing between pure vector or hybrid ensures you can optimize for semantic recall or precise term‑matching before reranking.
- Top K slider
- Controls the number of initial candidates sent into the rerank stage.
- Example:
- 50 for broad recall (captures more potential hits)
- 20 for speed (limits transformer calls)
Adjusting Top K directly trades off recall vs. re‑rank latency.
- Score threshold toggle and slider
- When enabled, any candidate scoring below your cutoff (0–1 scale) is filtered out before the results are displayed to users.
- Example: Setting a 0.7 threshold means only highly confident, re‑ranked documents surface.
This prevents borderline or noisy matches from slipping into top results.
- Embedding model dropdown
- Select from available text‑embedding models (e.g.,
text‑embedding‑3‑largeor your custom enterprise model). - Swapping models allows you to balance domain accuracy, inference cost, and performance.
Different embeddings can significantly impact which results the reranker considers top candidates.
- Select from available text‑embedding models (e.g.,
By configuring these four UI controls—search mode, Top K, score threshold, and embedding model—you directly steer ZBrain’s re‑ranking behavior. No code required: tweak sliders and dropdowns to dial in the perfect balance of recall, precision, and speed for your enterprise search workloads.
The road ahead: Smarter, adaptive, and hybrid re‑ranking
The landscape of AI and search is evolving rapidly, and modern re‑ranking systems are being designed with a forward‑looking approach to stay ahead of user needs. Ongoing R&D efforts and user feedback drive continuous improvement. Here are some areas that advanced reranking capabilities could potentially enhance in the future:
Adaptive re‑ranking
Today’s re‑ranking models often treat each query independently with a static, pre‑trained model. The next step is to make re‑ranking more adaptive, learning from each interaction. This could involve:
- Online learning, where the model updates its understanding in real time based on user clicks, selections, or corrections.
- Reinforcement learning, adjusting ranking policies dynamically to reward results that users consistently prefer.
An adaptive re‑ranker might notice that a particular user favors certain document types or that specific query patterns benefit from different weighting, and then personalize orderings on the fly. While continuous learning must be managed to prevent drift or unintended bias, when done correctly, it allows search relevance to improve automatically with usage.
Hybrid models and multimodal ranking
Future systems will increasingly blend multiple techniques to cover the full spectrum of enterprise data:
- Keyword + neural fusion: Combining classic term‑based rankers (like BM25) with neural re‑rankers in parallel, then merging their outputs to ensure exact keyword matches aren’t lost amid semantic scores.
- Multimodal retrieval: Extending beyond text to handle images, diagrams, video transcripts, or structured tables. Vision-language models and knowledge-graph reasoning can enhance documents that contain relevant visuals or represent authoritative relationships.
These hybrid strategies help capture edge cases that any single model might miss, delivering a more robust and comprehensive search experience.
More advanced transformer models
As transformer‑based architectures continue to evolve, re‑ranking engines will incorporate newer, more capable models:
- Instruction‑tuned LLMs: Using prompt‑based approaches where a large language model is asked, “Rate how well these snippets answer this question,” enabling zero‑shot or few‑shot re‑ranking for complex queries.
- Model distillation: Compressing insights from very large models into smaller, efficient cross‑encoders that run at low latency while retaining much of the bigger model’s nuance.
- Modular integration: Maintaining a plug‑and‑play architecture so that when a next‑generation multilingual or domain‑specialized transformer proves its worth, it can be swapped in seamlessly.
By staying agnostic to cloud platforms and model providers, these systems can continuously evaluate and adopt state‑of‑the‑art retrieval models as they emerge.
Continuous feedback loops
Robust feedback pipelines are key to keeping re‑rankers sharp:
- Usage monitoring: Tracking metrics such as precision@K, click‑through rates, and downstream task success on an ongoing basis.
- Automated evaluation: Running regular validation checks on a representative query set and triggering alerts or retraining when performance dips.
- Ground‑truth enrichment: Incorporating new relevance judgments—from explicit user feedback, support‑ticket resolutions, or periodic annotation efforts—into offline and online training cycles.
Automation of these processes ensures that the re‑ranking model adapts not only to new data but also to evolving user expectations and document collections.
Looking ahead: Metacognitive re‑ranking
Longer term, re‑rankers may develop “self‑awareness” about their own limitations. For instance, a system could detect when none of the retrieved documents sufficiently answer a novel or niche query and either broaden the search scope or prompt content creators to generate new resources. By blurring the lines between retrieval and reasoning, such intelligent behaviors will form the next frontier of enterprise search intelligence.
In sum, the future of reranking lies in making systems more adaptive, hybrid, and self‑improving, ensuring that as enterprise data grows in volume and variety, users continue to receive the most relevant, context‑aware answers right when they need them.
Endnote
ZBrain’s reranking mechanism represents a strategic leap in the quality of enterprise search. By injecting a sophisticated AI-driven ranking stage into the search pipeline, ZBrain ensures that users are presented with results that are not only relevant in theory but precise and contextually on-point in practice. The architectural choice to employ a reranker, backed by transformer models and deep semantic analysis, means that the search experience evolves from basic keyword matching to an intelligent dialogue between the user’s query and the organization’s knowledge.
From a technology leadership perspective, this capability translates into tangible benefits. Employees and end-users can find information faster and with greater confidence, leading to improved productivity and informed decision-making. The integration of reranking into an RAG pipeline further means that the enterprise is well-prepared for the future of AI. Whether users interact via a traditional search box or a chat-based assistant, the underlying system can retrieve authoritative information and provide verified answers. The modular, two-stage retrieval architecture is not just about improving one query – it’s a scalable system that can adapt to an enterprise’s growth and learning.
The reranking feature of ZBrain significantly enhances the relevance of enterprise search results, serving as an intelligent gatekeeper between a user’s query and the wealth of corporate data. It exemplifies how modern AI techniques, such as transformers and RAG, can be harnessed in a practical and impactful way. Enterprises adopting this technology gain a competitive advantage in knowledge management, as employees trust the search to provide them with accurate information quickly, and the organization gains insights into what information is most frequently sought after. Ultimately, ZBrain’s enhanced reranking capability leads to higher end-user satisfaction and unlocks more value from enterprise data, making search not a bottleneck, but a catalyst for productivity and innovation.
Explore how intelligent reranking can elevate your enterprise search—start building smarter workflows with ZBrain today.
Listen to the article
Author’s Bio


CEO LeewayHertz
An early adopter of emerging technologies, Akash leads innovation in AI, driving transformative solutions that enhance business operations. With his entrepreneurial spirit, technical acumen and passion for AI, Akash continues to explore new horizons, empowering businesses with solutions that enable seamless automation, intelligent decision-making, and next-generation digital experiences.
Table of content
- What is a reranker?
- How reranking works in ZBrain’s search pipeline
- ZBrain’s RAG-integrated workflow
- How to build a ZBrain application with integrated reranking?
- How to optimize document retrieval before reranking using the knowledge base creation wizard?
- The road ahead: Smarter, adaptive, and hybrid re‑ranking
Share Article


What is reranking?
Reranking is a second-stage process in the enterprise search pipeline that refines the results returned by the initial retrieval system. After a broad set of potentially relevant results is fetched—using keyword matching, vector similarity, or hybrid methods—a more advanced AI model (typically a transformer-based cross-encoder) re-evaluates each result in the context of the user’s query. It then reorders or filters the list to ensure the most relevant, context-aware results appear at the top. This significantly improves precision, reduces noise, and enables users to access the right information faster, particularly in environments with large, unstructured, or domain-specific content.
Why is reranking important?
First‑pass search often returns many marginally related items. Reranking utilizes contextual and semantic analysis to prioritize the most relevant documents, thereby reducing noise and enabling users to find the information they need more quickly.
How does ZBrain implement reranking?
ZBrain uses a two-stage retrieval approach to enhance the accuracy of enterprise search. In the first stage, it performs a vector-based search to retrieve a broad set of potentially relevant results based on semantic similarity to the user’s query. These top results are then passed to a reranker via API.
The reranker acts like a smart evaluator, analyzing each query-document pair together to consider the full context and nuances of language, and assigning a new relevance score to each item. These scores reflect how well each result truly answers the user’s query, not just whether it contains similar words or concepts.
ZBrain then uses these scores to reorder the results, ensuring the most relevant and meaningful content appears at the top. This reranking process significantly enhances search precision, making it easier for users to quickly find the information they need, even in complex and unstructured data environments.
What business challenge does ZBrain’s reranking solve?
In many enterprises, traditional search systems struggle to surface the most relevant information, often returning a flood of loosely related results. This forces users to spend valuable time sorting through irrelevant content, which slows decision-making and reduces efficiency.
ZBrain addresses this challenge with a two-stage search pipeline: it first retrieves a broad set of results using vector-based semantic search, then applies advanced reranking through a reranking model to evaluate and reorder results based on true contextual relevance. This ensures that users see the most accurate, intent-matching results at the top, streamlining information access, improving productivity, and enhancing overall search satisfaction.
How does re‑ranking fit into an RAG pipeline?
In a Retrieval-Augmented Generation (RAG) pipeline, the effectiveness of the final LLM-generated response heavily depends on the quality of the retrieved context. If irrelevant or loosely related documents are passed to the LLM, the output can become vague or misleading.
ZBrain enhances this process by inserting a reranking stage between retrieval and generation. After the initial semantic search retrieves a broad set of documents, ZBrain uses a reranker to evaluate and prioritize the most relevant ones. Only the top, high-precision snippets are then passed to the LLM, ensuring that the generated answers, whether for chatbots, summaries, or reports, are grounded in the most accurate and contextually relevant information.
How do we get started with ZBrain for AI development?
To begin your AI journey with ZBrain:
-
Contact us at hello@zbrain.ai
-
Or fill out the inquiry form on zbrain.ai
Our dedicated team will work with you to evaluate your current AI development environment, identify key opportunities for AI integration, and design a customized pilot plan tailored to your organization’s goals.
Insights
Loop Engineering for AI Agents: Building Reliable Autonomous Systems
Loop engineering is the practice of designing, operating, and improving the feedback systems that let an AI agent plan, act, observe the results, and revise its approach until a goal is reached without a human driving every turn.
The AI Trust Gap: Why Governance Architecture Determines Enterprise Value
The trust gap surrounding enterprise AI is fundamentally an architectural challenge, and its solution is increasingly well understood.
The AI ROI illusion: Why enterprises struggle to measure AI impact
Organizations with stronger measurement discipline are better positioned to link AI deployments to measurable business outcomes, prioritize high-impact use cases across the enterprise, allocate capital more effectively, and continuously refine models using real-world performance feedback.
The agentic enterprise: Why AI success requires an operating model redesign
Organizations that redesign their operating models around agentic AI are beginning to outperform those that apply AI only incrementally.
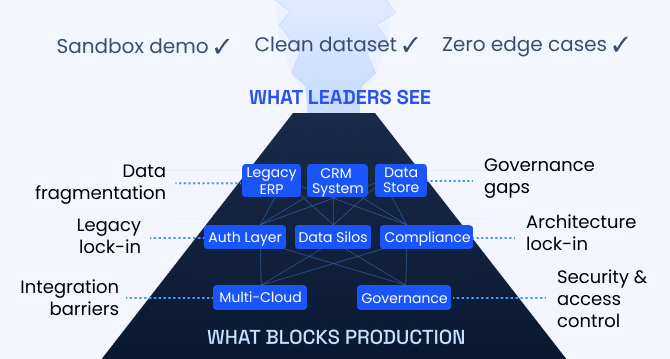
Enterprise AI pilot-to-production gap: Root causes & how to address them
The underlying cause is structural. In many enterprises, AI pilots are developed on infrastructure that was not designed to support production deployment.
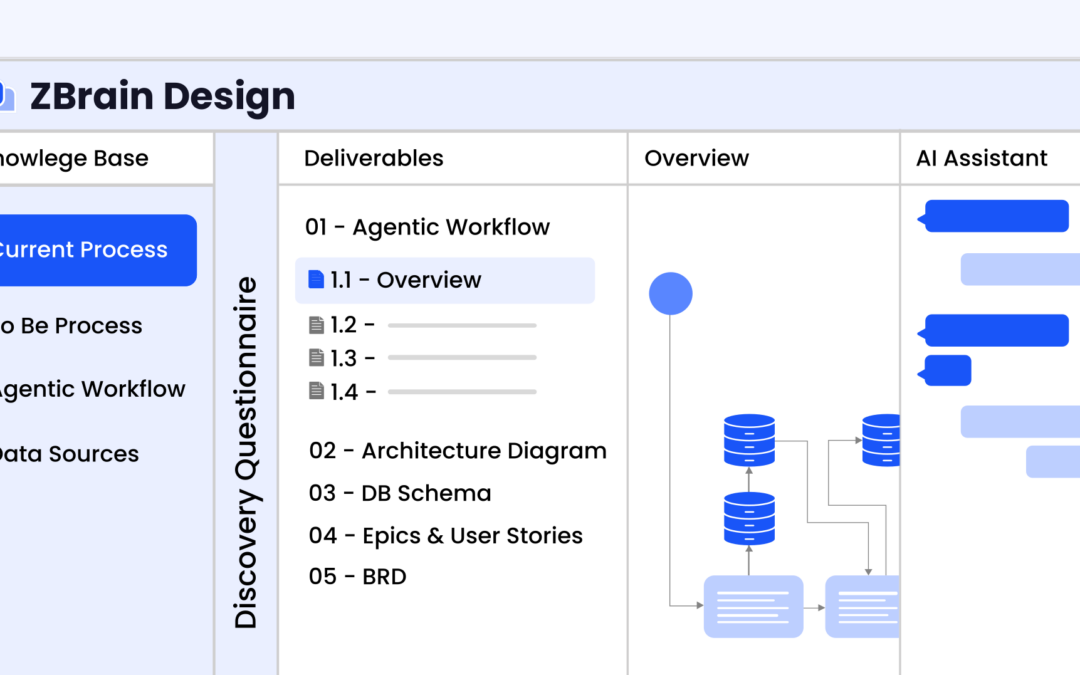
Solution architecture best practices: A guide for enterprise teams
The architecture design process culminates in a set of documented artifacts that communicate the solution to development, operations, and business teams.

Common solution architecture design challenges and solutions
Solution architecture must evolve from fragmented documentation practices to a structured, collaborative, and continuously validated design capability.

Why structured architecture design is the foundation of scalable enterprise systems
Structured architecture design guides enterprises from requirements to build-ready blueprints. Learn key principles, scalability gains, and TechBrain’s approach.
Intranet search engine guide: How it works, use cases, challenges, strategies and future trends
Effective intranet search is a cornerstone of the modern digital workplace, enabling employees to find trusted information quickly and work with greater confidence.
