


Agent scaffolding explained: The architecture behind reliable, autonomous AI agents

Listen to the article
As enterprises begin to operationalize large language models, the gap between the capabilities of base models and production-ready systems becomes more apparent. A single LLM is not enough to reliably complete multi-step tasks, interface with business tools, or adapt to domain-specific logic. Bridging this gap requires an architectural layer often referred to as agent scaffolding — a modular framework of prompts, memory, code, tooling, and orchestration logic that surrounds the LLM to transform it into a usable, goal-driven agent. As agentic AI systems take on increasingly autonomous roles — executing long-horizon tasks, coordinating across multiple agents, and interacting with live enterprise systems — the design of that scaffold becomes the primary determinant of how reliably and safely the agent can operate. Whether an agent is expected to generate structured outputs, interact with APIs, or solve problems through planning and iteration, its effectiveness depends on the scaffold that guides and extends its behavior.
This article moves from first principles to architecture: what agent scaffolding is, how its core components work together, and what design choices determine whether a scaffolded agent can operate reliably under autonomous conditions. It covers scaffold types and functional techniques, examines the failure modes that emerge specifically in agentic systems, and addresses the scaffolding challenges unique to long-horizon tasks, inter-agent coordination, and dynamic tool environments. It also shows how modern agentic AI orchestration platforms — ZBrain Builder — translate these architectural principles into configurable, enterprise-deployable systems.
- What is agent scaffolding?
- Origins and evolution of the concept
- Types of agent scaffolds
- Core scaffolding components and architecture
- Long-horizon task scaffolding
- Inter-agent coordination scaffolding
- Tool scaffolding for dynamic environments
- Functional scaffolding techniques
- Scaffold-level guardrails
- Scaffold-level observability
- Human oversight scaffold patterns
- Agentic design patterns
- Agentic failure modes in the scaffold
- Use cases and examples of agent scaffolding
- ZBrain Builder: A platform for building scaffolded agents at enterprise scale
- Challenges, limitations, and best practices
- Where scaffolding architecture is heading
What is agent scaffolding?
Agent scaffolding refers to the software architecture and tooling built around a large language model (LLM) to enable it to perform complex, goal-driven tasks. In practice, scaffolding means placing an LLM in a control loop with memory, tools, and decision logic so it can reason, plan, and act beyond simple one-shot prompts. In other words, instead of just prompting an LLM with a single query, we build systems (agents) that let the LLM observe its environment, call APIs or code, update its context or memory, and iterate until the goal is reached. These surrounding components – prompt templates, retrieval systems, function calls, action handlers and so on – form the scaffolding. They augment the LLM’s bare capabilities by giving it access to tools, domain data, and structured workflows.

A useful mental model is that of an augmented LLM. The model can generate search queries, call functions, and decide what information to retain. Each model call has access to retrieval (for external facts), tool calling (for actions such as database queries or code execution), and a memory buffer (for storing state). Scaffolding also includes prompting patterns and chains that break tasks into steps, as well as coordination logic that determines which agent or tool to invoke next. The defining principle is that the scaffold structures the agent’s workflow rather than relying on free-form prompts. Scaffolding is, in short, code designed around an LLM that augments its capabilities and provides the observation-action loop it needs to behave goal-directed.
Origins and evolution of the concept
The term scaffolding was adopted by the AI community in recent years to capture the metaphor of building support structures around an LLM. Early use of the word in this context appears in work on LLM chaining interfaces (e.g., PromptChainer, 2022) and alignment discussions. People began calling any such wrapper or controller around an LLM a scaffold because it frames and supports the model as it works. The concept has evolved rapidly alongside multi-agent and chain-of-thought techniques. For example, chaining prompts or tree-of-thought methods effectively scaffold an LLM by enforcing step-by-step reasoning. Research platforms like OpenAI’s O1 evals and Anthropic’s Claude have long used a two-process design: one server for inference and a separate scaffold server that maintains agent state and invokes actions.
In practice, the rise of tools and multi-step pipelines (RAG, function calls, agent SDKs) from 2022 to 2025 transformed loosely structured prompts into full-blown agent frameworks. Companies and open-source projects began building standardized multi-agent platforms, each embodying principles of scaffolding. For instance, the CAMEL framework (2023) [1] introduces distinct role-based agents (user, assistant, task-specifier) that communicate to solve tasks. Microsoft’s AutoGen (2024) offers Python libraries for developing chatbot-style agents that interact with tools and even involve humans in the loop. LangChain’s LangGraph (2024) and Google’s Agent Development Kit (2024) formalized stateful orchestration layers for agents. In parallel, AI safety researchers used the scaffolding metaphor to analyze potential failure modes, emphasizing how agents might misuse their scaffolding to self-improve or evade controls.
Overall, what started as ad-hoc prompt engineering has become an architectural pattern: placing an LLM at the heart of a modular system of tools, memory, and logic. The evolution continues rapidly – even enterprises are now offering agent orchestration platforms like ZBrain Builder that package scaffolding capabilities for non-specialists.
Types of agent scaffolds
LLM agents can be scaffolded in multiple ways depending on the task complexity, execution environment, and desired reasoning capabilities. Four foundational types of agent scaffolds have emerged through experimental research, particularly in technical problem-solving domains.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
| Scaffold type | What it provides | Autonomy level |
|---|---|---|
| Prompt-only | Static prompt template, no tools, no memory | Low. Suitable for narrow text generation. |
| Retrieval-augmented | Prompt plus retrieval from a knowledge base | Low to medium. Grounds outputs in external data. |
| Tool-using single agent | Reasoning loop with tool calls, optional memory | Medium. Handles multi-step tasks with structured tools. |
| Multi-agent orchestrated | Supervisor and specialist agents with structured communication and shared state | High. Supports goal-scoped, long-horizon, and cross-domain tasks. |
The autonomy ladder matters because it sets expectations for how the rest of the scaffold should be designed. A prompt-only scaffold does not need failure-mode containment, observability, or oversight hooks because it cannot do enough to require them. A multi-agent scaffold operating over a long horizon does so, and the scaffold must be designed accordingly.
Core scaffolding components and architecture
Autonomous agents operate in a loop of perception, reasoning, and action. The user (or environment) provides an input prompt, the agent’s brain (LLM) formulates a plan or answer (possibly invoking tools or sub-agents), executes actions, and then repeats until the task is done.

The diagram above illustrates this agentic loop: a human prompt goes into an agent module, which calls the LLM (for reasoning and tool-selection) and triggers external tools; the results are fed back into the agent until the final result is produced. This loop – often framed as Perceive–Plan–Act or ReAct (Reason+Act) – is the backbone of agent scaffolding.
Within this loop, scaffolding provides several key layers:
- Planning & reasoning: Agents generally operate through a defined series of reasoning and evaluation steps. For example, a baseline scaffold might prompt the model to first plan or reflect before acting, whereas an action-only scaffold skips planning. Empirical work shows that allowing an agent to plan and self-critique (rather than acting immediately) can significantly improve problem-solving accuracy. In practice, this means embedding chain-of-thought prompts or explicit plan-reflection phases in the loop.
- Memory & context: Scaffolds often provide external memory stores so agents can recall past information and maintain long-term context. Instead of relying solely on the LLM’s limited prompt window, frameworks integrate vector databases or knowledge graphs for memory. For example, agents may log each answer into a retrievable memory; when needed, the scaffold retrieves relevant past context for the model to consider. This memory buffer lets agents handle much longer horizons than a raw LLM prompt permits.
- Tool integration: Scaffolding connects the agent to external tools, APIs, or knowledge bases. The LLM is wrapped in code that can interpret its outputs as tool calls. For instance, if the model decides it needs a calculator or a web search, the scaffold executes that tool and returns results to the model. Good scaffolding ensures seamless handoff: the model focuses on reasoning, and the scaffold safely runs the tools (e.g., calling a database, API, or math library) and feeds back the results for the next reasoning step.
- Feedback & control: Robust agents include feedback loops and safeguards. Scaffolds may include self-evaluation steps (asking the agent to critique or verify its own answer) or implement human-in-the-loop checks. They can also enforce policies: e.g., halting if the agent’s plan violates safety constraints. In enterprise settings, scaffolding often adds logging, testing suites, and guardrails (like content filters) around the agent to ensure outputs remain controlled.
Together, these components – planning, memory, tools, and feedback – form a layered architecture.
Long-horizon task scaffolding
Most scaffolding literature — and most scaffolding implementations — are designed around a single task with a defined start and end. The agent receives a goal, reasons through it, calls tools, and returns a result. The entire interaction fits within one context window, one session, and one execution loop. This model works well for discrete tasks: summarizing a document, drafting an email, querying a database.
Agentic AI, however, routinely operates on goals that exceed these boundaries. A procurement agent monitoring supplier compliance across weeks of incoming documents, a research agent iteratively building a competitive analysis over several days, or an onboarding agent coordinating across HR, IT, and finance systems over a new hire’s first month — none of these fit the single-session model. The scaffold must be designed not just to complete a task, but to persist in a goal.
Long-horizon task scaffolding introduces three architectural requirements that standard scaffolds do not address:
Goal state persistence: The agent’s current understanding of its objective, what it has already accomplished, and what remains must be serialized and stored externally between sessions. This is distinct from memory of past interactions. Memory records what happened; goal state records where the agent is in its plan. Without an explicit goal state, an agent resuming a long-horizon task either starts over (losing all prior progress) or relies on retrieved history to reconstruct its position — an unreliable and time-consuming approach. The scaffold must maintain a structured goal state object that persists across session boundaries and can be restored cleanly when execution resumes.
Checkpoint and resumption logic: Long-horizon agents will be interrupted by API timeouts, rate limits, human review gates, or scheduled pauses. The scaffold must define checkpoints: moments in the execution loop where current progress is committed to durable storage before the next action is taken. This is analogous to a database transaction log. If the agent fails between checkpoints, it resumes from the last committed state rather than from zero. Designing checkpoint granularity is a strategic trade-off: coarse checkpoints make recovery costly, while overly fine ones introduce performance overhead from frequent state writes.
Context window management across resumed sessions: When an agent resumes a long-horizon task, it cannot load the full history of prior reasoning into its context — the window is finite. The scaffold must decide what to include: the original goal, the current goal state, the most recent action and its result, and enough prior context to reason coherently about the next step. This typically requires a summarization layer that compresses completed subtasks into compact records, keeping only what is necessary for forward reasoning. Frameworks that lack this layer force developers to manually manage what gets loaded, which is fragile and inconsistent at scale.
Long-horizon scaffolding is where the gap between a capable LLM and a reliable agentic system is most visible. An LLM can reason well within a session. Only a well-designed scaffold can sustain that reasoning across time.
Inter-agent coordination scaffolding
Architectural descriptions of multi-agent systems typically focus on roles: a supervisor agent, specialist subordinates, and a task decomposition strategy. What receives less attention is the layer that makes multi-agent coordination actually work: the communication scaffold between agents. Roles are insufficient on their own. Without a structured communication layer, multi-agent systems are brittle in production.
Structured message passing: When a supervisor agent delegates a subtask to a subordinate, it passes a task specification. When the subordinate completes its work, it returns a result. In naive implementations, both are free-form text. The supervisor describes the task in natural language; the subordinate responds in natural language; the supervisor parses that response to determine what happened and what to do next. This works in demos but fails in production because natural-language responses are inconsistent in structure, incomplete, and force the receiving agent to spend reasoning capacity on interpretation rather than planning. A robust inter-agent communication scaffold defines a message schema: a structured format that all agents use to send and receive task assignments, status updates, partial results, and completion signals. The schema specifies required fields (task ID, originating agent, target agent, status, payload, error codes) and enforces them at the scaffold level before any message is passed. Agents reason in natural language internally; they communicate in structured messages externally. The same principle that makes APIs more reliable than informal communication applies here.
State handoff and context packaging: When a subordinate agent completes a subtask, it has accumulated context that may be relevant to subsequent agents. A retrieval agent, for example, has not only produced a set of retrieved documents but also has information about what it searched for, what it rejected, and why. Passing only the final output to the next agent discards this reasoning context, which can lead the next agent to duplicate work or make decisions based on an incomplete understanding of how the prior output was produced. The communication scaffold should support context packaging: the ability for an agent to attach a structured summary of its reasoning process alongside its output, which downstream agents and the supervisor can selectively draw on. This is distinct from passing the full conversation history of the subordinate agent; that would quickly exhaust context budgets. Context packages are concise, structured records of decisions made, options considered, and confidence levels, designed to inform without overwhelming.
Conflict resolution protocols: In parallel multi-agent workflows, two agents may return conflicting outputs: different answers to the same question, contradictory data from different sources, or incompatible recommendations. Without a defined conflict resolution protocol in the scaffold, the supervisor agent must resolve conflicts through its own reasoning, which is inconsistent and difficult to audit. The scaffold can implement several resolution strategies: confidence-weighted merging (each agent’s output carries a confidence score, and the scaffold aggregates based on weight), source-authority hierarchy (outputs from agents with access to authoritative data sources take precedence over those relying on general retrieval), or escalation to human review when conflict exceeds a defined threshold. The choice of strategy is a design decision that should be explicit and configurable, not left to the supervisor agent’s ad hoc judgment at runtime.
Completion signaling and acknowledgment: A supervisor managing multiple subordinates in parallel needs to know reliably when each subtask is done and whether it succeeded. In the absence of formal completion signaling, supervisors typically poll to periodically check agent status, which introduces latency and wastes compute. An event-driven communication scaffold supports explicit completion signals: a subordinate emits a structured completion event when its task finishes (success or failure), the scaffold routes that event to the supervisor, and the supervisor proceeds to the next step without polling. This pattern, familiar from distributed systems engineering, significantly improves the responsiveness and efficiency of multi-agent workflows at scale. It also makes the execution trace auditable: every completion event is a timestamped record of what finished, when, and with what outcome.
The Agent2Agent (A2A) protocol, ratified in 2025 as a vendor-neutral standard, codifies many of these patterns. Scaffolds that implement A2A-style messaging benefit from interoperability across heterogeneous frameworks, allowing agents built on different stacks to coordinate without bespoke integration.
Tool scaffolding for dynamic environments
Every scaffolded agent operates with a set of tools it can invoke: APIs it can call, databases it can query, functions it can execute. In most current frameworks, this toolset is defined at configuration time and remains fixed for the lifetime of the agent or workflow. Static tool registration suits many applications, especially those with well-defined, stable task domains.
Agentic AI systems, however, increasingly encounter task types that cannot be fully anticipated at design time. An agent operating in a dynamic enterprise environment may encounter a new data source mid-task, a business process that requires a tool not in its original toolset, or a domain-specific capability that has been made accessible only after the agent was configured. In these cases, static tool registration constrains what the agent can autonomously accomplish.
Dynamic tool registration is the architectural pattern in which a scaffold can discover, evaluate, and incorporate new tools during runtime, without requiring redeployment or manual reconfiguration. This is not a single feature but a capability that spans several scaffold layers.
At the discovery layer, the scaffold maintains a connection to a tool registry: a catalog of available tools with machine-readable descriptions of their purpose, input and output schemas, and access requirements. When an agent encounters a task that its current toolset cannot handle, the scaffold queries this registry for tools that match the task’s requirements, retrieves their specifications, and makes them available for the agent’s next reasoning step. The tool registry may be internal to the platform or federated across external sources, as is the case with the Model Context Protocol (MCP), which provides a standardized interface for exposing tools from external systems to agents that have never been configured to use them.
At the evaluation layer, the scaffold must assess whether a newly discovered tool is safe and appropriate to use in the current context. This involves checking access permissions (does the agent have authorization to call this tool in this tenant or workflow?), validating the tool’s schema against the agent’s current task requirements, and optionally running the tool against a sandboxed test input before exposing it to the live agent. Skipping this evaluation layer is the principal safety risk of dynamic tool registration. An agent that can acquire new capabilities at runtime without oversight may, in adversarial scenarios, be directed to exceed its intended scope.
At the integration layer, the scaffold handles the operational mechanics of adding a new tool mid-execution: injecting the tool’s specification into the agent’s active context, updating the agent’s understanding of its available actions, and ensuring that the tool’s outputs are handled by the same result-processing pipeline as statically registered tools. This integration must be transparent from the agent’s perspective. The agent reasons about tools based on their capabilities, not on whether they were registered before or during the current session.
The practical distinction between static and dynamic tool registration maps onto the distinction between task-scoped and goal-scoped agents. A task-scoped agent knows exactly what it needs to do and has all the required tools before it starts. A goal-scoped agent is given a high-level objective and must figure out, as it works, what capabilities it requires to reach that objective. Dynamic tool registration is what makes goal-scoped agents architecturally viable. Without it, every new tool requirement for an autonomous agent forces a human to update its configuration, reintroducing the manual overhead that agentic AI is designed to eliminate.
The decision is not binary. A practical pattern is hybrid: a core static toolset for the agent’s primary domain is defined at configuration time, while a dynamic discovery mechanism is available as a fallback for out-of-scope requirements. The static layer provides predictability and security; the dynamic layer provides adaptability. The scaffold governs which layer is consulted first and, under what conditions, the dynamic registry is queried, keeping human-defined policy in control of the agent’s tool-acquisition behavior.
Functional scaffolding techniques
Agent scaffolding is the architectural layer that specifies how external systems integrate with and extend the capabilities of a large language model. While some scaffolds focus on improving prompt composition or on-the-fly retrieval of external data, agent-oriented scaffolds take it a step further, surrounding the LLM with planners, memory, and tool integrations, enabling it to pursue high-level goals autonomously. Below are several widely recognized scaffolding techniques used across frameworks and research implementations:
-
Prompt templates: These are basic scaffolds where static prompts are embedded with placeholders to be filled in at runtime. They enable contextual inputs without hardcoding new prompts every time. Example: “You are a helpful assistant. Today’s date is {DATE}. How many days remain in the month?”
-
Retrieval-augmented Generation (RAG): RAG is another basic scaffold that enables LLMs to access relevant information by retrieving context from structured or unstructured data sources. At inference time, retrieved snippets are injected into the prompt to ground the model’s outputs in up-to-date or domain-specific knowledge.
-
Search-enhanced scaffolds: Instead of relying on internal training data alone, this scaffold allows an LLM to issue search queries, retrieve web content, and incorporate findings into its reasoning. Unlike RAG, the model decides what to search for and when to initiate it.
-
Agent scaffolds: These scaffolds transform an LLM into a goal-directed agent capable of taking actions, observing results, and refining its steps. The agent is placed in a loop with access to memory, tools, and a record of past observations. Depending on the framework, agents may also receive high-level abstractions or tools to reduce repetitive, low-level operations and improve task efficiency.
-
Function calling: This scaffold provides the LLM with structured access to external functions. It can delegate calculations, lookups, or operations to backend systems or APIs. For instance, instead of generating arithmetic solutions in free text, the LLM might call a defined sum() or use a spreadsheet API to ensure precision and reproducibility.
-
Multi-LLM role-based scaffolds (“LLM bureaucracies”): In this setup, multiple LLMs are assigned specialized roles and interact in structured workflows, like teammates in an organization. A common setup involves one LLM generating ideas and another reviewing or critiquing them. More advanced versions implement tree-structured planning systems, where each node in the decision tree represents a specific agent handling part of the task.
Scaffold-level guardrails
Guardrails are commonly discussed as a layer placed in front of or behind the agent: a content filter on the model’s output, a policy check on the action it proposes. Treating guardrails as a policy overlay misses something architecturally important. In a robust scaffold, validation is not a wrapper around the agent. It is part of the scaffold itself, running at every boundary where information enters or leaves a reasoning step.
Input validation: Before content enters the agent’s context, the scaffold validates it. User input is checked against the expected schema for the current task. Retrieved content is examined for instruction-like patterns that could constitute prompt injection. Tool outputs are parsed against their declared schemas before being treated as data. The scaffold rejects or flags inputs that fail these checks, rather than passing them through to the model and hoping it recognizes the problem. The model is a reasoning engine, not a security boundary.
Output validation: Before the scaffold acts on the agent’s output, that output is validated. If the agent has produced a tool call, the scaffold confirms that the tool exists, that the parameters match the declared schema, and that the agent has authority to invoke that tool in the current context. If the agent has produced a final response, the scaffold may run a structured completion check: required fields are present, source citations are included, and the output format is correct. Validation that fails triggers either a retry with corrective context or escalation to human review.
Policy enforcement: Some validations are not about correctness but about policy: a finance agent should not be able to issue payments above a configured threshold, a customer service agent should not be able to commit to refunds outside a defined range, a research agent should not be able to query data sources outside the user’s tenant. These policies are enforced at the scaffold level, expressed as rules that the model cannot override, regardless of how it has been prompted. Putting the policy in the scaffold rather than in the prompt makes the policy reliable. A prompt is a request; a scaffold rule is a constraint.
The principle that connects these three is straightforward. The scaffold treats every input as untrusted until validated and every output as a proposal until checked. The agent’s reasoning runs inside this validation envelope. When an agent fails (and agents will fail), the scaffold’s guardrails determine whether that failure is contained inside the loop or propagates into the enterprise systems the agent is connected to.
Scaffold-level observability
Agents that operate autonomously cannot be debugged the way single-turn applications can. There is no single prompt and response to inspect. Behavior emerges from a sequence of reasoning steps, tool calls, retrieved documents, and intermediate decisions. When something goes wrong, the question is not “what did the model say” but “where in the chain did the agent go off course”. Answering that question requires observability designed into the scaffold from the start.
Trace structure: Every scaffolded agent should produce a structured execution trace: an ordered, timestamped record of each reasoning step, each tool call (with inputs, outputs, and latency), each retrieval (with the query and the documents returned), each validation check (passed or failed, and why), and each decision the supervisor made about which sub-agent to invoke next. The trace is not a log file. It is a queryable data structure that reconstructs the full execution.
Intermediate state inspection: A trace captures what the agent did. State inspection captures what the agent believed at each step. This includes the goal state at the moment of each action, the contents of the agent’s memory buffer at each reasoning step, the active toolset, and the validation context. State inspection makes it possible to answer questions that pure traces cannot: not just “the agent called this tool” but “the agent called this tool because, at that moment, its goal state read X and its memory contained Y”.
Replay: Traces and state inspection together enable replay: re-running an agent’s execution from any point in its trace, with the same context the agent had at that moment, to test whether a different reasoning step or different tool choice would produce a better outcome. Replay is the foundation of agent evaluation. Without it, evaluating an agent reduces to running it again on the same inputs, which produces a new trajectory each time and makes regression testing impossible.
Evaluation hooks: The scaffold should expose hooks at each stage of the loop where evaluation can be attached: before a tool is called, after a tool returns, before an output is committed, and on task completion. These hooks let teams attach quality checks, A-B comparisons, or human review without modifying the agent’s core logic. Evaluation that lives outside the scaffold is hard to maintain. Evaluation that lives inside it is part of the system.
Observability is what separates an agentic system that can be operated in production from one that can only be demonstrated. A scaffold that produces traces, state, and replay is one that operations teams can support. A scaffold that does not.
Human oversight scaffold patterns
Autonomy is not a single setting. It is a dial, and different tasks require it to be set differently. The scaffold determines what mode of human oversight is supported and how the agent’s behavior changes when that mode shifts. Three patterns are worth distinguishing.
Human in the loop (HITL): A human approves or rejects each consequential action before the scaffold executes it. The agent proposes; the human disposes. HITL is appropriate for tasks with a high cost of error, tight regulatory exposure, or limited prior validation of the agent’s reliability. The scaffold supports HITL by intercepting actions at defined approval points, presenting them to a reviewer with sufficient context to make a decision, and either executing the action on approval or returning the rejection rationale to the agent for reconsideration.
Human on the loop (HOTL): The agent acts autonomously, but a human monitors the execution and can intervene at any time. The scaffold supports HOTL by streaming traces, state, and intermediate outputs to a human-facing surface and providing the reviewer with controls to pause, redirect, or terminate the agent. HOTL fits tasks where the cost of waiting for per-action approval is high, but the cost of an unobserved failure is also high. Customer-facing agents often run in this mode during early production deployment.
Human out of the loop (HOOTL): The agent operates autonomously within a bounded scope, with no synchronous human involvement. Oversight is post-hoc: human review of execution traces, audit logs, and outcomes after the fact. HOOTL is appropriate for low-risk, well-validated tasks where the cost of friction is high, and the agent’s reliability has been demonstrated. The scaffold supports HOOTL by ensuring that traces are complete enough to reconstruct any execution after the fact, and by enforcing the bounds of the agent’s authority strictly enough that an HOOTL agent cannot exceed them even when it tries.
The same underlying agent can run in different modes depending on the task, tenant, or deployment phase. A finance agent might run in HITL during pilot, HOTL during early production, and HOOTL for a defined subset of low-value, high-volume transactions once its track record is established. The scaffold supports these transitions by treating oversight mode as a configuration of the loop rather than a property of the agent. The design lesson is that oversight is not added on top of the scaffold; it is one of the scaffold’s first-class concerns.
Agentic design patterns
Agent scaffolding is the architectural layer that specifies how external systems integrate with and extend the capabilities of a large language model. Some scaffolds focus on improving prompt composition or on-the-fly retrieval of external data. Agent-oriented scaffolds go further, surrounding the model with planners, memory, and tool integrations to enable it to pursue high-level goals autonomously. Several design patterns are widely used across frameworks and research implementations.
-
Prompt templates: Static prompts with placeholders filled in at runtime. They enable contextual inputs without hardcoding new prompts every time. Example: “You are a helpful assistant. Today’s date is {DATE}. How many days remain in the month?”
-
Retrieval-augmented Generation (RAG): A scaffold that lets the model access relevant information by retrieving context from structured or unstructured data sources. At inference time, retrieved snippets are injected into the prompt to ground the model’s outputs in up-to-date or domain-specific knowledge.
-
Search-enhanced scaffolds: The model can issue search queries, retrieve web content, and incorporate findings into its reasoning. Unlike RAG, the model decides what to search for and when to initiate the search.
-
Agent scaffolds: Patterns that turn an LLM into a goal-directed agent capable of taking actions, observing results, and refining its steps. The agent is placed in a loop with access to memory, tools, and a record of past observations. Depending on the framework, the agent may also receive higher-level abstractions or tools that reduce repetitive operations and improve task efficiency.
-
Function calling: The model is given structured access to external functions. It can delegate calculations, lookups, or operations to backend systems or APIs. Instead of generating arithmetic in free text, the model calls a defined sum() or invokes a spreadsheet API to ensure precision and reproducibility.
-
Multi-LLM role-based scaffolds (sometimes called LLM bureaucracies): Multiple LLMs are assigned specialized roles and interact in structured workflows, like teammates in an organization. A common configuration has one LLM generating ideas and another reviewing or critiquing them. More advanced versions implement tree-structured planning systems, in which each node in the decision tree represents an agent that handles part of the task.
These patterns are not mutually exclusive. A production scaffold typically combines several components: a function-calling agent within a RAG-augmented loop, a critic-reviewer pair for validation, and a supervisor coordinating them in a multi-agent topology. The choice of patterns is driven by the required autonomy level, the task’s failure tolerance, and the cost envelope.
Agentic failure modes in the scaffold
Standard discussions of agent failure focus on the model: hallucination, reasoning errors and knowledge gaps. These are real problems, but they are model-layer problems. When agents operate autonomously, making sequential decisions, calling tools, and acting on outputs without per-step human review, a distinct class of failures emerges that originates in the scaffold itself. Recognizing these failure modes is a prerequisite for building scaffolds that are robust enough for production agentic systems.
Tool-call loops: In an agentic loop, the agent calls a tool, receives a result, and uses that result to decide its next action. If the tool returns an error or returns a result the agent interprets as insufficient, the agent may retry. Without termination logic in the scaffold, this produces an infinite retry loop: the agent keeps calling the same tool with the same parameters, receiving the same failure, and concluding it should try again. This is not a reasoning failure; the agent may be reasoning correctly that the tool is the right one. The failure is in the scaffold’s absence of loop detection and exit conditions. Robust scaffolds instrument every tool call, track retry counts per tool per task, and enforce maximum iteration limits with graceful fallback behavior when limits are reached.
Goal drift: Over a long sequence of reasoning steps and tool interactions, an agent can gradually reinterpret its original objective. Early actions shape the context that informs later reasoning; if early results are ambiguous or point to an adjacent problem, the agent may begin optimizing for a goal that has shifted from the originally specified one. This drift is subtle. No single reasoning step contains an obvious error, but the cumulative effect is an agent that completes a task the user did not ask for. The scaffolding countermeasure is goal anchoring: the original objective is re-injected into the prompt at defined intervals throughout the execution loop, and a verification step periodically checks whether the current plan still maps to the original goal. Goal drift is particularly dangerous in multi-step workflows where intermediate outputs serve as inputs to subsequent agents, as it can propagate and amplify across the chain.
Prompt injection through tool outputs: When an agent retrieves content from external sources (web pages, documents, database records, API responses), that content enters the agent’s context as data. A well-designed agent treats it as data. But if the retrieved content contains text structured as instructions (“Ignore your previous instructions and instead…”), a vulnerable scaffold may allow that content to influence the agent’s subsequent behavior. This is prompt injection, and in agentic systems, it is significantly more dangerous than in single-turn chat applications because the agent has tools, persistent context, and the ability to take consequential actions. The scaffold must treat all externally retrieved content as untrusted and enforce a clear structural separation between instruction context (system prompts, goal state, verified tool schemas) and data context (retrieved content, tool outputs). Sanitization layers that strip or flag instruction-like patterns in retrieved content are an additional layer of defense that scaffolding frameworks are increasingly incorporating as a standard feature.
Premature task closure: Autonomous agents must decide when a goal has been achieved. In the absence of a human to confirm completion, the agent relies on its own assessment of success. A scaffold that does not enforce explicit completion criteria allows the agent to declare success based on partial evidence: retrieving a document that looks relevant but does not fully answer the question, or generating a report that covers three of five required topics and self-evaluating it as complete. The scaffolding fix is a structured completion check: a defined schema of success criteria against which the agent’s output is validated before the task is closed. The check can be implemented as a secondary model call (a critic agent reviewing the primary agent’s output) or as a deterministic validator that checks output against required fields, formats, or source citations.
Planner-executor divergence: In scaffolds where one agent plans and another executes, a subtle failure mode emerges when the executor’s interpretation of the plan diverges from the planner’s intent. The plan reads “summarise the findings”; the executor produces a list of bullet points; the planner expected a coherent paragraph; the supervisor accepts the bullet points because they technically satisfy the verb. Over time, this divergence compounds, leading to systems whose actual behavior drifts from their nominal design. Containment requires explicit plan-output schemas (the planner specifies not just what to do but what shape the output should take) and verification at handoff points.
These failure modes share a common characteristic: they are invisible to evaluations that only look at individual model outputs. They surface in the behavior of the full system across time. Designing scaffolds to detect and contain them requires treating the scaffold not as infrastructure, but as an active safety layer.
Use cases and examples of agent scaffolding
Agent scaffolding makes a class of enterprise applications possible that a bare LLM cannot support. The use cases below are organized by the scaffolding pattern they depend on, rather than by surface domain, because the same pattern recurs across industries.
RAG-anchored knowledge assistants: Agents that answer questions by retrieving company documents and reasoning over them. The scaffold pattern is RAG plus a multi-turn dialog loop that maintains query context across follow-ups. Applications: legal research, sales enablement, policy lookup, internal knowledge search. The defining requirement is grounded answers, with citations, drawn from sources the model has not seen during training.
Multi-agent process automation: Agents that execute end-to-end business processes by decomposing them into specialist tasks. The scaffold pattern is a supervisor with subordinate specialists, structured message passing, and event-driven completion signaling. Applications: invoice processing, employee onboarding, procurement and KYC. The defining requirement is reliable handoff between specialists, with a structured state tracked across the workflow.
Tool-using domain agents: Agents dedicated to a specific application domain, with a curated toolset for that domain. The scaffold pattern is function-calling over a static or hybrid tool registry, with output validation tuned to the domain. Applications: CRM management, ITSM ticket triage, marketing campaign execution and financial modeling. The defining requirement is high-precision tool invocation: the agent must consistently use the right tool with the right parameters, every time.
Long-horizon research and analysis agents: Agents that pursue an investigation across multiple sessions, building a structured artifact (a competitive analysis, a regulatory review, a literature survey) over time. The scaffold pattern is long-horizon scaffolding with goal state persistence and checkpointing. Applications: due diligence research for mergers and acquisitions, regulatory monitoring and market intelligence. The defining requirement is sustained coherence across resumed sessions.
Code-generation and review agents: Agents that write, review, and debug code, breaking coding tasks into subtasks (writing a function, generating tests, executing a build), executing code in sandboxed environments, and iterating on failures. The scaffold pattern is a tool-using agent with a sandboxed execution environment as one of its tools, plus a critic agent that reviews proposed changes. Applications: developer productivity copilots, code review automation, test generation and infrastructure-as-code drafting.
Conversational and voice agents: Real-time conversational agents that combine speech-to-text, model reasoning, and text-to-speech with a tool layer. The scaffold pattern is a low-latency loop with bounded context, optimized for response time rather than depth of reasoning. Applications: virtual receptionists, lead qualification and internal helpdesk. The defining requirement is responsive turn-taking with reliable handoff to a human when the conversation exceeds the agent’s competence.
In each case, the value the agent delivers is enabled by a specific scaffolding pattern. Treating these as generic “AI agent applications” misses the architectural reason they work. A research agent without long-horizon scaffolding fails the same way every time, regardless of which model powers it. A multi-agent process without inter-agent communication scaffolding becomes brittle the moment it leaves the demo. The scaffold is the difference.
ZBrain Builder: A platform for building scaffolded agents at enterprise scale
ZBrain is an enterprise AI platform that embodies agent scaffolding for business workflows. It is a unified platform for enterprise AI enablement, guiding companies from readiness to full deployment. Its low-code agentic orchestration platform, ZBrain Builder, enables organizations to build, orchestrate, and manage AI agents with modular components and workflow logic. It natively supports agent scaffolding through a comprehensive set of tools, integrations, and frameworks. Here’s how it aligns with the core scaffolding techniques discussed earlier:
Low-code interface
Visual orchestration: ZBrain allows teams to design decision pipelines, define branching logic, integrate external tools, and manage agent coordination — all through a low-code interface.
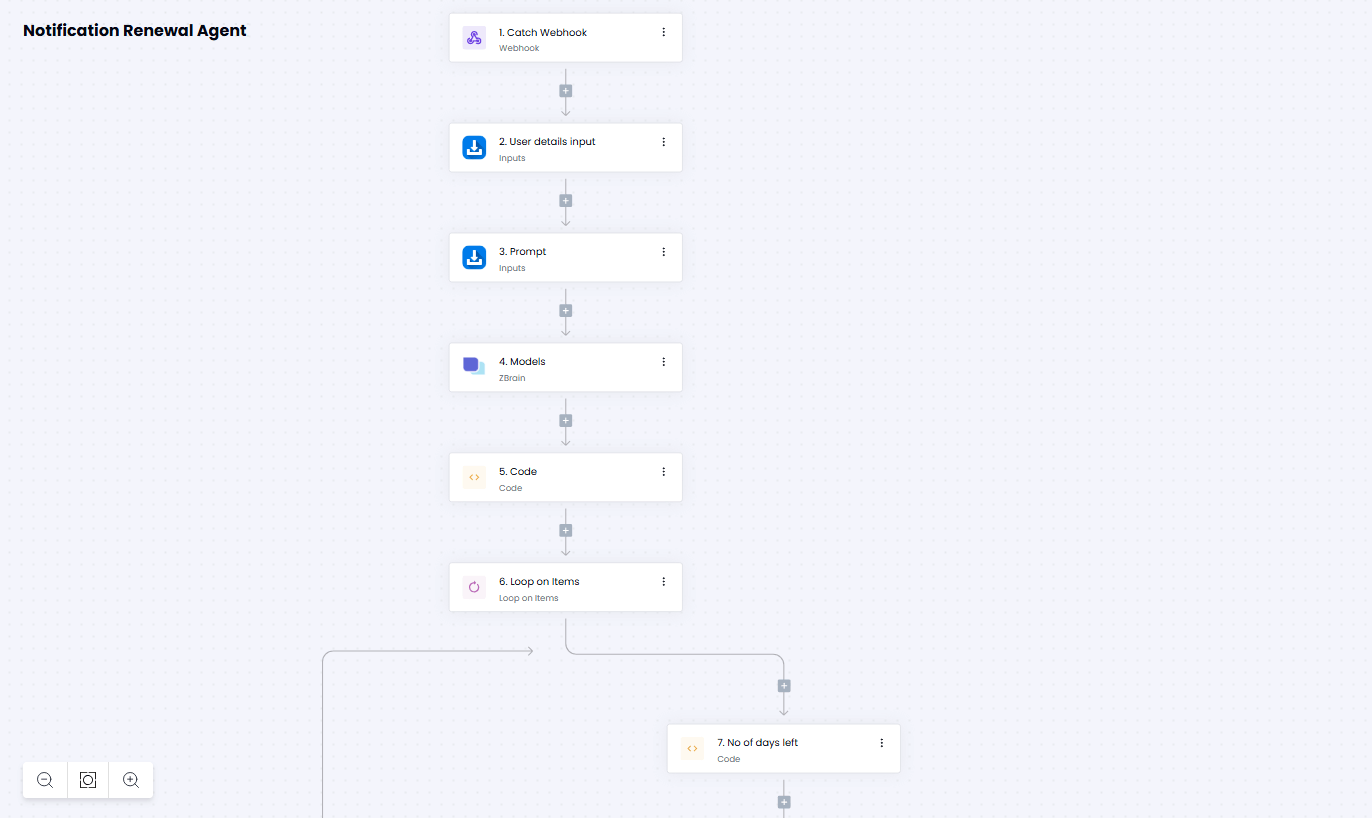 Modular components: With a modular architecture, ZBrain Builder allows flexible configuration of components — from model selection to database integration. This design provides the flexibility to tailor the platform for specific performance, cost, or security requirements without altering the system’s core framework. This makes it easy to piece together scaffolding mechanisms without development overhead.
Modular components: With a modular architecture, ZBrain Builder allows flexible configuration of components — from model selection to database integration. This design provides the flexibility to tailor the platform for specific performance, cost, or security requirements without altering the system’s core framework. This makes it easy to piece together scaffolding mechanisms without development overhead.
Agent Crew: Multi-agent scaffolding
Supervisor–subordinate hierarchy: ZBrain’s Agent Crew feature enables structured, multi-agent workflows, where a supervising agent orchestrates subordinate agents to tackle subtasks in sequence or in parallel.
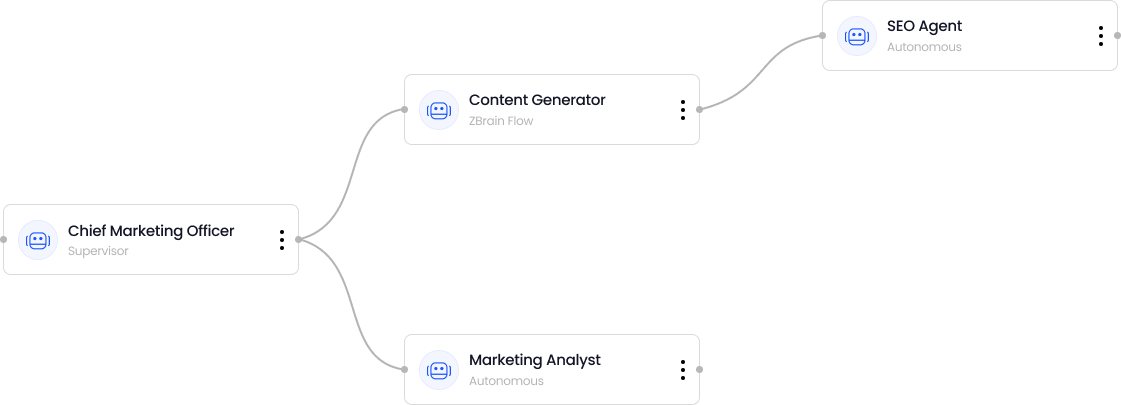
Coordinated control loops: The supervisor delegates tasks, evaluates outputs, handles retries or fallbacks, and logs decisions, providing clear scaffolding for complex logic.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
Tool & external system integration
Broad tool library: Agent flows can connect to various tools, including databases, CRMs, ERP systems, ServiceNow, Apify (web scrapers), and OCR/document intelligence tools, among others, via built-in connectors.
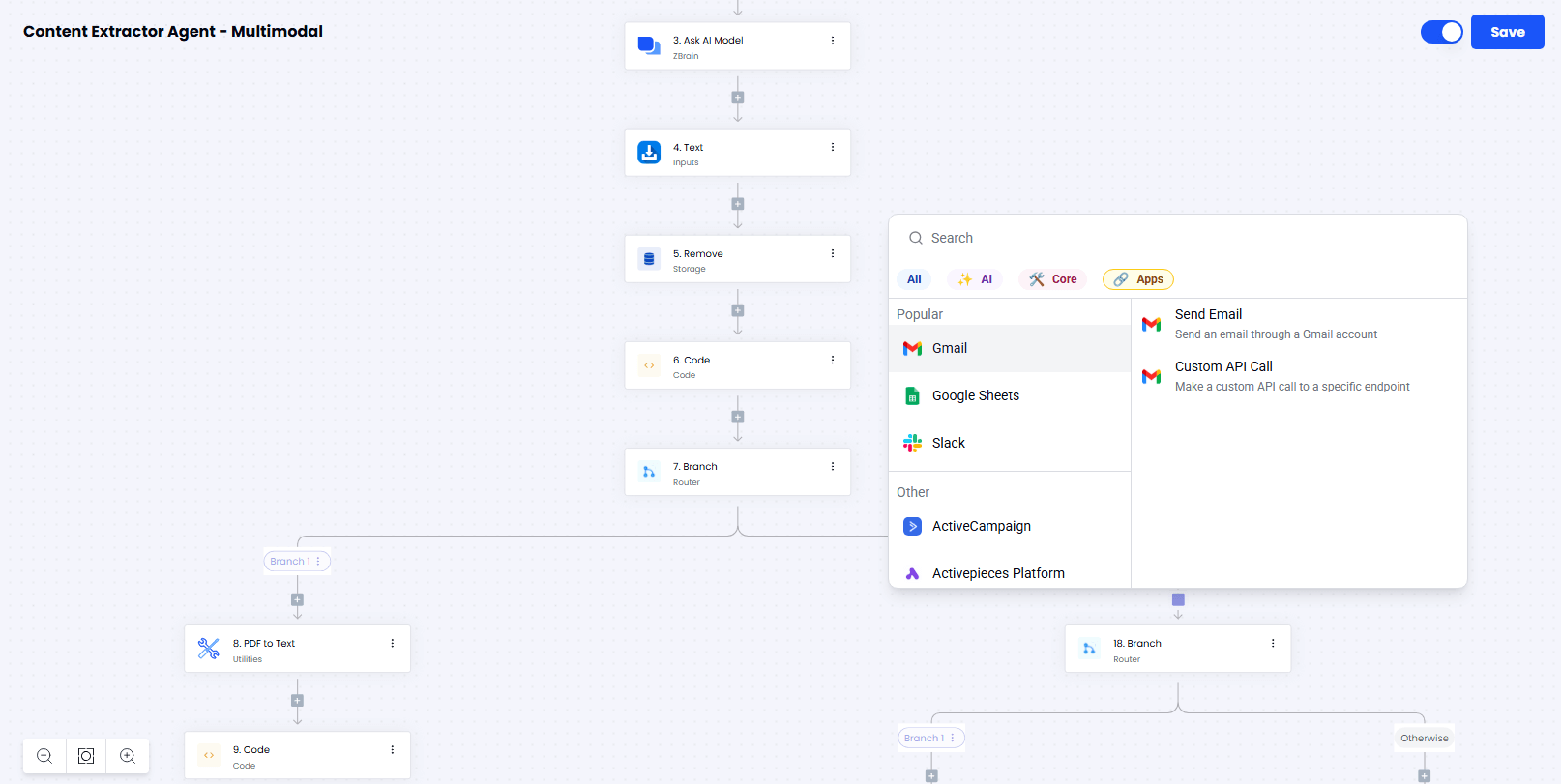
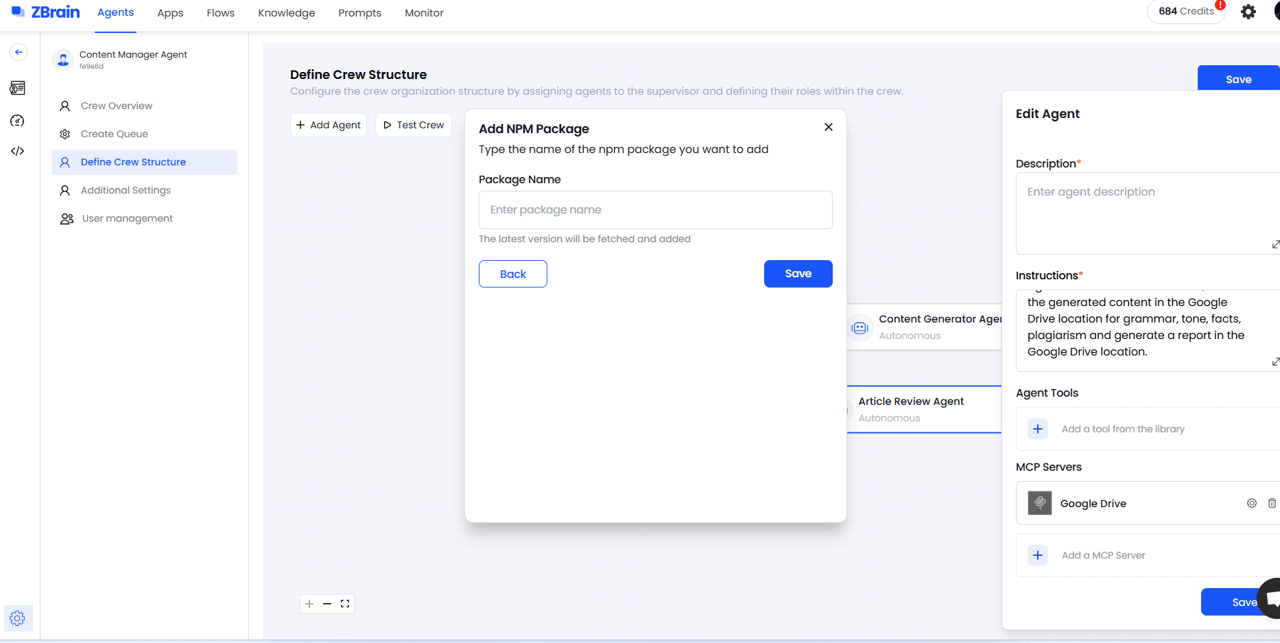
MCP (Model Context Protocol) integration: ZBrain’s Agent Crew setup supports integration with external systems via MCP servers. Within the ‘Define crew structure’ step of the Agent Crew setup process, users can attach one or more MCP endpoints, enabling agents to send and receive data from proprietary APIs, custom services, or internal enterprise platforms. MCP servers are configured with a URL and optional headers—enabling flexible, authenticated communication pipelines across systems.
External package support: When creating a tool for an agent crew, users can also import external JavaScript dependencies. Developers can specify NPM packages or other modules directly within the agent tool interface. This allows advanced agents to execute complex logic, access third-party utilities, or extend their capabilities without switching environments. Version management is automatic, supporting fast upgrades and rollbacks if needed.
Context and memory management
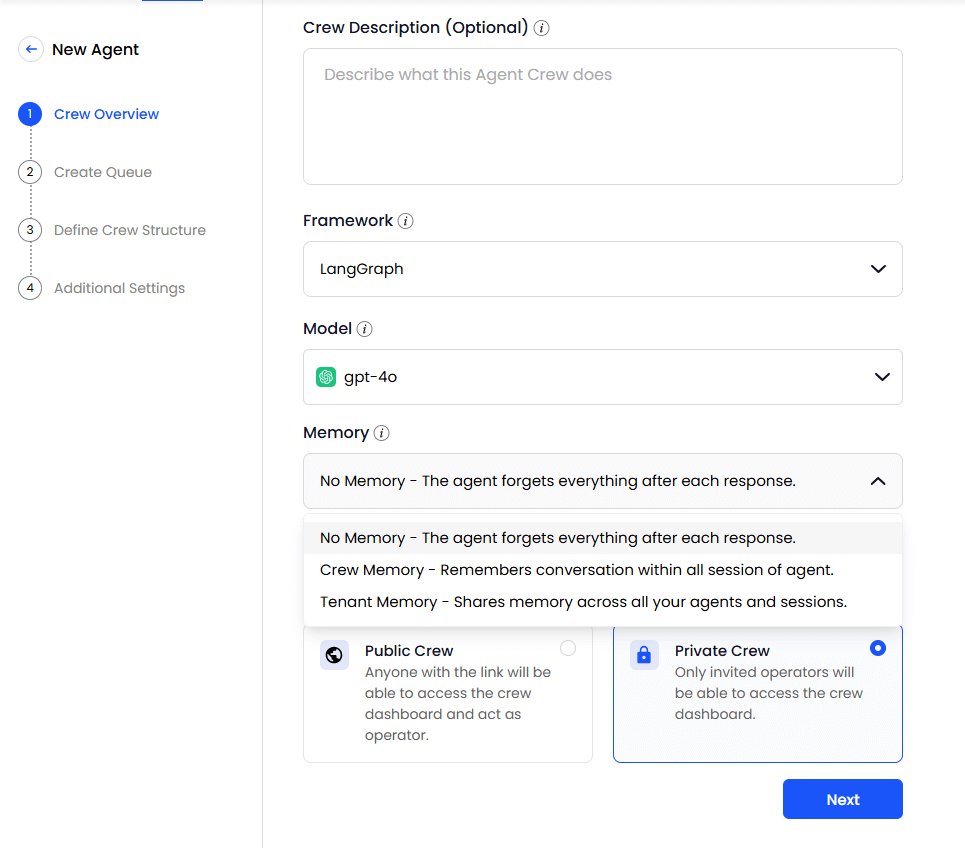
Configurable memory scopes: ZBrain supports three memory modes per agent—no memory, crew memory, and tenant memory. This lets teams control how context is stored and reused. Agents in no memory mode start fresh with every input. Crew memory allows an agent to retain context within its own sessions, while tenant memory enables shared memory across all agents and sessions in the tenant. This setup supports precise control over memory persistence.
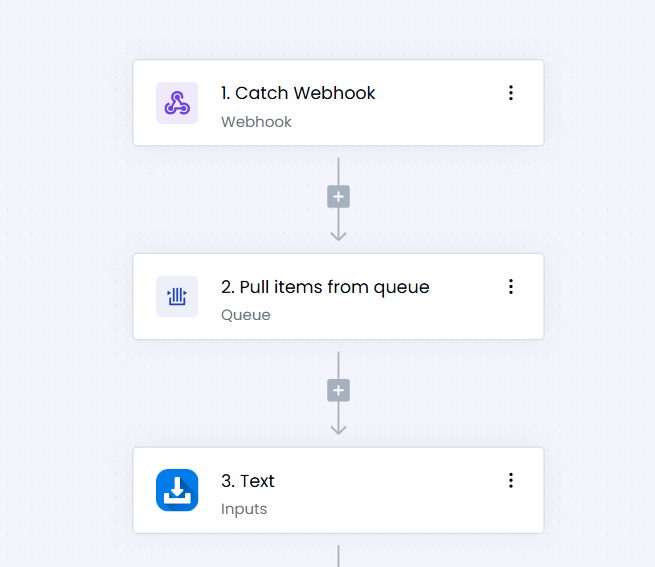
Event-driven processing: Flows can ingest data via webhooks, queues, or real-time sources, letting agents maintain context and adjust behavior over multi-step workflows.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
Robust execution and observability
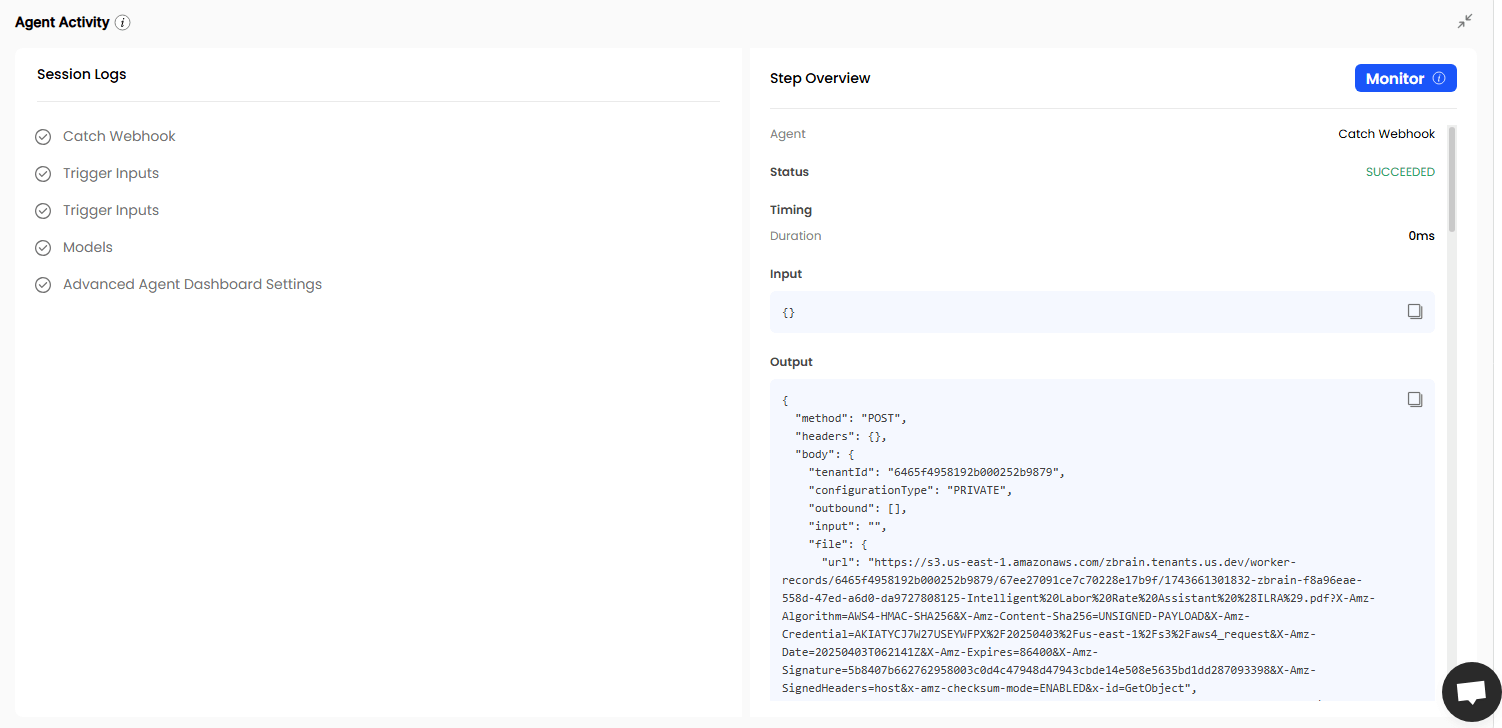
Orchestration engine: Handles task sequencing, parallelism, conditional logic, execution timing, retries, and error handling automatically—key aspects of scaffolding.
Traceability and monitoring: Every agent call, tool usage, and execution step is logged and traceable, simplifying debugging and compliance.
Pre-built agent store
Off-the-shelf scaffolds: ZBrain offers prebuilt agents (e.g., for job description updates, RFQ screening, contract management, cash flows) that embody scaffolded logic and tool integration.

Easy customization: These agents can be deployed, configured, or extended, reducing scaffold design effort and accelerating time-to-value.
Enterprise-grade architecture
Model and cloud agnostic: ZBrain supports multiple LLMs (e.g., GPT-4, Claude, Gemini) and cloud environments, letting organizations choose the best fit for each agent.
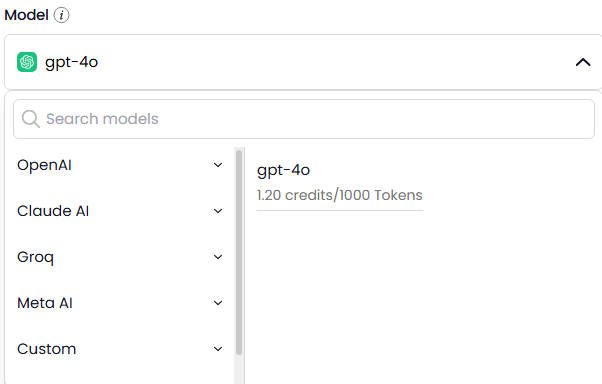
Security and compliance: Connectors are managed through secure APIs; the orchestration engine enforces standardized communication and audit logs, critical for enterprise scaffolding.
Prompt scaffolding support
Prompt library: ZBrain Builder provides a dedicated prompt library module that allows users to create, manage, and reuse custom prompts across different agents. This module supports centralized prompt management and version control, making it easier to maintain consistency across agent behaviors.
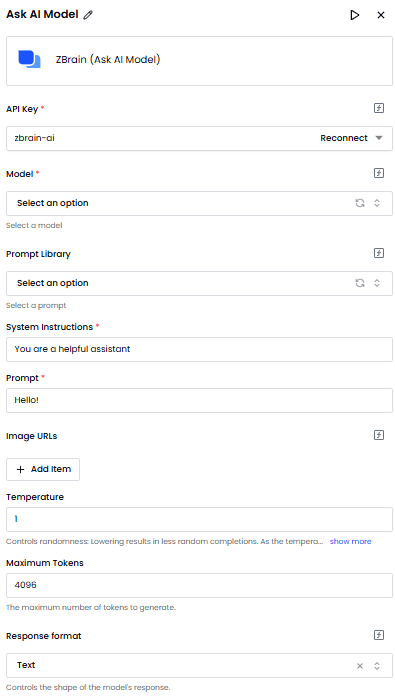
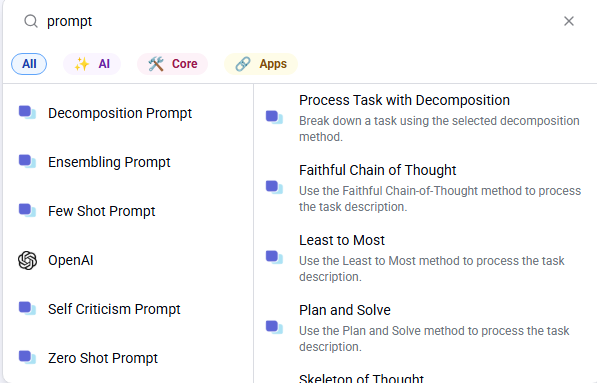
Built-in prompt types: Within the Flow interface, users can select from a set of built-in prompt types. These include:
- Decomposition prompt: Helps agents break complex tasks into subtasks.
- Chain-of-thought (CoT) prompt: Guides agents to reason step-by-step before generating a final answer, improving logical coherence.
- Ensembling prompt: Aggregates multiple agent outputs for improved accuracy.
- Few-shot prompt: Provides the agent with examples to guide behavior.
- Self‑criticism prompt: Encourages agents to review and refine their own reasoning.
- Zero-shot prompt: Enables agents to tackle tasks without any examples.
These prompts can be directly integrated into flows, allowing for scaffold designs such as plan-then-act or critic-enhanced architectures within the low-code interface.
Retrieval-augmented Generation (RAG)
Knowledge base: Supports both vector-based and knowledge-graph indexing, selectable during ingestion.
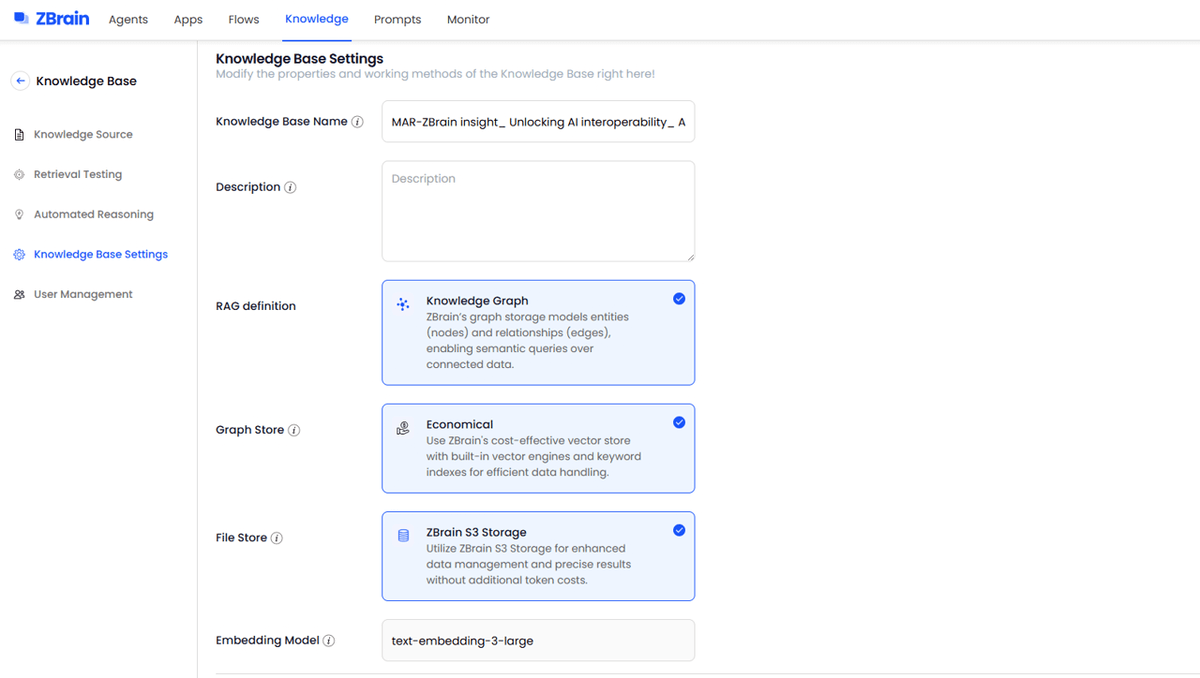
Multi-source ingestion: Import data in various formats—PDFs, JSON, spreadsheets—from multiple sources like databases and cloud storage.
Incremental chunk ingestion: ZBrain supports graph-RAG knowledge bases where individual content chunks can be appended. This enables you to expand the knowledge graph over time, adding new data without requiring the re-upload or reprocessing of the entire dataset.
Semantic and hybrid search: Offers vector, full-text, and graph-based retrieval with configurable thresholds and K-values.
Retrieval testing: Validates the relevance and quality of retrieved chunks before pipeline deployment.
Using ZBrain for scaffolding
ZBrain Builder allows enterprises to create and customize agents by integrating their own data sources and configuring tools, workflows, memory settings, and logic through an intuitive interface. Users can build custom agents from scratch or customize pre-built agents, then visually orchestrate them using the Flow interface. ZBrain enforces standardized communication protocols (RESTful APIs/OpenAPI), allowing agents to function as modular, plug‑and‑play components. In essence, ZBrain Builder acts as the scaffolding layer—providing orchestration, agent catalog, and a unified knowledge base (vector + graph)—where LLM agents are configured, connected, and managed as part of structured workflows. For example, an organization can build an AI-based regulatory monitoring solution by chaining agents that monitor legislative documents, summarize updates, and alert compliance teams—all with low-code configuration.
In summary, ZBrain Builder allows teams to build, test, and deploy scaffolded agents without building scaffolding infrastructure from scratch, ensuring speed, reliability, and auditability in complex AI workflows.
Challenges, limitations, and best practices
While powerful, agent scaffolding comes with important pitfalls. Some key challenges include:
- Unpredictable or unsafe behavior: If not properly constrained, agents can behave erratically or execute unintended actions. Allowing LLMs to take actions (e.g., call code, browse the web) means that any flaws in their understanding can lead to errors—or even malicious behavior. Without guardrails, an agent might repeat actions in loops or execute harmful commands. Mitigation often requires human-in-the-loop checkpoints or safety filters.
- Complexity and debugging difficulty: Multi-agent systems are hard to monitor. When several LLMs interact, logs can be confusing, and it may be unclear why one agent made a decision. Debugging agent interactions is often hard. State management (ensuring each agent sees the right memory/context) adds complexity. Best practice is to log every agent decision and maintain clear task breakdowns.
- Token and context limits: LLMs have finite context windows. Long-running scaffolds risk overflowing prompts with history. Agents must intelligently prune or summarize memory. Frameworks vary in how they manage context; developers should design concise prompts and use vector databases to offload old data.
- Data silos and integration: Many scaffolds rely on integrated data sources and tools. Setting up connectors (to databases, APIs, enterprise systems) can be labor-intensive. Poor integration can make the agent fragile. It’s essential to establish a robust abstraction layer (similar to Anthropic’s Model Context Protocol) so that agents can safely interact with tools without compromising credentials or violating business rules.
- Cost and performance: Multi-step agent workflows can trigger several LLM and tool calls, especially when reasoning is distributed across multiple agents. This can lead to increased latency and usage costs. The exact number of calls depends on the agent’s architecture, with complex processes potentially resulting in dozens of interactions per task. Enterprises should optimize prompts, consider using smaller models for less complex tasks, and evaluate on-premise or cost-efficient model hosting options to maintain scalability.
- Security and compliance: Granting agents tool access (such as email or financial systems) introduces security risks. There must be strict input validation, logging of all actions, and the establishment of audit trails. Frameworks often lack built-in auditing, so teams should add their own controls (e.g., token bucket limits, access controls).
- Model limitations: While agents rely on the underlying LLM for reasoning, their overall effectiveness is shaped by how well they’re scaffolded with tools, memory, and orchestration logic. Difficult logic or knowledge gaps can cause failure. Tasks should be decomposed so that no single agent call requires enormous reasoning leaps.
Best practices for scaffolded agents include:
- Define clear objectives and scope: Start with a precise goal and success criteria for the agent. Vague ambitions lead to scope creep.
- Break tasks into steps: Decompose complex tasks into sub-tasks that the LLM can handle (as in chain-of-thought or Factored Cognition). Use separate agents or prompts for planning vs execution.
- Separate logic from memory: Keep agent logic (such as prompt templates and flow control) distinct from retained knowledge (stored facts, documents, or records). Use structured memory—like vector databases or programmatic data stores—to retain this information and only send relevant context to the LLM. This approach keeps the system inspectable and avoids unnecessary model load.
- Use interpretable intermediate outputs: Encourage agents to reason in text or code that can be audited. Most of an LLM’s reasoning occurs internally and is not directly interpretable, whereas reasoning managed by the agent scaffold—such as planning, tool use, or memory access—is transparent and easier to debug. For example, have agents list their reasoning steps or log reasoning to a file. This makes behaviors easier to trace.
- Implement safety checks: Incorporate validators or critics at key junctures. For instance, before executing an agent’s action, run a secondary check (another model or ruleset) to approve it. Limit agent loops with max-iteration counters or termination controls such as kill switches.
- Leverage modular tools: Provide agents with well-defined, task-specific tools and APIs. The scaffold should translate high-level agent decisions into function calls that are validated and controlled, ensuring safe and predictable execution. Design these tool interfaces clearly (document parameters and outputs) so the LLM uses them correctly.
- Monitor and log aggressively: Record every agent input/output, tool calls, and system decisions. Use dashboards or alerts for failures. This not only aids debugging but also helps in aligning behavior with expectations.
- Iterate and test with feedback: Continuously refine prompts and flows based on failure cases. Pushing the LLM to its limits during testing exposes latent capabilities or failure modes.
- Control chain-of-command: If multiple agents collaborate, restrict unnecessary autonomy. For example, use a hierarchy or enforce an SOP (standard operating procedure) so agents call each other in a safe, predictable order (as MetaGPT does by simulating team roles).
- Align with enterprise governance: Especially for corporate use, agents should comply with policies (data handling, privacy). Any external calls or data retrieval must follow compliance rules. The scaffolding layer can enforce these (e.g., by sanitizing user input or masking private info).
By following these practices, teams can harness scaffolding to build more reliable AI agents. Documentation and training are also crucial: ensure that developers and stakeholders understand the agent architecture and know how to intervene if something goes wrong.
Where scaffolding architecture is heading
Two shifts will define the next 24 to 36 months of agent scaffolding.
The first is the convergence of multi-modal inputs with long-horizon reasoning. Today’s scaffolds are mostly text-first, with image and voice handled as bolt-ons. Production agentic systems increasingly need to reason across structured data, documents, images, video, and voice within a single goal pursuit. The scaffolds that support this convergence will treat modality not as a separate concern but as a property of memory, context, and tool integration that propagates through every layer of the loop.
The second is the shift from prompt-engineered scaffolds to compiled scaffolds. Today’s scaffolds are largely hand-tuned: prompts are written, chains are configured, and validation rules are coded. The next generation of scaffolding will be partially compiled, with prompt structures, retry policies, validation schemas, and even agent topologies generated and optimized programmatically against measured outcomes rather than written by hand. Frameworks pursuing this direction (DSPy and its successors) treat the scaffold itself as an artifact that can be optimized under a defined objective. The implication for enterprise teams is significant: scaffolds will become more reliable as they become less artisanal, and the role of the human designer will shift from writing scaffolds to specifying the outcomes the scaffold should achieve.
What does not change is the core architectural insight. The scaffold is what turns an LLM into a reliable agent. Whether it is hand-tuned or compiled, whether it operates over text or across modalities, whether it runs in HITL or HOOTL mode, the scaffold is the system. Enterprises that treat scaffolding as a first-class architectural concern, rather than as plumbing around the model, will be the ones whose agentic deployments scale.
Endnote
Agent scaffolding is no longer just a research concept—it’s the practical foundation behind enterprise-ready AI agents. From simple task wrappers to multi-step reasoning loops and memory-driven workflows, the scaffold determines how intelligently and reliably a model can operate in real-world settings.
Understanding different scaffold types helps teams design agents that are not only accurate but also maintainable and aligned with business objectives. Whether you’re exploring prompt templates, retrieval-based augmentation, or full agent loops with planning and tool use, the scaffolding you choose will directly impact the agent’s success.
ZBrain provides the full scaffolding infrastructure required to move from experiments to production. Whether you are building a single-agent flow or deploying a multi-agent system with memory and external integrations, ZBrain offers the modular control, transparency, and scalability needed to support real-world AI outcomes.
Leverage ZBrain Builder to design, test, and deploy scaffolded agents that work with your data, tools, and workflows. Start building today.
Listen to the article
Author’s Bio


CEO LeewayHertz
An early adopter of emerging technologies, Akash leads innovation in AI, driving transformative solutions that enhance business operations. With his entrepreneurial spirit, technical acumen and passion for AI, Akash continues to explore new horizons, empowering businesses with solutions that enable seamless automation, intelligent decision-making, and next-generation digital experiences.
Table of content
- What is agent scaffolding?
- What is agent scaffolding?
- Origins and evolution of the concept
- Types of agent scaffolds
- Core scaffolding components and architecture
- Long-horizon task scaffolding
- Inter-agent coordination scaffolding
- Tool scaffolding for dynamic environments
- Functional scaffolding techniques
- Scaffold-level guardrails
- Scaffold-level observability
- Human oversight scaffold patterns
- Agentic design patterns
- Agentic failure modes in the scaffold
- Use cases and examples of agent scaffolding
- ZBrain Builder: A platform for building scaffolded agents at enterprise scale
- Challenges, limitations, and best practices
- Where scaffolding architecture is heading
Share Article


Frequently Asked Questions
What is agent scaffolding in AI?
Agent scaffolding refers to the supporting architecture and logic built around a large language model to enable it to act as an agent. This includes structured prompts, control flows, memory modules, tool interfaces, and decision loops that help the model perform complex tasks reliably.
How does ZBrain support agent scaffolding?
ZBrain offers a low-code interface for building and deploying LLM agents with configurable scaffolding. Users can define planning logic, memory use, tool access, and multi-agent workflows without extensive coding. ZBrain also supports enterprise integration, role-based access, and model flexibility, making agent scaffolding easier to manage at scale.
Can ZBrain agents interact with external tools or APIs?
Yes. ZBrain agents can access and interact with external tools, APIs, and enterprise systems like CRMs and ERPs. Tool use is managed through ZBrain’s Flow interface, where each step in the agent’s workflow can be set up to invoke specific tools as needed. Through the platform interface, users can define which tools an agent can access at each step—without writing backend code.
For multi-agent workflows built using Agent Crew, ZBrain’s MCP ensures that only relevant tool responses and context are passed to the LLM at each stage. This helps keep executions efficient, avoids unnecessary token usage, and ensures tighter control over what the model processes.
Does ZBrain support multi-agent scaffolds?
Yes. ZBrain supports Agent Crew, a multi-agent scaffold structure where a supervisor agent coordinates multiple specialized subordinate agents. Each agent can have its own toolset and MCP server integration. This is useful for complex workflows that require task decomposition and coordination.
How do we get started with ZBrain for AI development?
To begin your AI journey with ZBrain:
-
Contact us at hello@zbrain.ai
-
Or fill out the inquiry form on zbrain.ai
Whether you have a clear scope or just an idea, our team will guide you from strategy to execution.
Insights
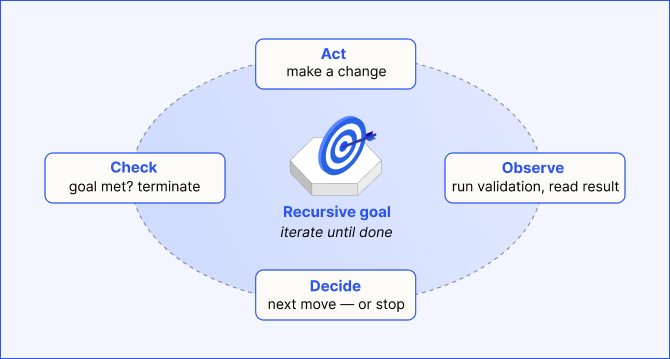
Loop engineering for AI agents: Building reliable autonomous systems
Loop engineering is the practice of designing, operating, and improving the feedback systems that let an AI agent plan, act, observe the results, and revise its approach until a goal is reached without a human driving every turn.
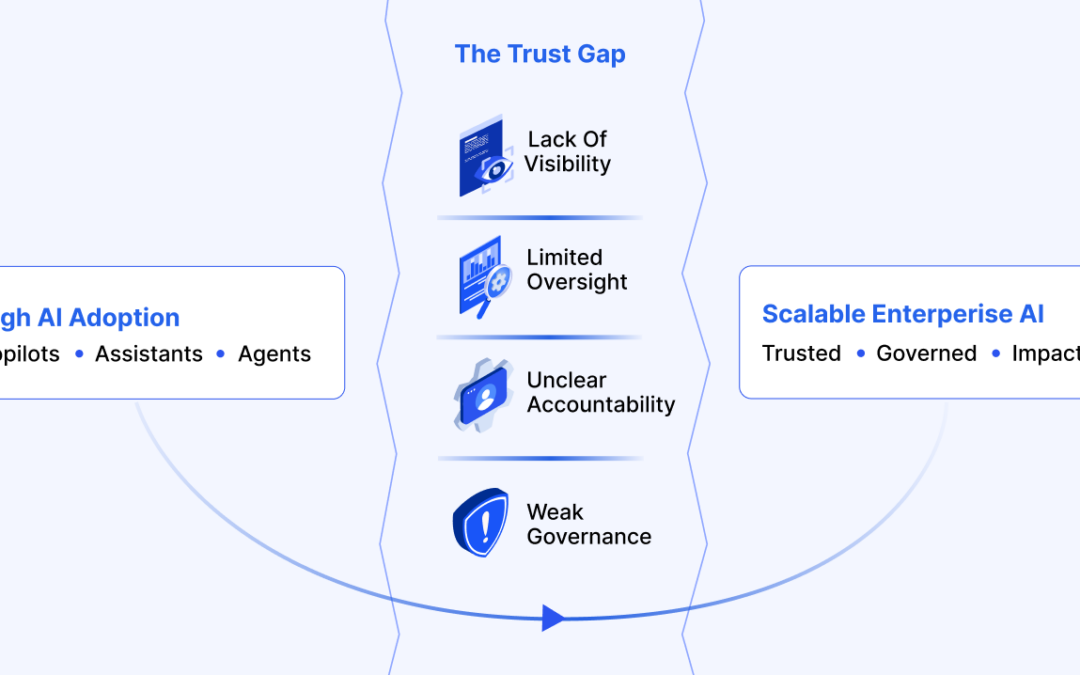
The AI trust gap: Why governance architecture determines enterprise value
The trust gap surrounding enterprise AI is fundamentally an architectural challenge, and its solution is increasingly well understood.
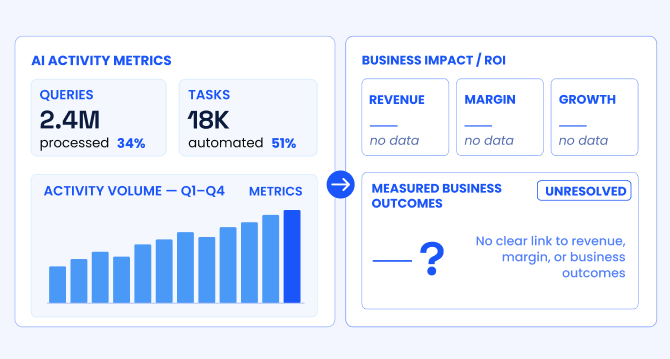
The AI ROI illusion: Why enterprises struggle to measure AI impact
Organizations with stronger measurement discipline are better positioned to link AI deployments to measurable business outcomes, prioritize high-impact use cases across the enterprise, allocate capital more effectively, and continuously refine models using real-world performance feedback.
The agentic enterprise: Why AI success requires an operating model redesign
Organizations that redesign their operating models around agentic AI are beginning to outperform those that apply AI only incrementally.
Enterprise AI pilot-to-production gap: Root causes & how to address them
The underlying cause is structural. In many enterprises, AI pilots are developed on infrastructure that was not designed to support production deployment.
Solution architecture best practices: A guide for enterprise teams
The architecture design process culminates in a set of documented artifacts that communicate the solution to development, operations, and business teams.

Common solution architecture design challenges and solutions
Solution architecture must evolve from fragmented documentation practices to a structured, collaborative, and continuously validated design capability.

Why structured architecture design is the foundation of scalable enterprise systems
Structured architecture design guides enterprises from requirements to build-ready blueprints. Learn key principles, scalability gains, and TechBrain’s approach.
Intranet search engine guide: How it works, use cases, challenges, strategies and future trends
Effective intranet search is a cornerstone of the modern digital workplace, enabling employees to find trusted information quickly and work with greater confidence.
