


Context engineering: The control plane of agentic AI

Listen to the article
As enterprises move beyond experimentation with large language models (LLMs), a new paradigm is emerging: agentic AI. Organizations are no longer satisfied with chat-based assistants that generate responses on demand. They are seeking autonomous systems capable of perceiving events, planning multi-step actions, invoking tools, collaborating across workflows, and operating continuously within defined governance boundaries.
This shift marks a transition from conversational AI to autonomous operational AI.
While generative AI holds immense economic promise—estimated by McKinsey to unlock trillions of dollars in annual value—the real enterprise impact lies not in isolated prompts, but in intelligent agents embedded within business processes. Customer operations, marketing, sales, software engineering, compliance, and R&D increasingly require AI systems that do more than respond. They must reason across multiple steps, maintain memory over time, integrate live business data, and execute actions safely and consistently.
Yet many organizations discover that off-the-shelf LLM deployments fall short in real-world enterprise scenarios.
Why? Because LLMs alone are not autonomous systems.
Large language models are inherently stateless, reactive, and probabilistic. They generate outputs based solely on the immediate input they receive. In simple interactions, this may suffice. But in multi-step workflows—where tasks span multiple decisions, tools, data sources, and compliance checkpoints—static prompts break down. Context fragments. Memory is lost. Policies are bypassed. Tool usage becomes unreliable. The result is brittle automation rather than dependable autonomy.
This is where context engineering becomes foundational. In the era of agentic AI, context engineering is not merely about crafting better prompts—it is about designing the control plane of autonomous systems. It determines what the agent perceives, what it remembers, how it reasons, which tools it may invoke, and when it must escalate to human oversight. It orchestrates dynamic knowledge retrieval, memory persistence, workflow state management, governance injection, and auditability across every reasoning loop.
An enterprise agentic orchestration platform like ZBrain Builder was designed with this agentic vision at its core. By integrating robust knowledge systems, structured memory architectures, event-driven orchestration, tool governance, and multi-agent collaboration frameworks, ZBrain Builder enables enterprises to deploy intelligent agents that detect, decide, and act—while remaining aligned with business data, policies, and operational safeguards.
In the sections that follow, we examine how context engineering serves as the backbone of agentic AI systems—and how ZBrain’s architecture transforms LLMs from reactive chat interfaces into scalable, governed, enterprise-grade autonomous agents.
- What is context engineering, and why does it matter for LLMs?
- Core principles of context engineering in enterprise AI
- Key techniques and approaches in context engineering
- Tools, frameworks, and systems supporting context engineering
- Why agentic AI fails without engineered context
- Context engineering as the backbone of agentic systems
- Engineering contextual memory for enterprise agents
- Retrieval as dynamic perception (Beyond RAG)
- Orchestration: Coordinating agents, tools, and decisions
- ZBrain’s robust knowledge bases: Delivering relevant, real-time context
- Agentic framework of ZBrain: Enabling autonomous intelligence
- Bringing it all together: Dynamic context management in action
- BriThe future: Context as the enterprise AI control plane
What is context engineering, and why does it matter for LLMs?
Context engineering is the practice of designing systems that determine what information a large language model (LLM) sees before generating a response. Instead of relying on a single static prompt, context engineering builds dynamic pipelines that feed the LLM all the data, instructions and history it needs to perform effectively. In other words, if prompt engineering is about asking the right question, context engineering is about ensuring the LLM has the necessary knowledge, background and tools to answer that question correctly.
This discipline has become crucial because modern LLMs, while powerful, are essentially stateless text predictors – they do not interpret context beyond input; they read tokens. An LLM’s output quality depends heavily on the input context provided. Without sufficient context (such as facts or prior interactions), even state-of-the-art models can hallucinate or return irrelevant answers. Experts now consider supplying the model with the right context as the top priority in AI system design – far more important than crafting clever prompts.
In practical terms, context engineering means assembling all necessary pieces of information for the LLM at runtime in a coherent format. This often includes:
-
System instructions: Overarching rules or role definitions that guide behavior (e.g., tone, compliance requirements).
-
Conversation history and user context: Memory of prior conversation, user preferences or session data to maintain continuity.
-
Relevant knowledge from databases/documents: Retrieved facts or documents pulled from a knowledge base or APIs, especially information not in the model’s training data.
-
Tool definitions and outputs: Details of tools like an MCP server, the LLM can use, plus their results, so the model can incorporate computations or external actions.
-
Output format guidelines: Schemas or templates (e.g., JSON, report outlines) that shape responses.
-
Real-time data: Up-to-date information from external sources or sensor readings.
Why context matters
Without engineered context:
-
LLMs hallucinate or miss key business logic.
-
Domain-specific language or policy nuances are misunderstood.
-
Outputs are inconsistent across users, sessions and channels.
-
Autonomous agents struggle to maintain memory across multistep tasks.
With effective context engineering:
-
Responses are accurate, traceable and aligned with enterprise standards.
-
AI agents can reason, act and collaborate over extended workflows.
-
Systems remain grounded in live business knowledge.
-
Compliance, safety and brand tone are enforced through structured instructions and guardrails.
At its core, context is the bedrock of intelligence—anchoring AI systems in relevant knowledge and ensuring that their outputs remain grounded, accurate, and trustworthy. Just as a human assistant needs access to documents, past conversations and protocols, an LLM needs engineered context to behave competently.
From static prompts to dynamic intelligence
As the role of LLMs shifts from chat-based assistants to autonomous, task-oriented agents, static prompt templates are no longer enough. Enterprises must now build systems that can:
-
Retrieve relevant knowledge dynamically.
-
Apply structured policies and business rules.
-
Maintain short- and long-term memory across tasks and users.
-
Select appropriate tools and APIs for execution.
This calls for a scaffolded approach, where the LLM is supported by orchestration layers that assemble and inject the right context, route tasks ,and enforce boundaries. This orchestration spans multiple levels – from data retrieval and prompt construction to memory integration and agent-level autonomy. Done well, it enables LLM apps to behave less like chatbots and more like intelligent systems embedded in enterprise workflows.
Context engineering as a strategic imperative
Context engineering is not a technical afterthought; it is a strategic requirement. It is what turns an impressive demo into a scalable, safe and value-generating AI deployment. Without it, enterprises risk:
-
Underdelivering on AI investments due to brittle performance.
-
Compromising security, compliance or factual integrity.
-
Losing trust from users or customers due to inconsistent behavior.
By contrast, organizations that invest in robust context engineering can:
-
Build LLM systems that understand their business from inception.
-
Scale across teams and domains with consistency and transparency.
-
Empower AI agents to act autonomously – while staying aligned with defined goals and policies
In the following sections, we explore how ZBrain Builder operationalizes context engineering through the following means:
-
Robust knowledge bases that ensure every decision is grounded in current enterprise data.
-
An agentic framework that enables autonomous, goal-driven execution with transparency and guardrails.
Together, these capabilities form the foundation of a context-aware AI architecture, unlocking productivity gains while maintaining enterprise control.
Core principles of context engineering in enterprise AI
Effective enterprise AI does not just depend on powerful models – it relies on how well context is engineered around those models. Context engineering defines what information is provided to the LLM, how it is grounded in enterprise knowledge and how it adapts dynamically to workflows and compliance needs. By carefully managing context, organizations ensure AI agents operate with accuracy, reliability and traceability, turning raw data into actionable intelligence while minimizing risks such as hallucinations or policy violations.
Core principles of context engineering
-
Information relevance: Provide only task-critical information so the LLM’s reasoning remains focused. Enterprise AI agents avoid dumping entire databases into prompts; instead, they filter and include only the facts, documents or tool outputs needed for the query. In practice, context pipelines dynamically fetch and insert information most likely to help answer the request, often via search or retrieval mechanisms.
-
Grounding and factuality: Responses must be grounded in accurate, up-to-date data to avoid hallucinations. Supplying authoritative enterprise knowledge – such as documents, knowledge bases or CRM data – prevents the model from guessing. Verifiable sources reduce hallucinations and build user trust.
-
Dynamic retrieval of knowledge: Enterprise systems use retrieval-augmented generation (RAG) and similar techniques to pull in external knowledge on demand. When a query requires specific data, the system searches across corporate repositories or databases and injects relevant snippets into the prompt. This ensures the context window contains fresh, domain-specific information and, when enabled, provides traceability to the sources.
-
Context-aware planning: Advanced AI agents plan actions with context awareness, tracking multistep tasks and adjusting based on user input and past interactions. Instead of answering in isolation, the agent considers conversation history, goals and tools. This enables agentic behavior – breaking down tasks, calling external tools, using results in further reasoning – while avoiding repetition or loss of objectives. In practice, this might mean not only answering a question but also creating a ticket or triggering a follow-up action.
-
Memory handling (short- and long-term): Because enterprise conversations can be lengthy, context engineering requires memory strategies. LLMs have finite context windows, so systems separate short-term memory (recent interactions) from long-term memory (persistent knowledge).
-
Compliance and governance: Enterprise AI must meet security, privacy and regulatory requirements. In context engineering, compliance is enforced by filtering out sensitive data, applying role-based access controls to determine what information can be injected into prompts, and embedding policy rules in system instructions (for example, “do not reveal customer PII”). Agents can operate autonomously within defined guardrails, typically involving human checkpoints for critical actions. Many systems also add content filters or moderation steps to review outputs, blocking or escalating responses that violate policy. This ensures workflows remain trustworthy and aligned with organizational standards.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
Key techniques and approaches in context engineering

Building on those principles, practitioners have developed several techniques to implement a dynamic and robust context for LLMs:
-
Retrieval-Augmented Generation (RAG): RAG is a foundational technique where the system queries external knowledge sources and augments the prompt with relevant information before generating a response. For example, given a user question, an enterprise assistant might embed the query, find the top-matching documents from a vector database or search engine, and supply those passages to the LLM as context. This grounding in retrieved data enables the model to produce more accurate, context-specific answers (e.g., quoting a product manual or policy text) rather than relying on general training knowledge. RAG drastically expands an LLM’s effective knowledge without retraining the model, and is preferred in enterprise settings for its security, scalability, and transparency. The model uses a curated private knowledge base at query time, which is easier to secure and update than fine-tuning the model on sensitive data. Many platforms, including ZBrain, center their architecture on RAG to ensure up-to-date corporate data.
-
Prompt orchestration and advanced prompting: Rather than a single static prompt, enterprise AI uses orchestrated prompting, assembling multiple context components and even making multiple LLM calls in sequence. This includes techniques such as Chain-of-Thought prompting, where the system guides the model to reason step-by-step (possibly by showing examples of reasoning) to enhance accuracy. It also includes self-reflection or self-critique prompts, where the model’s first answer can be fed back into a prompt asking it to double-check or improve its solution.
Prompt orchestration means the final prompt to the model is dynamically built from components: e.g., a system instruction with role and rules, a summary of recent conversations, and relevant retrieved facts, each placed in a structured template. Some orchestration frameworks allow conditional prompting – the workflow can branch, calling one prompt or another based on context (For instance, the system might select one prompt template for financial queries and a different one for IT troubleshooting queries). This dynamic assembly ensures all necessary instructions and data are present every time the model runs, enabling it to handle complex queries and multi-turn conversations reliably.
-
Dynamic context window management: Since LLMs have fixed context limits (e.g., 4K, 16K, or more tokens), enterprise systems employ strategies to manage the context window dynamically. One tactic is sliding windows or buffers for recent dialogue: as a conversation grows, older turns are dropped or compressed to keep the prompt length under the limit while preserving recency. Another tactic is hierarchical summarization – condensing earlier parts of a chat or a long document into a shorter summary that remains in context, rather than the full text. For example, after many turns, the system might replace the beginning of the conversation with “Summary of earlier discussion: …” so that important context is not lost. These summaries can be updated iteratively as the conversation proceeds. Additionally, the system may prioritize which information to retain: critical facts and user instructions may be pinned in context, while trivial chit-chat is discarded. By intelligently managing what stays in the prompt vs. what moves to long-term memory, the AI solution can handle essentially unlimited-length interactions in a rolling manner. This dynamic approach prevents context overflow and mitigates issues like context poisoning (where irrelevant, misleading, or malicious data is injected into the context, altering the model’s reasoning) or confusion from irrelevant, stale data, thereby maintaining answer quality even in lengthy sessions.
-
Memory management (Short-Term vs. Long-Term): Complementary to window management is the explicit use of memory systems. Short-term memory usually refers to the immediate interaction history (often handled by keeping a buffer of recent messages), whereas long-term memory involves storing information outside the prompt for later retrieval. Techniques here include writing conversation transcripts or facts to a vector store as they occur, enabling the agent to query its own memory when needed (sometimes called conversation memory retrieval). For instance, after a support chat session, the agent might embed key points of the conversation into a memory database. Later, if the user returns, the agent can retrieve those points to remember context (e.g. past issues the user faced).
Another memory method is using knowledge graphs or databases to log confirmed facts (e.g. storing that “User X’s preferred language is French” in a profile store). When new queries come in, the system checks these stores and injects relevant remembered data into the context. Overall, effective memory handling means the AI solution not only processes the current prompt, but also “learns” from past interactions and carries that forward appropriately – crucial for enterprise assistants that users interact with over time.
-
Multi-turn context flows: Enterprise LLM applications often involve multi-turn conversations or multi-step workflows, requiring the AI solution to maintain context across iterations and coordinate complex sequences of actions. Context engineering for multi-turn flows includes tracking the state of the conversation or task (what the user has asked, what sub-goals have been completed, what remains). One approach is the ReAct pattern of reasoning and acting, where the agent alternates between internal reasoning (formulating sub-steps) and external execution (taking actions such as calling a tool) in a continuous cycle. Each iteration’s outcome (an observation from the tool) is fed back into the context for the next step, enabling multi-step reasoning that spans multiple turns.
Another approach is explicit workflow state tracking: e.g., an agent might keep a JSON object or variables that persist throughout the interaction to record progress, which the LLM can be instructed to update or read. Context flows also benefit from agent frameworks that support conditional branching and iterative reasoning cycles—for example, asking the model if it has answered the question or needs more info, and looping back to retrieval if needed. This is sometimes referred to as an agent reasoning loop, where the model can trigger the use of a follow-up tool. Ensuring continuity in these flows may involve re-injecting key context at each turn (like the original question or the running list of completed steps) so the model doesn’t lose sight of the bigger task.
-
Semantic chunking of knowledge: A practical technique in enterprise context engineering is semantic chunking, which involves breaking down large documents or data into semantically coherent, smaller pieces (chunks) during the ingestion process. These chunks (e.g., a paragraph or section that represents a complete thought) are each indexed in a vector store with metadata like source or tags. Chunking ensures that when the AI solution performs retrieval, it retrieves only the most relevant pieces of information, rather than entire files. This optimizes both relevance and token efficiency. For example, instead of feeding a 50-page policy manual to the model, the system might store thousands of chunks (each maybe a few sentences) and only retrieve the top 3–5 chunks that relate to the user’s query. Those chunks can be concatenated as context, providing focused knowledge. Semantic chunking also aids in dynamic retrieval strategies – the system can decide how big a context to retrieve (maybe more, smaller chunks vs. fewer large ones) depending on the query. ZBrain Builder’s knowledge ingestion pipeline performs explicit chunk-level optimization, splitting content and tagging it to ensure fast and precise retrieval. Combined with vector search, this chunking avoids overloading the prompt with irrelevant text and helps maintain the logical coherence of the provided context.
Tools, frameworks, and systems supporting context engineering
To implement these techniques at scale, enterprise AI teams rely on a range of tools, frameworks, and system components:
Vector databases and knowledge repositories
Vector databases (such as Pinecone, Weaviate, Chroma or Milvus) store high-dimensional embeddings of text, enabling semantic search. Given an embedded query, the database returns the most similar stored embeddings—chunks of documents, past conversations and more—that provide relevant context. This forms the backbone of retrieval-augmented workflows: a well-populated vector DB serves as the AI’s extended memory of enterprise knowledge. Many platforms, including ZBrain Builder, are storage-agnostic, supporting multiple vector stores or retrieval methods, such as hybrid search, which combines semantic and keyword methods. Some systems also incorporate knowledge graphs or relational databases to enforce business logic (such as manager hierarchies or product taxonomies). Together, these repositories allow the AI system to fetch both unstructured context and structured facts, dramatically reducing hallucinations and improving performance on complex queries.
LLM orchestration frameworks
To manage multi-step interactions and assemble context, developers use orchestration frameworks. LangChain is a leading example, offering abstractions for chaining LLM calls, tracking conversation state and injecting retrieval results. It also supports agent paradigms like ReAct, enabling models to choose actions and use tools. LlamaIndex (formerly GPT Index) focuses on indexing data for retrieval and provides high-level APIs for knowledge graphs and memory. Enterprise platforms such as ZBrain Builder integrate these capabilities into a cohesive orchestration layer: model-agnostic, capable of routing queries to different models, and able to coordinate sequences of prompts and tools. Other frameworks, including Microsoft’s Guidance, OpenAI Functions and emerging agent SDKs, support declarative scripting of how context is gathered and how models are invoked. The goal is to abstract away raw prompt assembly and tool usage so developers can focus on task design.
Agent frameworks and tool integration
Enterprise context engineering often requires giving LLMs controlled access to external tools (APIs, databases, calculators and more). Frameworks such as LangChain Agents, OpenAI function calling and open-source projects like Auto-GPT, Microsoft AutoGen and MetaGPT provide patterns for this. In a tools-enabled setup, the AI solution receives not only text but also a list of available actions. If the model calls a tool, the framework executes it and feeds the result back into the model for further reasoning. This thought → action → result loop allows agents to incorporate external capabilities like math, real-time search or company database queries. ZBrain Builder’s agent module, for instance, lets Flows include steps that query databases, call APIs and integrate results into models’ reasoning. By combining LLMs with tool use, enterprise agents gain the power to both reason and act, grounded by context engineering that guides when and how to use those tools.
Memory stores and persistence systems
In addition to on-the-fly retrieval, enterprises often maintain long-term memory systems. Vector DBs can double as long-term memory by storing embeddings of past interactions or conclusions. Some systems use key–value stores or caches to recall prior outcomes quickly. Document summarization and indexing pipelines (including OCR for PDFs and cognitive search services) prepare corporate data for use. Platforms like ZBrain Builder automate ETL for documents, enforce security during processing and store results in the knowledge base. Together, ingestion pipelines, vector indexes and memory-optimized databases form the context supply chain. Without a robust knowledge base and memory layer, even the most advanced LLMs falter on enterprise queries.
Governance, monitoring and feedback tools
To maintain trust and performance, enterprises employ evaluation suites, guardrails and human feedback loops. Some systems use a second LLM to evaluate the first model’s output against known facts or compliance rules (“AI judges”). Guardrail libraries, such as Microsoft Guidance, enforce allowed formats and block disallowed content via prompts or post-processing checks. ZBrain Builder integrates feedback loops where users can rate or correct answers; admins can then refine retrieval strategies or update the knowledge base. Monitoring dashboards provide visibility into logs, tool usage and metrics, helping developers trace errors and tune context pipelines. These governance tools support auditability, safety and continuous improvement—core requirements for enterprise-grade AI.
Why agentic AI fails without engineered context
The promise of agentic AI lies in autonomy—systems that can reason, plan, act, and adapt across complex enterprise workflows. However, autonomy without an engineered context is inherently unstable. When context is poorly structured, incomplete, or unmanaged, agentic systems become unpredictable, inconsistent, and difficult to govern.
Understanding why agentic AI fails without engineered context is critical for enterprises seeking to deploy agents at scale reliably.
Stateless LLM limitations
At their core, large language models are stateless predictors. They do not retain intrinsic memory of prior interactions, decisions, or environmental changes beyond what is explicitly provided in the input. While this limitation may be manageable in single-turn conversations, it becomes a structural weakness in autonomous systems.
Agentic workflows require continuity—awareness of past actions, evolving objectives, user intent, compliance constraints, and intermediate outputs. In the absence of engineered context orchestration, agents operate in isolation at every step, resulting in fragmented reasoning and inconsistent outcomes.
Autonomy requires statefulness. LLMs alone do not provide it.
Hallucination amplification in autonomous systems
In agentic systems, hallucinations can trigger incorrect actions.
When agents are empowered to call APIs, update databases, generate reports, or initiate downstream workflows, inaccurate reasoning is no longer a minor inconvenience—it becomes operational risk. Without grounded retrieval, policy injection, and validation mechanisms, unverified assumptions can propagate across tool calls and multi-step execution chains—compounding errors and amplifying hallucinations.
Autonomous systems amplify errors unless they are continuously anchored in an authoritative enterprise context.
Context drift across multi-step reasoning
Agentic AI operates through iterative reasoning loops—perceive, plan, act, observe, update. Over multiple steps, context must remain coherent and aligned with the original objective.
Without structured context management, agents experience drift:
- Objectives subtly change.
- Key constraints are forgotten.
- Earlier decisions are not reconciled with new information.
- Irrelevant data accumulates in the context window.
This degradation may be subtle at first, but compounds over long-running workflows. The result is drift from intended task objectives and misalignment with business intent.
Engineered context ensures that critical goals, policies, and state variables persist across reasoning cycles, preventing deviation from defined objectives.
Tool misuse and ungoverned execution
Agentic AI systems derive power from diverse tool integration—databases, APIs, collaboration tools, messaging systems, workflow engines. However, tool access without structured governance introduces risk.
Without context-aware guardrails, which are dynamic policy controls that adapt to the task, user role, and situation to ensure agents use the correct tools, protect sensitive data, and operate within approved authority:
- Agents may call the wrong tool for a task.
- Sensitive data may be exposed inadvertently.
- Execution may occur without appropriate approvals.
- Actions may exceed the defined scope or authority.
Context engineering defines not only what the agent knows, but what it is permitted to do. It embeds role-based controls, policy constraints, execution conditions, and human-in-the-loop checkpoints directly into the reasoning framework.
Memory fragmentation across sessions
Enterprise workflows rarely occur in isolation. Agents must maintain continuity across sessions, users, departments, and timeframes. Without deliberate memory architecture, context fragments:
- Past interactions are forgotten.
- User preferences are lost.
- Previously resolved issues resurface.
- Institutional knowledge remains siloed.
Fragmented memory undermines trust and reduces operational efficiency. More critically, it prevents agents from evolving and improving over time.
Engineered memory systems—spanning short-term working memory and long-term persistent memory—enable agents to retain relevant knowledge while discarding noise. This continuity transforms isolated interactions into coherent, evolving operational intelligence.
In agentic AI, context is not a supporting feature—it is the structural foundation of autonomy. Without engineered context, agents remain reactive, error-prone, and difficult to control. With it, they become reliable digital operators capable of sustained reasoning, governed execution, and enterprise-scale impact.
Context engineering as the backbone of agentic systems
Agentic AI systems are defined by their capacity to operate with autonomy—perceiving their environment, reasoning across multi-step objectives, invoking tools, collaborating with humans, and executing decisions within enterprise constraints. Yet autonomy does not arise from model capability alone; it is the product of disciplined system architecture.
At the center of that architecture lies context engineering.
In agentic systems, context is not merely an input to a model. It is the structural foundation that enables coherent reasoning, safe execution, and sustained operational intelligence. It determines what the agent perceives, what it retains, how it evaluates decisions, and when it must defer to policy or human oversight.
Context, therefore, constitutes the infrastructure of autonomy.
Context as a perception layer
Every autonomous system must first perceive its environment. For AI agents, perception is not sensory—it is informational.
Context engineering defines how agents ingest and interpret:
- User inputs
- Event triggers
- Retrieved enterprise knowledge
- System state variables
- Tool outputs and environmental feedback
Through structured retrieval, semantic indexing, and real-time data integration, context becomes the agent’s perception layer—transforming raw enterprise data into actionable awareness. Without this engineered perception, agents operate without contextual awareness, relying on incomplete or outdated information.
In agentic workflows, perception must be dynamic, precise, and continuously refreshed. Context engineering ensures that agents see only what matters at every decision point.
Context as working memory
Autonomous reasoning unfolds over multiple steps. Agents must decompose tasks, track intermediate results, reconcile constraints, and adjust plans based on new information.
This requires working memory.
Context engineering assembles and maintains a short-term state during active workflows, including:
- Current objectives and sub-goals
- Intermediate reasoning outputs
- Tool invocation results
- Active constraints and policies
- Conversation or session history
Without structured working memory, reasoning fragments. Objectives drift. Critical variables are lost. Multi-step execution becomes unstable.
By managing context windows, prioritizing relevant information, and updating state across reasoning loops, context engineering provides the cognitive continuity necessary for complex task execution.
Context as long-term memory
Enterprise autonomy extends beyond single sessions. Agents must retain institutional knowledge, user preferences, historical decisions, and evolving business rules.
Long-term memory systems—vector stores, knowledge graphs, structured databases—serve as persistent extensions of agent intelligence. Context engineering determines how this memory is:
- Stored
- Indexed
- Retrieved
- Validated
- Updated
Persistent memory enables agents to maintain continuity across time, users, and departments. It prevents repetitive interactions, improves personalization, and supports cumulative learning.
In production-grade agentic systems, memory is not incidental—it is engineered, scoped, and governed.
Context as a governance layer of agentic AI
Autonomy without governance is operational risk.
Enterprises require that AI agents operate within clearly defined boundaries—regulatory constraints, data access policies, role-based permissions, brand standards, and escalation rules.
Context engineering embeds these controls directly into the reasoning process. Governance is not layered on after execution; it is embedded directly into the agent’s operational context through:
- Policy-aware system instructions
- Role-based retrieval filters
- Sensitive data masking
- Tool usage constraints
- Human-in-the-loop checkpoints
By integrating governance at the context level, agent behavior remains aligned with enterprise rules at every decision node. This approach ensures compliance is proactive rather than reactive.
Context as execution boundary
Agentic systems derive power from action—calling APIs, updating records, generating reports, triggering workflows. However, every action must be bounded by a defined scope.
Context engineering establishes execution boundaries by controlling:
- Which tools are available
- Under what conditions may they be invoked
- What data may be accessed
- When approvals are required
- How outcomes are validated and logged
These boundaries prevent misuse of tools, unauthorized actions, and execution beyond approved operational scope. They ensure that autonomy operates within deliberate constraints rather than implicit assumptions.
In this sense, context serves as the enforcement layer for execution.
Context as the autonomy infrastructure
When viewed collectively—perception layer, working memory, long-term memory, governance, and execution boundary—context engineering forms the structural backbone of agentic AI.
It is the foundational layer that enables:
- Coherent multi-step reasoning
- Reliable tool integration
- Persistent operational memory
- Policy-aligned decision-making
- Safe and scalable execution
Without engineered context, agentic AI remains reactive and fragile. With it, autonomy becomes structured, auditable, and enterprise-ready.
In the era of operational AI, context is not an accessory to intelligence. It is the infrastructure that enables autonomy.
Engineering the context lifecycle of agentic AI systems
At the center of the agentic AI process flow lies a dynamic context lifecycle—a disciplined sequence through which information is assembled, decisions are made, actions are executed, and state is updated.
Understanding this lifecycle is essential to designing reliable autonomous systems.
In enterprise-grade agentic AI, context is not static. It evolves at every stage of execution.
Event detection
Every agentic workflow begins with a trigger.
This trigger may be:
- A user request
- A system-generated alert
- A scheduled task
- A new data entry
- An external event (e.g., ticket creation, document upload, transaction anomaly)
Event detection activates the agent and defines the initial operational scope. At this stage, the system determines the required workflow type and the contextual components to assemble.
Without structured event handling, agents remain reactive rather than proactive. Event-driven activation transforms AI from a passive responder to an operational participant.
Context assembly
Once triggered, the agent must construct a comprehensive view of the situation.
Context assembly involves gathering and structuring:
- Relevant enterprise knowledge through retrieval mechanisms
- Session history and active objectives
- Role-based access constraints
- Applicable policies and compliance rules
- Tool definitions and available actions
- Historical memory entries, if relevant
This stage determines what the agent perceives before reasoning begins. The key mechanics behind it are signal-to-noise degradation.
Engineered context assembly ensures that the agent begins reasoning with a complete, accurate, and policy-aligned situational picture.
Plan generation
With context established, the agent formulates a structured plan.
Rather than generating a single output, agentic systems decompose complex objectives into logical steps. Planning may include:
- Breaking tasks into sub-goals
- Determining whether additional information is required
- Selecting appropriate tools
- Defining execution order
- Identifying escalation points
Planning transforms raw context into an actionable strategy. It is the bridge between perception and execution.
Without structured planning, autonomy devolves into reactive execution rather than controlled reasoning.
Tool invocation
When a plan requires external interaction, the agent invokes tools.
These tools may include:
- APIs
- Databases
- Search engines
- Workflow systems
- Messaging platforms
- Analytical engines
Tool invocation must occur within clearly defined execution boundaries. Context engineering ensures the agent understands which tools are available, under what conditions they can be used, and the constraints that apply.
Autonomous capability emerges not merely from reasoning, but from the ability to act within governed parameters.
Execution feedback integration
Every tool invocation produces results—data retrieved, records updated, messages sent, or analyses generated.
These outputs are not final outcomes. They become new inputs.
Execution feedback integration is the structured integration of tool results into the agent’s context. The agent must interpret:
- Whether the action succeeded
- What new information has emerged
- Whether the original objective has been satisfied
- Whether additional steps are required
This step closes the loop between action and continued reasoning.
Memory update
As workflows progress, relevant insights and outcomes must persist beyond the immediate reasoning cycle.
Memory updates may include:
- Storing key decisions
- Logging validated facts
- Recording user preferences
- Updating knowledge bases
- Persisting workflow state
Engineered memory ensures continuity across sessions and long-running tasks. It prevents redundant reasoning and enables cumulative intelligence.
Without deliberate memory architecture, agents remain episodic and disconnected.
Policy validation
At each critical decision point, actions must be validated against enterprise policies.
Policy validation may involve:
- Role-based access verification
- Sensitive data filtering
- Compliance rule checks
- Confidence thresholds
- Human-in-the-loop approvals
By integrating policy validation into each stage of the lifecycle, agentic systems ensure governance and safety without compromising operational performance.
Sustainable autonomy emerges not from the absence of constraints, but from systematic compliance with them.
Iterative reasoning loops
Agentic workflows rarely conclude after a single cycle. Instead, they proceed through iterative reasoning loops until objectives are satisfied or escalation is required.
This structured loop can be expressed as:
Thought → Action → Observation → Updated context → Next thought
- Thought: The agent analyzes the current context and determines the next step.
- Action: A tool is invoked, or a decision is executed.
- Observation: The outcome of that action is ingested and evaluated.
- Updated context: Memory and state are refreshed to reflect new information.
- Next thought: The agent reassesses the objective in light of the updated context.
This cycle continues until completion criteria are met.
Without engineered context management at each stage, reasoning loops degrade—objectives drift, memory fragments, and policy constraints are bypassed. With disciplined lifecycle design, however, agentic AI becomes stable, auditable, and scalable.
In enterprise environments, autonomy is not a single decision—it is a managed process. The context lifecycle ensures that every perception, plan, action, and update occurs within a structured framework. It transforms isolated model outputs into sustained operational intelligence.
Engineering contextual memory for enterprise agents
Autonomous intelligence is inseparable from memory.
Enterprise agents are expected to operate across extended workflows, multiple users, evolving policies, and dynamic data environments. They must recall prior decisions, maintain task continuity, and accumulate operational knowledge over time. Without deliberate memory architecture, even the most advanced agentic systems revert to reactive behavior—repeating work, losing context, and fragmenting decision-making.
Designing memory for enterprise agents is therefore not an implementation detail. It is a foundational architectural discipline.
Effective memory systems must address multiple dimensions: temporal scope, knowledge type, storage structure, and access boundaries.
Short-term vs. working memory
Although often used interchangeably, short-term memory and working memory serve distinct roles in agentic workflows.
Short-term memory refers to the immediate interaction history—recent conversation turns, current inputs, and near-term state variables retained within the active context window. It preserves continuity across consecutive reasoning steps and prevents repetitive clarification.
Working memory, by contrast, is task-oriented and dynamic. It tracks:
- Current objectives and sub-goals
- Intermediate reasoning outputs
- Tool invocation results
- Active constraints and policy flags
- Execution checkpoints
Working memory evolves as the agent progresses through a workflow. It is continuously updated, reprioritized, and pruned to maintain focus.
In multi-step enterprise workflows, working memory helps the agent maintain focus on the original objective while integrating new information. Without it, reasoning degrades into disconnected steps rather than structured execution.
Long-term persistent memory
Enterprise agents must operate beyond individual sessions. They are expected to retain institutional knowledge, user preferences, historical interactions, and validated outcomes across time.
Long-term persistent memory enables:
- Continuity across sessions
- Personalized experiences
- Cumulative learning from prior workflows
- Reduced redundancy in repetitive tasks
- Institutional knowledge retention
Persistent memory may include structured records, embedded conversation summaries, indexed documents, and stored decision artifacts. Unlike working memory, it is not transient. It is designed for retrieval at future decision points.
The challenge is not simply storing information—but determining what should be retained, how it should be indexed, and when it should be retrieved. Unfiltered persistence introduces noise and increases retrieval complexity. Engineered long-term memory ensures relevance, traceability, and controlled growth.
Semantic memory vs. episodic memory
Enterprise agent memory must also distinguish between types of knowledge.
Semantic memory captures structured, factual knowledge:
- Policies and regulations
- Product specifications
- Organizational hierarchies
- Standard operating procedures
- Verified data points
This knowledge is generally stable, structured, and widely applicable across workflows.
Episodic memory, on the other hand, captures experiences:
- Past user interactions
- Specific workflow outcomes
- Resolved support tickets
- Prior decisions made under similar conditions
Episodic memory provides contextual nuance. It allows agents to reference past events and adapt their behavior accordingly.
Effective enterprise agent design integrates both. Semantic memory provides authoritative grounding. Episodic memory provides situational continuity. Together, they create agents that are both knowledgeable and contextually aware.
Vector memory vs. graph memory
The structure of memory storage significantly influences retrieval quality and reasoning capability.
Vector memory leverages embeddings to store and retrieve information based on semantic similarity. It enables:
- Flexible recall of unstructured text
- Retrieval-augmented reasoning
- Adaptive similarity-based search
- Scalable storage of large knowledge corpora
Vector memory is particularly effective for retrieving relevant document chunks, conversation summaries, and contextual insights that align semantically with new queries.
Graph memory, by contrast, emphasizes relationships. Knowledge graphs encode entities and their connections, enabling:
- Structured reasoning
- Multi-hop inference
- Relationship-based validation
- Hierarchical data navigation
Graph memory is especially valuable in enterprise environments where relationships matter—such as compliance dependencies, approval chains, product-component mappings, or customer-account hierarchies.
In production-grade agentic systems, vector and graph memory often coexist. Vector memory provides semantic recall. Graph memory provides structural precision. Context engineering determines when and how each memory type is invoked.
Memory isolation: Tenant, agent, and crew boundaries
As enterprises deploy multiple agents across departments, products, and geographies, memory isolation becomes critical.
Memory must be scoped deliberately to prevent:
- Data leakage across tenants
- Cross-agent contamination of the state
- Unauthorized access to sensitive records
- Inconsistent contextual inheritance
Memory isolation typically operates at several levels:
Tenant-level isolation ensures that data from one organization or business unit is inaccessible to others.
Agent-level isolation restricts memory to the specific operational role of an individual agent (e.g., compliance agent vs. customer service agent).
Crew-level or multi-agent isolation governs how context is shared within collaborative agent groups—allowing controlled context propagation while preserving defined boundaries.
Without engineered isolation, autonomy introduces risk. With properly scoped memory design, enterprises can scale multi-agent ecosystems safely and predictably.
Memory as the continuity layer of autonomy
In agentic AI systems, memory is not an optional enhancement—it is the continuity layer that sustains intelligent behavior over time.
- Short-term memory preserves immediate coherence.
- Working memory maintains task focus.
- Persistent memory enables institutional intelligence.
- Semantic memory grounds reasoning in fact.
- Episodic memory enriches decisions with experience.
- Vector and graph architectures provide complementary retrieval capabilities.
- Isolation boundaries ensure secure and compliant scaling.
When memory is deliberately engineered, agents evolve from reactive responders into reliable digital operators capable of sustained, context-aware execution across enterprise workflows.
In the architecture of agentic AI, memory is not storage—it is structured intelligence extended across time.
Retrieval as dynamic perception (Beyond RAG)
In agentic AI systems, retrieval is not merely a technique for improving answer accuracy—it is the mechanism through which agents perceive their operational environment.
Traditional retrieval-augmented generation (RAG) was introduced to ground LLM responses in external knowledge. In enterprise agentic systems, however, retrieval evolves into something more foundational: dynamic perception. It continuously supplies agents with the information required to reason, act, and adapt within live workflows.
When context engineering governs retrieval, it transforms static document lookup into structured environmental awareness.
RAG for agents
In conventional chat applications, RAG enhances a single response by injecting relevant documents into the prompt. In agentic systems, retrieval plays a far more strategic role.
Agents rely on retrieval at multiple stages of the reasoning lifecycle:
- During initial context assembly
- While generating execution plans
- Before invoking tools
- After observing intermediate results
- When validating decisions against policies
This means retrieval is not a one-time augmentation—it is iterative and workflow-aware.
RAG for agents must therefore support:
- Step-level retrieval within reasoning loops
- Role-based filtering to enforce data access controls
- Contextual prioritization based on task state
- Traceability to authoritative sources
In agentic architectures, retrieval becomes an active participant in decision-making rather than merely supporting generation.
Multi-hop retrieval
Enterprise reasoning often requires connecting multiple pieces of information across domains.
A compliance agent, for example, may need to:
- Retrieve a regulatory clause
- Identify the relevant department
- Cross-reference internal policy mappings
- Determine escalation authority
This process cannot be satisfied through single-query retrieval. It requires multi-hop retrieval—where each retrieved result informs the next retrieval step.
Multi-hop retrieval enables agents to:
- Traverse linked concepts across documents
- Perform layered evidence gathering
- Validate conclusions through cross-referencing
- Execute structured reasoning across distributed knowledge
When embedded within context engineering, multi-hop retrieval supports deeper analytical workflows and reduces reliance on model guesswork.
Hybrid search
Enterprise knowledge ecosystems are complex. They contain structured data, unstructured documents, metadata tags, and domain-specific terminology.
Relying solely on semantic similarity may produce incomplete results. Conversely, keyword search alone may miss contextual nuance.
Hybrid search combines:
- Semantic vector search for conceptual alignment
- Keyword search for precision and terminology matching
- Metadata filtering for structured constraints
This blended approach ensures that agents retrieve both meaningfully related content and exact matches when required.
Within context-engineered systems, hybrid search enhances both recall and precision—delivering relevant context without introducing noise.
Semantic chunking for reasoning
Retrieval effectiveness depends not only on search strategy, but also on how knowledge is ingested and segmented.
Semantic chunking divides large documents into coherent, logically complete segments rather than arbitrary token blocks. Each chunk represents a meaningful unit of information—such as a policy clause, procedural step, or defined concept.
This approach improves:
- Retrieval relevance
- Token efficiency
- Logical consistency in reasoning
- Traceability to source material
For agentic workflows, semantic chunking ensures that retrieved content supports structured reasoning rather than overwhelming the context window with irrelevant data.
Well-designed chunking strategies reduce hallucinations by ensuring agents reason over focused, authoritative fragments rather than diluted document excerpts.
Context window optimization for long-running tasks
Large language models operate within fixed context windows. In agentic systems, where workflows may span multiple steps and iterations, managing this limitation becomes critical.
Without deliberate optimization, context accumulation leads to:
- Token overflow
- Degraded reasoning quality
- Context drift
- Reduced performance efficiency
Context window optimization involves:
- Prioritizing high-value information
- Summarizing intermediate reasoning steps
- Pruning obsolete data
- Persisting completed steps into long-term memory
- Reconstructing minimal viable context for each reasoning cycle
Rather than retaining every prior detail, engineered systems maintain a structured balance between immediacy and persistence. Working memory holds active state, while long-term memory stores validated knowledge for future retrieval.
This disciplined management ensures that agents remain focused, coherent, and performant—even in extended, multi-step workflows.
Retrieval as engineered perception
When viewed holistically, retrieval in agentic AI systems is not an enhancement layer—it is the perception engine.
- RAG grounds decisions.
- Multi-hop retrieval enables layered reasoning.
- Hybrid search increases precision.
- Semantic chunking improves contextual coherence.
- Context window optimization sustains long-running workflows.
Together, these capabilities transform retrieval from static augmentation into dynamic perception—an essential component of context engineering and a cornerstone of scalable, enterprise-grade autonomy.
Orchestration: Coordinating agents, tools, and decisions
Autonomous agents do not operate in isolation. They function within interconnected ecosystems of tools, workflows, data systems, and other agents. Without structured orchestration, even well-designed agents become fragmented—making decisions without alignment, invoking tools inconsistently, and failing to maintain coherent state across workflows.
Orchestration is the control layer that coordinates perception, reasoning, action, and collaboration across the agentic environment.
Within context-engineered systems, orchestration is not simply task sequencing. It is the control mechanism that ensures agents act deliberately, consistently, and within defined operational boundaries.
Tool definitions as structured context
In agentic AI, tools are not external utilities loosely attached to a model. They are formalized capabilities embedded within the agent’s operational context.
Each tool must be defined with clarity and structure, including:
- Purpose and functional scope
- Input parameters and expected formats
- Output schemas
- Access permissions
- Usage constraints
When tools are represented as structured context, agents understand not only what tools are available, but how and when to use them. This reduces ambiguity and prevents inappropriate invocation.
Structured tool definitions transform tool usage from improvisation into governed execution. They ensure that action is guided by explicit parameters rather than inferred assumptions.
Conditional branching and flow logic
Enterprise workflows are rarely linear. Decisions depend on prior outcomes, confidence thresholds, compliance conditions, and business rules.
Orchestration frameworks incorporate conditional branching and flow logic to manage this complexity. This includes:
- If–then decision paths
- Escalation branches for sensitive actions
- Retry loops for failed tool calls
- Alternative routing based on user role or context
- Confidence-based gating mechanisms to proceed, retry, seek clarification, or escalate actions
By embedding conditional logic into the orchestration layer, agents can adapt to dynamic environments while remaining aligned with defined operational policies.
This structured branching ensures that autonomous behavior remains predictable and controlled—even under varying input conditions.
Event-driven triggers
True enterprise autonomy is proactive, not merely reactive.
Event-driven orchestration enables agents to activate based on:
- System alerts
- New data entries
- Policy changes
- Scheduled checkpoints
- External workflow updates
Rather than waiting for explicit user prompts, event-aware agents monitor their operational environment and initiate workflows when predefined conditions are met.
Event-driven triggers elevate AI from assistant to operator. They embed intelligence directly into business processes, enabling continuous execution without manual intervention.
Multi-agent delegation
As workflows grow more complex, a single agent may no longer be sufficient to manage all responsibilities. Specialized agents—each designed for specific roles—can collaborate to achieve broader objectives.
Multi-agent delegation enables:
- Task decomposition into role-specific subtasks
- Distribution of responsibilities (e.g., compliance agent, analytics agent, communication agent)
- Parallel execution of independent activities
- Domain-specific reasoning within defined scopes
Delegation requires deliberate orchestration. The supervisor agent must define task boundaries, pass relevant context, and coordinate outcomes.
Without structured delegation, collaboration becomes fragmented. With it, multi-agent ecosystems operate as coordinated digital workforces.
Context propagation between agents
In collaborative environments, context must move intelligently between agents.
Context propagation determines:
- What information is shared
- What remains isolated
- How state updates are synchronized
- How memory is reconciled across agents
Uncontrolled propagation risks data leakage, scope confusion, and inconsistent reasoning. Insufficient propagation creates siloed intelligence and duplicated effort.
Context engineering ensures that shared context is:
- Scoped by role and authorization
- Filtered for relevance
- Versioned or tracked for auditability
- Updated consistently across workflows
Effective context propagation allows agents to collaborate without compromising governance or operational clarity.
Supervisor models
In advanced agentic architectures, supervisor models oversee and coordinate subordinate agents. These supervisory layers provide:
- Task orchestration and sequencing
- Quality assurance and validation
- Conflict resolution
- Escalation management
- Organizational policy enforcement
Supervisor models may review plans before execution, validate outputs after action, or reassign tasks dynamically based on evolving conditions.
This layered oversight ensures that autonomy remains structured rather than decentralized. It enables scalable multi-agent systems to operate cohesively while maintaining centralized governance and traceability.
Orchestration as the operational control layer
When viewed collectively, orchestration serves as the operational control layer of agentic AI systems.
- Structured tool definitions ensure safe action.
- Conditional logic enforces systematic decision paths.
- Event-driven triggers enable proactive execution.
- Delegation distributes responsibility across agents.
- Context propagation sustains collaborative coherence.
- Supervisor models maintain oversight and alignment.
Together, these mechanisms transform isolated agents into coordinated systems capable of sustained, enterprise-grade performance.
In context-engineered architectures, orchestration is not an afterthought—it is the framework that binds agents, tools, and decisions into a unified, governed autonomy layer.
ZBrain’s robust knowledge bases: Delivering relevant, real-time context
At the core of effective context engineering is the ability to deliver relevant, up-to-date knowledge to an LLM at the moment of reasoning. This depends on a robust, enterprise-grade knowledge base—a structured repository that consolidates an organization’s proprietary information, including documents, databases, manuals, SOPs, CRM entries and real-time data streams. When paired with Retrieval-Augmented Generation (RAG), the knowledge base becomes a dynamic memory layer that the model can query in real time to generate grounded, domain-specific responses.
RAG-based knowledge integration
ZBrain Builder employs a RAG-based approach as the foundation of its knowledge integration. Instead of relying solely on static knowledge baked into model training weights, ZBrain Builder dynamically retrieves relevant information from managed knowledge bases and injects it into the model’s context window at inference time. This ensures responses are grounded in fresh, authoritative data—even if ingested just minutes earlier. The LLM doesn’t “guess”; it retrieves and reasons over curated context in real time.
This capability is vital for enterprises managing:
-
Frequently changing policies or compliance rules
-
Rapid product iteration cycles
-
Personalized, domain-specific customer interactions
Whether a service agent is referencing the latest warranty policy or a compliance agent is validating against updated regulations, ZBrain’s RAG pipeline ensures knowledge is both accurate and delivered at the right stage of the prompt lifecycle.

Incorporating private and dynamic enterprise data
A key strength of ZBrain is its ability to seamlessly integrate static enterprise documents with dynamic operational data within the knowledge base. Organizations can ingest structured and unstructured content—PDFs, spreadsheets, wikis—while also connecting to APIs, databases and applications that supply regularly refreshed or real-time data. This allows AI agents and apps to reason not just over institutional knowledge but also live business context, including:
-
The latest customer interactions
-
Current inventory levels

The result is an AI system that delivers accurate, situationally aware responses—essential for decision support and automation in live enterprise environments.
Dynamic knowledge base maintenance
ZBrain Builder also supports continuous knowledge refresh. Its Dynamic Knowledge Base Creation Agent automates ingestion, chunking, and indexing of source material. It can monitor data sources and update the knowledge base incrementally, ensuring AI agents always reference the most current version of a document or dataset. It can be used as an upstream agent.
This automation reduces operational overhead and improves information freshness. For CXOs, it means an AI system that evolves in step with the business—adapting instantly to policy changes, market dynamics and internal updates.
Impact on context quality
Just as important as freshness is relevance. ZBrain’s architecture emphasizes context quality through semantic indexing, chunk optimization and relevance ranking. Only the most useful, high-fidelity snippets are retrieved, and they are presented to the LLM in structured, token-efficient templates.
This directly improves:
-
Accuracy: Reduces hallucinations by grounding answers in authoritative facts.
-
Consistency: Ensures agents operate deterministically on shared data.
-
Transparency: Enables traceability back to specific documents or sources.
-
Efficiency: Avoids context overload, preserving performance across long prompts.
ZBrain Builder transforms enterprise knowledge management into an intelligent, real-time service layer for LLMs. Its integration of RAG workflows, live business data, and continuous knowledge base updates ensures that AI agents operate with maximum accuracy, situational awareness, and trustworthiness. For enterprises, this makes context engineering not just a technical feature, but a strategic enabler of scalable, compliant and adaptive AI systems.
Agentic framework of ZBrain Builder: Enabling autonomous intelligence
ZBrain’s context engineering strategy is built into its agentic framework—an architecture designed to support autonomous, context-aware AI behavior at enterprise scale. Unlike static models that respond only when prompted, ZBrain agents act proactively and independently, triggered by real-world events and guided by policies, context, and business logic. They detect, decide, and execute—much like a trained digital workforce—with governance and control mechanisms built in from the start.
This framework goes beyond chatbots or call-and-response interactions. In ZBrain Builder, an agent is a goal-driven, event-aware system that perceives its environment, plans multi-step reasoning paths, invokes external tools, manages memory, and collaborates with human operators when needed.
Integrated orchestration platform
ZBrain’s agentic capability is anchored in a tightly integrated orchestration layer that includes:
-
Memory systems to retain relevant context across sessions

-
Conditional logic flow pieces for managing decision branches

-
Human-in-the-loop checkpoints for review and intervention

-
Connectors to third-party tools, APIs, and internal databases

This ensures agents are deeply embedded in enterprise workflows rather than operating in isolation—with governance features applied consistently.
Event-driven intelligence (Triggers)
ZBrain agents operate in event-driven loops. They monitor structured and unstructured data sources—such as support tickets, transactions, logs, or calendar events—and activate automatically when relevant triggers occur.
Example: An agent can start documenting an article whenever the instruction file is uploaded in the input folder—without human instruction.

This event-awareness is a key differentiator, transforming an AI solution into an active operator rather than a passive assistant.
Context builder and memory
When activated, agents use ZBrain’s orchestration layer as a context builder to assemble a full picture of the situation: current inputs, historical memory, retrieved documents, and knowledge base. This structured, layered context model ensures holistic reasoning rather than one-off prompt injection.
Persistent memory allows agents to handle long-running tasks or maintain continuity, such as:
-
Recalling prior conversations
-
Preserving working memory for complex workflows
This stateful backbone enables more intelligent and consistent decision-making.
Autonomous actions with enterprise integration
ZBrain agents are not just reasoning components—they are autonomous, context-aware orchestrators capable of perceiving, deciding, and acting across enterprise workflows. Based on the generated plans, they can:
-
Query or update databases
-
Call internal APIs
-
Send messages, file tickets, or draft reports
-
Trigger downstream workflows or applications
Access is scoped by role and purpose. Execution flows are governed by logic maps and role-based controls, ensuring safety and compliance.
Scalability and parallelism
The agentic framework is designed for scale. A single agent can process multiple tasks in parallel, with execution tracked independently. This allows enterprises to run agents across departments, geographies, and systems—continuously and consistently.
Because orchestration, context assembly, and memory management are automated, agents scale without added complexity or performance drift.
Human-in-the-loop and feedback
Autonomy is bounded by governance. Agents can request human input before executing sensitive actions, when confidence is low, or when potential policy violations are detected.
ZBrain’s agents allow seamless insertion of approvals and review stages. Feedback loops capture user corrections, which are then reinjected into the agent’s memory—forming a continuous learning cycle that improves reliability.
Governance, transparency, and safety
Every action is fully auditable. ZBrain agents maintain a reasoning trace detailing what was perceived, what decisions were made, what tools were used, and why. This transparency supports compliance, debugging, and user trust.
Policy-level constraints—such as regulatory, legal, or brand rules—are embedded directly into system instructions and orchestration logic. Violations are automatically blocked, flagged, or rerouted.
ZBrain’s agentic framework transforms AI from static automation into context-driven autonomy at scale. Agents operate 24/7, surface insights, take actions, escalate when necessary, and improve continuously—all within enterprise-grade safety boundaries.
This scaffolded autonomy—guided by orchestration, memory, event triggers, and feedback—allows enterprises to deploy AI agents as true collaborators, not just assistants. The result: faster response times, lower manual effort, and more consistent policy adherence—without sacrificing oversight or control.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
Bringing it all together: Dynamic context management in action
Individually, each of the elements above—context engineering, knowledge bases, prompt orchestration, and agent frameworks—addresses a critical aspect of making AI systems intelligent and reliable. Together, they enable dynamic, scalable context management in real-world applications. ZBrain Builder illustrates how combining these capabilities can elevate AI from a simple Q&A tool into a sophisticated autonomous assistant. By continuously retrieving fresh knowledge, structuring inputs carefully, and enabling action with oversight, the system ensures that:
Answers and actions are always current and relevant
The AI solution is never limited to stale training data or prone to forgetting yesterday’s context. The AI is never restricted to outdated training data or susceptible to losing track of recent context, tailored to your business data) rather than generic.
The AI scales to complex tasks and long-running interactions
Through prompt orchestration and memory management, the AI solution handles multi-step processes without losing context. It can recall important details, summarize or discard irrelevant information, and remain effective even as conversations or workflows grow. The result is an AI that feels “smart” and continuously aware—much like a human collaborator who remembers context over time.
Autonomy drives efficiency—within safe bounds.
Agentic capabilities allow the AI to proactively execute tasks (monitoring events, calling APIs, updating records) to augment human teams. At the same time, built-in guardrails and human oversight provide executives with confidence and control. This balance is crucial for enterprise adoption: organizations gain productivity without the risk of unchecked “rogue AI (i.e., an autonomous system that ignores constraints, bypasses oversight, or acts outside its intended scope, potentially causing harmful or unauthorized outcomes).
The system continuously learns and improves
Feedback loops within ZBrain Builder ensure that the user can refine prompts, retrieval strategies, and model choices based on user input and outcome monitoring. Over time, the AI agent becomes increasingly aligned with organizational needs and norms—embedding contextual knowledge and best practices directly into its actions.
The future: Context as the enterprise AI control plane
As enterprises scale from isolated AI use cases to organization-wide agentic ecosystems, the role of context will continue to expand. What began as a mechanism for grounding LLM responses is rapidly evolving into something far more foundational: the control plane of enterprise AI.
In distributed computing, a control plane governs how systems coordinate, allocate resources, enforce policies, and maintain state. In agentic AI architectures, context performs an analogous function. It orchestrates perception, memory, governance, execution boundaries, and collaboration across agents, tools, and workflows.
The future of enterprise AI will not be defined solely by more powerful models—but by more sophisticated context infrastructures.
Context-driven self-improving agents
Agentic systems are increasingly expected to adapt over time. Enterprises do not want static automation; they want agents that refine performance, reduce errors, and align progressively with business norms.
Self-improvement in enterprise agents does not necessarily require continuous model retraining. Instead, it is driven by contextual refinement:
- Updating retrieval strategies
- Refining memory storage criteria
- Adjusting tool invocation rules
- Incorporating validated corrections
- Enhancing policy filters
By engineering context as a structured, updatable layer, enterprises enable agents to improve behavior without destabilizing core models. Intelligence becomes iterative rather than fixed.
In this paradigm, the agent’s learning surface is the context architecture itself.
Feedback loops
Sustained autonomy requires structured feedback.
Enterprise-grade agentic systems integrate feedback loops at multiple levels:
- User ratings and corrections
- Supervisor validation of outputs
- Policy violation flags
- Tool execution audits
- Performance metrics across workflows
These feedback signals are not merely logged—they are reinjected into the context lifecycle. Retrieval weights can be adjusted. Memory entries can be updated. Guardrails can be strengthened. Planning strategies can be refined.
Feedback loops transform context engineering from static configuration into adaptive governance. They enable continuous alignment between agent behavior and organizational expectations.
Without feedback-driven context updates, autonomy stagnates. With them, it evolves responsibly.
Context evolution
As enterprises grow, policies change, products evolve, regulations shift, and organizational structures expand. Agentic systems must reflect these changes immediately.
Context evolution refers to the structured updating of:
- Knowledge bases
- Memory repositories
- Policy constraints
- Role-based permissions
- Workflow logic
Dynamic knowledge ingestion pipelines, automated indexing agents, and incremental updates ensure that agents always reason over the most current information.
More importantly, context evolution allows organizations to scale autonomy safely. Instead of retraining models for every business change, enterprises update the contextual foundation. The result is agility without disruption.
In future architectures, context layers will become modular, versioned, and continuously maintained—mirroring modern infrastructure management practices.
Organizational intelligence fabric
As multiple agents operate across departments—compliance, customer operations, marketing, IT, and finance—the enterprise gradually builds an interconnected intelligence network.
When context is engineered consistently across agents, it forms an organizational intelligence fabric:
- Shared semantic understanding of business entities
- Unified policy enforcement mechanisms
- Coordinated memory systems
- Cross-functional workflow awareness
- Standardized governance protocols
This fabric allows agents to collaborate without silos, delegate tasks seamlessly, and maintain consistency across domains.
Rather than deploying isolated AI assistants, enterprises will operate cohesive ecosystems of agents—interconnected through shared contextual infrastructure.
In this model, context becomes the common language of enterprise AI.
Context as the enterprise AI control plane
The trajectory of agentic AI is clear: greater autonomy, deeper operational integration, and wider organizational impact. To scale this safely, context engineering must be treated as core infrastructure—not an optional enhancement.
Context determines what agents see, how they reason, what they retain, and the boundaries within which they operate—ensuring alignment with enterprise policy, governance, and purpose.
As agent ecosystems expand, context will serve as the control plane—coordinating distributed intelligence across tools, departments, and workflows.
The future of enterprise AI will not belong to organizations with the largest models. It will belong to those who engineer context deliberately, govern autonomy systematically, and build intelligence on a structured, evolvable foundation.
In the era of agentic systems, context is no longer a supporting layer. It is the infrastructure that defines how enterprise intelligence operates at scale.
Endnote
Context engineering is no longer a peripheral enhancement to language models—it is the architectural foundation of agentic AI.
In the era of autonomous systems, enterprises are not deploying isolated LLMs; they are deploying digital operators that perceive events, reason across workflows, invoke tools, collaborate with humans, and act within defined governance boundaries. Achieving this level of autonomy requires more than advanced models. It requires an engineered context.
Investing in context engineering means building the control plane that sustains enterprise autonomy. It means designing structured perception layers, memory architectures, governance mechanisms, execution boundaries, and orchestration frameworks that work in concert. Without this infrastructure, agentic AI remains reactive and fragile. With it, autonomy becomes reliable, auditable, and scalable.
ZBrain Builder’s approach—integrating dynamic knowledge systems, memory-aware orchestration, event-driven workflows, and governed multi-agent collaboration—demonstrates how context engineering enables safe, enterprise-grade autonomy. It provides a blueprint for evolving beyond prompt experimentation toward structured operational intelligence.
The result is not simply a more capable model, but a coordinated system of agents that understand enterprise context, remain aligned with policies, adapt to evolving data, and execute decisions with traceability and control.
In the future of enterprise AI, competitive advantage will not be defined by model size alone. It will be defined by how effectively organizations engineer context as the backbone of agentic systems—transforming AI from conversational novelty into governed, scalable, and outcome-driven autonomy across the enterprise.
Explore how ZBrain Builder’s agentic AI orchestration platform can transform your enterprise workflows—leveraging context engineering to ground knowledge, orchestrate multi-agent crews, and deliver reliable, governed automation at scale.
Listen to the article
Author’s Bio


CEO LeewayHertz
An early adopter of emerging technologies, Akash leads innovation in AI, driving transformative solutions that enhance business operations. With his entrepreneurial spirit, technical acumen and passion for AI, Akash continues to explore new horizons, empowering businesses with solutions that enable seamless automation, intelligent decision-making, and next-generation digital experiences.
Table of content
- What is context engineering, and why does it matter for LLMs?
- Core principles of context engineering in enterprise AI
- Key techniques and approaches in context engineering
- Tools, frameworks, and systems supporting context engineering
- Why agentic AI fails without engineered context
- Context engineering as the backbone of agentic systems
- Engineering contextual memory for enterprise agents
- Retrieval as dynamic perception (Beyond RAG)
- Orchestration: Coordinating agents, tools, and decisions
- ZBrain’s robust knowledge bases: Delivering relevant, real-time context
- Agentic framework of ZBrain: Enabling autonomous intelligence
- Bringing it all together: Dynamic context management in action
- The future: Context as the enterprise AI control plane
Share Article


Frequently Asked Questions
What is context engineering, and why is it critical for agentic AI in the enterprise?
In the era of agentic AI, context engineering is the architectural discipline that enables autonomous systems to perceive, reason, and act while remaining aligned with enterprise constraints.
Unlike traditional prompt-based systems, agentic AI operates across multi-step workflows, invokes tools, maintains memory, and collaborates across functions. Context engineering ensures that agents:
- Perceive accurate and up-to-date enterprise information
- Maintain continuity across reasoning loops and sessions
- Operate within defined policy and governance boundaries
- Invoke tools safely and appropriately
- Produce auditable, traceable decisions
Without engineered context, autonomous agents risk hallucinations, context drift, tool misuse, and policy violations. With it, autonomy becomes structured, reliable, and scalable across enterprise environments.
How does ZBrain Builder implement context engineering for agentic systems?
ZBrain Builder operationalizes context engineering as the control plane of its agentic architecture.
It combines:
- Dynamic knowledge systems (vector databases, hybrid retrieval, knowledge graphs) to provide real-time, grounded perception
- Structured memory architecture to preserve short-term workflow state and long-term institutional knowledge
- Event-driven orchestration to activate agents proactively across enterprise workflows
- Multi-agent coordination frameworks such as Agent Crew for structured delegation and collaboration
- Governed tool integration with execution boundaries and policy enforcement
Together, these components enable ZBrain Builder to deploy autonomous agents that detect, decide, and act—while remaining aligned with enterprise data, policies, and operational controls.
How does ZBrain Builder ensure enterprise agents always operate on current knowledge?
Agentic AI requires dynamic perception.
ZBrain Builder supports continuous knowledge evolution through:
- Automated ingestion of enterprise data sources (CRM systems, ERP platforms, APIs)
- Hybrid indexing strategies (vector, keyword, and graph-based linking)
- Configurable semantic chunking for domain-optimized retrieval
- Incremental updates via dynamic knowledge base agents
Agents retrieve context in real time at multiple stages of their reasoning lifecycle—not just once at prompt time. This ensures that planning, tool invocation, and decision validation are grounded in the most current authoritative data.
The result is autonomy anchored in live enterprise intelligence.
What role do knowledge graphs play in agentic AI workflows?
While vector search enables semantic recall, knowledge graphs introduce structural reasoning.
In agentic systems, knowledge graphs support:
- Entity-level precision by modeling relationships between entities such as policies, departments, risks, customers, or assets
- Multi-hop reasoning across linked entities (e.g., regulation → department → compliance exposure → escalation authority)
- Governance transparency by making relationship chains traceable and auditable
For autonomous agents, this structured understanding enables deeper reasoning beyond similarity matching. It allows agents to infer connections, validate dependencies, and operate within clearly defined organizational structures.
How does Agent Crew operationalize context engineering in agentic orchestration?
Agent Crew extends context engineering into multi-agent collaboration.
It enables:
- Supervisor–child agent hierarchies for coordinated execution
- Structured task delegation across specialized agents
- Context propagation with scoped memory controls (no memory, crew memory, tenant memory)
- Parallel task execution within defined governance boundaries
- Cohesive decision frameworks across agent ecosystems
Rather than isolated agents acting independently, Agent Crew enables coordinated digital workforces operating on shared contextual infrastructure—while preserving security, role-based isolation, and auditability.
Why is context engineering more important in agentic AI than in traditional LLM applications?
In traditional LLM applications, context primarily improves response quality. In agentic AI systems, context governs autonomy.
Agentic systems execute multi-step workflows, invoke tools, maintain memory, and operate continuously within enterprise environments. Without engineered context, agents lose task continuity, misinterpret objectives, misuse tools, or violate policy constraints.
Context engineering transforms isolated model outputs into structured, stateful, and governed execution. It ensures that autonomous agents reason with the right information at every stage of their lifecycle.
How does context engineering enable safe autonomy?
Safe autonomy requires more than model intelligence—it requires controlled execution.
Context engineering enables safe autonomy by:
- Injecting enterprise policies directly into agent reasoning
- Enforcing role-based access controls during retrieval
- Governing tool availability and execution conditions
- Maintaining memory boundaries across tenants and agents
- Embedding escalation logic and human-in-the-loop checkpoints
By structuring what agents know, remember, and are permitted to do, context engineering ensures autonomy operates within clearly defined enterprise guardrails.
How does context engineering prevent context drift in multi-step agent workflows?
Agentic AI operates through iterative reasoning loops. Over time, objectives can shift, constraints can be forgotten, and irrelevant information can accumulate.
Context engineering prevents drift by:
- Persisting core objectives in working memory
- Updating the state after each action
- Prioritizing high-value context within limited context windows
- Storing validated outcomes in long-term memory
- Reconstructing focused context for each reasoning cycle
This structured lifecycle management maintains alignment between agent behavior and original business intent.
How does context engineering support multi-agent collaboration?
In multi-agent ecosystems, collaboration requires shared understanding without compromising isolation or governance.
Context engineering enables:
- Controlled context propagation between agents
- Scoped memory sharing (crew-level vs tenant-level)
- Structured delegation with bounded authority
- Supervisor oversight across collaborative workflows
By defining how context flows across agents, enterprises prevent duplication, misalignment, and data leakage while enabling coordinated execution.
How does context engineering help scale agentic AI across the enterprise?
Scaling agentic AI requires consistency across departments, workflows, and geographies.
Context engineering provides that consistency by:
- Standardizing knowledge retrieval mechanisms
- Embedding shared policy frameworks
- Enforcing unified governance controls
- Maintaining centralized memory architectures
- Coordinating distributed agents through structured orchestration
As more agents are deployed, context engineering becomes the unifying infrastructure that ensures autonomy remains coherent and enterprise-aligned.
What challenges does agentic AI face without context engineering?
Without engineered memory, agents:
- Forget prior interactions
- Repeat resolved tasks
- Lose workflow continuity
- Fail to personalize responses
- Operate in isolated execution cycles
Context engineering defines short-term, working, and long-term memory systems that allow agents to sustain intelligence across time. Memory transforms reactive outputs into continuous operational capability.
What business risks arise when context engineering is weak or absent?
Inadequate context engineering can result in:
- Hallucinated decisions triggering incorrect actions
- Tool misuse or unauthorized execution
- Regulatory or compliance violations
- Data leakage across users or tenants
- Inconsistent customer or operational experiences
As autonomy increases, the impact of contextual failure compounds. Engineered context mitigates these risks by embedding control mechanisms directly into agent reasoning and execution flows.
How do we get started with ZBrain for AI development?
To begin your AI journey with ZBrain:
-
Contact us at hello@zbrain.ai
-
Or fill out the inquiry form on zbrain.ai
Our dedicated team will work with you to evaluate your current AI development environment, identify key opportunities for AI integration, and design a customized pilot plan tailored to your organization’s goals.
Insights

Solution architecture best practices: A guide for enterprise teams
The architecture design process culminates in a set of documented artifacts that communicate the solution to development, operations, and business teams.

Common solution architecture design challenges — and how to overcome them
Solution architecture must evolve from fragmented documentation practices to a structured, collaborative, and continuously validated design capability.
Why structured architecture design is the foundation of scalable enterprise systems
Structured architecture design guides enterprises from requirements to build-ready blueprints. Learn key principles, scalability gains, and TechBrain’s approach.
A guide to intranet search engine
Effective intranet search is a cornerstone of the modern digital workplace, enabling employees to find trusted information quickly and work with greater confidence.

Enterprise knowledge management guide
Enterprise knowledge management enables organizations to capture, organize, and activate knowledge across systems, teams, and workflows—ensuring the right information reaches the right people at the right time.
Company knowledge base: Why it matters and how it is evolving
A centralized company knowledge base is no longer a “nice-to-have” – it’s essential infrastructure. A knowledge base serves as a single source of truth: a unified repository where documentation, FAQs, manuals, project notes, institutional knowledge, and expert insights can reside and be easily accessed.
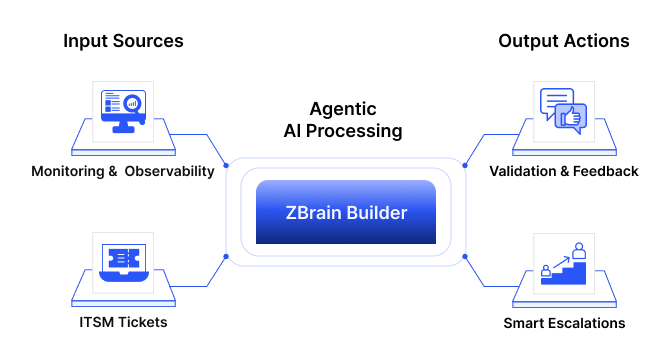
How agentic AI and intelligent ITSM are redefining IT operations management
Agentic AI marks the next major evolution in enterprise automation, moving beyond systems that merely respond to commands toward AI that can perceive, reason, act and improve autonomously.

What is an enterprise search engine? A guide to AI-powered information access
An enterprise search engine is a specialized software that enables users to securely search and retrieve information from across an organization’s internal data sources and systems.
A comprehensive guide to AgentOps: Scope, core practices, key challenges, trends, and ZBrain implementation
AgentOps (agent operations) is the emerging discipline that defines how organizations build, observe and manage the lifecycle of autonomous AI agents.

