


Loop engineering: The foundation for building self-driving AI agents

For much of the recent AI agent adoption cycle, enterprise use still depended on close human orchestration. Teams had to define the task, supply the necessary context, review each response, judge whether the output was good enough, and decide what should happen next. One interaction led to another, and then another.
The agent contributed to the work, but the human provided the control loop: determining what mattered, evaluating progress, and keeping the effort moving toward a useful outcome. That operating model is beginning to change. As agents become more capable of planning, acting, checking results, and continuing work across steps, the human role is shifting from steering each interaction to designing the systems that steer the agent.
The clearest signal came from the people building the agents. Boris Cherny, who leads Claude Code at Anthropic, described his own change in posture bluntly: he no longer prompts the model directly. Instead, he has loops running that prompt it and decide what to do next, and, as he put it, his job is now to write loops. Around the same time, Peter Steinberger argued that engineers should stop prompting coding agents altogether and start designing the loops that prompt the agents for them. By June 2026, the software engineer and writer Addy Osmani had given the shift a name and a shape – loop engineering, and the term spread quickly because it captured something many teams were already feeling.
Loop engineering is the practice of designing, operating, and improving the feedback systems that let an AI agent plan, act, observe the results, and revise its approach until a goal is reached without a human driving every turn. The work moves from writing a single good instruction to designing the system that generates, runs, verifies, and continues the work on its own. The leverage point shifts from the prompt to the loop.
This article takes a vendor-neutral, enterprise-focused view of loop engineering as an emerging discipline. It defines the concept of loop engineering, outlines the two primary mental models currently shaping the discussion, and presents a practical reference architecture for implementation. It then describes a step-by-step adoption path, with additional focus on areas often underrepresented in early material – governance, security, cost management, observability, organizational design, and measurement.
It also approaches the topic with appropriate caution. Loop engineering is still a nascent concept – recently named, still evolving, and not yet standardized. It is actively being explored and, in some cases, debated. The goal of this article is not to present it as a finalized framework, but to provide engineering and product leaders with a structured, realistic way to understand and evaluate it.
A note on scope: while the term originated in the context of coding agents, the underlying pattern applies more broadly to any system where an agent performs iterative actions toward a defined and verifiable objective. The examples in this article are primarily drawn from software engineering, where these systems first became practical at scale, but the same principles extend to domains such as operations, customer support, documentation, research, and other forms of agent-driven work.
Table of content
- What loop engineering is and where it sits
- Why loop engineering is emerging now
- Anatomy of a loop: The building blocks
- How a loop engineering system operates end-to-end
- How to implement loop engineering systems
- Enterprise concerns: Governance, security, cost, and reliability
- Failure patterns in loop engineering systems
- How loop engineering changes team operating models
- How to measure loop engineering performance
- What comes next for loop engineering
What loop engineering is and where it sits
At its simplest, loop engineering is the practice of designing feedback systems around an AI agent so the system, rather than a person, keeps work moving toward a defined goal. The human role shifts from prompting each step to designing the control structure that decides when the agent should act, how results should be evaluated, what should happen next, and when the work should stop.
To see what is new about that shift, it helps to place loop engineering in the broader progression of agent-building disciplines. Prompt engineering focused on the instruction. Context engineering expanded the focus to what the model could see. Harness engineering addressed the environment in which a single agent run executes. Loop engineering adds the next layer: the system-level control that coordinates many runs over time.
The engineering stack
The cleanest way to place loop engineering is as the most recent layer in a stack of agent-building disciplines, each of which is built on the last rather than replacing it.
The first layer is prompt engineering that improves how instructions are written to the model. The second is context engineering that helps control what the model can access at runtime, including tools, retrieved information, examples, and conversation history. The third layer, often referred to as harness engineering, defines the execution environment for a single agent run: the scaffolding, permissions, tool access, and runtime constraints that shape how that run behaves.
Loop engineering sits one level above the harness. It is the control layer that coordinates multiple runs of that harness over time. Instead of focusing on a single execution, it determines when runs should be triggered, how results are evaluated, when to spawn additional agent runs, and how state is recorded and fed forward. In effect, it turns isolated executions into a continuous feedback system that operates without constant human intervention.
The important point is that these layers are additive. Loop engineering does not make prompt or context engineering obsolete; a loop made of badly prompted, badly contextualized runs simply fails faster and more expensively. Good loops are built on good prompts and good context. What changes is where the highest-leverage engineering effort now sits.
The core loop
Underneath all the elaboration is a simple operational pattern that has powered most agent systems from the beginning: provide a model with context, allow it to take actions through tools in a loop, observe the results, and repeat until a stopping condition is met. Everything in this guide can be seen as an extension of this primitive loop—wrapping it in verification, triggering it from external events, running multiple instances in parallel, and improving it over time.
It helps to think of this loop as a recursive goal-seeking process: a purpose is defined, and the system iteratively refines its actions until that purpose is achieved within defined constraints.
Why this is not just a cron job
A common misconception about the term loop engineering is that it is the same as a cron job.
A cron job executes a fixed script on a schedule; the same predefined commands run every time without variation.
A loop, in this sense, contains a decision-making process inside the execution itself. The agent inspects the current state, selects the next action based on that state, executes it through tools, evaluates the result, and then determines the next step — including whether to continue or stop.
From the outside, such a system may resemble scheduled execution. Internally, however, it is state-conditioned and adaptive: what runs next is not fixed in advance, but determined by the evolving context of the task.
How loop engineering differs from agent loops
A common misconception is that agents have always operated in loops, so there is nothing fundamentally new here. The distinction is not the presence of a loop, but what the loop becomes.
In traditional agentic systems, the loop is an execution pattern: a model is invoked, it uses tools, produces an output, and the process ends. In loop engineering, the loop becomes a durable unit of work. It is no longer a transient sequence of steps, but a persistent system component that continues operating over time.
Instead of being something a developer invokes and observes, the loop can run on a schedule, operate across isolated workspaces, invoke sub-agents, persist its progress to external systems such as files or task boards, and continue running even when no user is actively supervising it.
In this framing, the loop is not just a mechanism for completing a task in one session. It is a continuously operating orchestration layer that performs discovery, action, verification, memory updates, and continuation as an ongoing process. This persistent, stateful, and self-sustaining behavior is what loop engineering refers to.
Agentic loop = how one brain thinks while solving a task
Loop engineering = how you manage many brains over time to get work done
At this point, it becomes useful to be precise about the components involved. Terms like “loop,” “harness,” and “state” are often used inconsistently across systems and implementations, and the distinctions matter when reasoning about architecture. The following vocabulary defines how these concepts are used in this article.
The supporting vocabulary
-
Harness: The execution environment in which a single agent runs, including tools, permissions, and runtime constraints.
-
Agentic loop: A model-driven cycle where an agent repeatedly uses tools and observations to complete a task.
-
Sub-agent: A separate agent instance invoked by another agent to perform a bounded or specialized task.
-
Worktree: An isolated working directory used to separate execution contexts across tasks or agents.
-
Skill: Codified instructions or project-specific knowledge that an agent can load and apply during execution.
-
Connector (often MCP-based): A mechanism that allows an agent to interact with external systems, tools, or APIs.
-
Grader: A component that evaluates outputs against defined criteria, often used for verification or scoring.
-
Trace: A structured record of all actions, tool calls, and observations generated during a run.
-
Stopping condition: A verifiable rule that determines when a loop should terminate.
-
State (or persistence): Information stored outside a single run that can be reused across iterations or sessions.
Why loop engineering is emerging now
Several technical and economic forces have converged to make loop engineering a practical and increasingly important design pattern. While the underlying idea is conceptually simple, its relevance has only become clear as agent systems crossed key capability and infrastructure thresholds. The following factors explain this shift in a more structured way.
Capability threshold
Model capability has reached a point where a single agent run can sustain multi-step execution without continuous human intervention. Within a run, this takes the form of an agentic loop, which is a cycle of reasoning, tool use, observation, and repetition until a task is completed or a stopping condition is reached.
This introduces a practical capability threshold: whether an individual run is stable enough to remain productive over extended execution without collapsing into incoherence or requiring constant correction.
This distinction matters because it separates two layers of looping: Intra-run loops (agentic loops) operate inside a single execution and inter-run loops (loop engineering) operate above them, coordinating multiple runs over time.
Once intra-run loops are stable enough above this threshold, it becomes viable to introduce inter-run feedback systems that wrap, extend, and coordinate those runs. These system-level loops determine when to trigger new runs, how to evaluate outputs, when to retry or branch into sub-agents, and how to persist state across executions.
Below the capability threshold, even intra-run agentic loops are unstable, causing both single runs and any higher-level orchestration to repeatedly amplify errors. Above it, stable intra-run loops enable inter-run loop engineering systems to compound useful work by chaining successful runs, recovering from failures, and adapting over time.
Shift in the bottleneck
As model quality improves, the primary constraint in agent systems shifts away from generating useful outputs and toward orchestrating work effectively.
The key challenge is no longer isolated response quality, but system-level coordination: how tasks are initiated, routed, verified, persisted, and continued across time. Loop engineering emerges in this orchestration layer, where the dominant engineering effort moves from prompt design to system design.
Tooling standardization
The building blocks required to construct persistent agent loops have become increasingly standardized. Capabilities such as scheduling, isolated execution environments, tool connectors, sub-agent execution, reusable instruction sets, and persistent state management are now widely available across modern frameworks.
This reduces reliance on bespoke infrastructure and makes loop design portable across systems. As a result, loop patterns can now be described in terms of consistent primitives rather than implementation-specific scripts.
Convergent discovery
Independent practitioners and research groups working across different systems have begun converging on similar architectural patterns within a short time frame.
This convergence suggests that loop-based designs are not isolated optimizations or vendor-specific constructs, but reflections of a deeper structural shift in how agent systems are being built and operated.
Economic compounding
Loop-based systems introduce a compounding dynamic in operational performance. Improvements in orchestration, verification, and feedback mechanisms accumulate over time, affecting not just individual task outcomes but the efficiency of repeated execution cycles.
In this framing, loop engineering is not only a technical pattern but also an economic one. It enables organizations to combine human judgment with continuously improving automated execution, creating systems where capability compounds through repeated cycles of work.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
Anatomy of a loop: The building blocks
The most practical way to understand loop engineering is to decompose a working system into its core building blocks. In practice, a loop is not a single mechanism but a composition of components that together determine whether work can start, continue, be verified, and ultimately be completed.
At the center of all of them sits one critical element: the stopping condition.
A loop must have a verifiable definition of “done.” Without it, the system has no way to evaluate progress or determine completion. This is where many real-world failures originate. A vague objective, such as “improve the application,” gives the loop nothing concrete to check against, leading either to unbounded execution or outputs that satisfy no clear criterion. In contrast, a precise condition, for example, “all tests pass, and linting errors are resolved,” provides both a termination signal and a measurable notion of success. In effect, the discipline of defining stopping conditions is the discipline of loop engineering in its most fundamental form.
Once this foundation exists, the remaining building blocks define how the loop operates in practice.
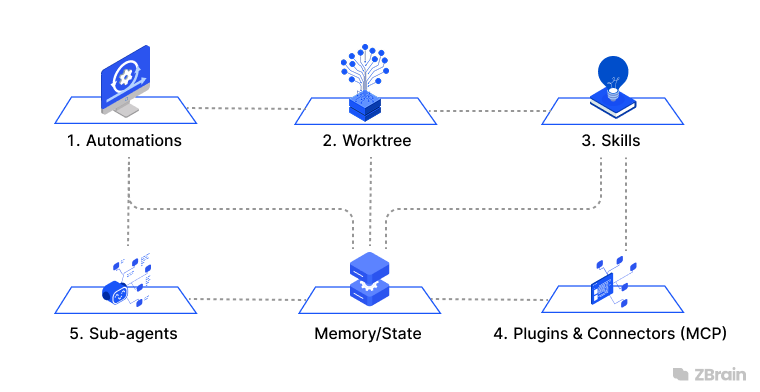
Automations as execution triggers
Automations define when a loop runs. They transform a one-off execution into a continuous system by triggering runs on a schedule or in response to events.
In practice, this is the heartbeat of the system. A scheduled run might scan for failures every morning, while an event-driven run might respond to a new issue, a failing test, or an incoming request. Depending on what it finds, the loop either escalates work into a queue or completes quietly if no action is required. Without automations, there is no continuity, only isolated executions.
Worktrees for isolated execution environments in parallel execution
As soon as multiple agent runs operate in parallel, isolation becomes essential. Without it, concurrent edits to the same files or state introduce conflicts and unpredictable behavior.
Worktrees, which are commonly implemented using git workspaces, allow each agent to run in an isolated environment while still sharing the same underlying repository history. This ensures that multiple agents can work simultaneously without overwriting or interfering with one another.
Isolation is what transforms parallel execution from a source of conflict into a source of throughput.
Skills are persistent reusable project knowledge
Skills encode durable, project-specific knowledge that an agent can rely on across runs. These include conventions, architectural decisions, build procedures, and constraints derived from prior experience.
Without skills, every run effectively starts from zero, forcing the agent to rediscover project norms and fill gaps with inference. With skills, that knowledge is externalized and reused consistently, allowing the system to improve over time rather than repeatedly relearn the same context.
In this sense, skills convert repeated instruction into persistent organizational memory.
Connectors as interfaces to external systems and tools
A loop becomes operationally meaningful only when it can interact with real systems. Connectors are often implemented through protocols such as MCP to extend the agent beyond its local environment into external tools and services.
These may include issue trackers, databases, APIs, CI systems, or communication platforms. With connectors, the loop transitions from generating suggestions to executing actions within real workflows: opening pull requests, updating tickets, triggering builds, or posting results to shared channels.
Connectors define the boundary between simulation and operational execution.
Sub-agents for separating execution and verification roles
Complex tasks often require separating responsibilities within the system. Sub-agents allow a loop to delegate work to specialized instances with distinct instructions or roles.
A common pattern separates:
-
a producer agent that produces solutions,
-
and a verification agent that evaluates them.
This separation is important because a single model evaluating its own output tends to be overly permissive. Introducing independent evaluation improves reliability, even if it increases cost through additional runs and tool usage.
Sub-agents introduce structural independence into the system’s reasoning process.
Memory for persisting state across runs
The final and most critical component is persistence. Because models do not retain state between executions, all continuity must be externalized.
Memory typically takes the form of files, task boards, logs, or structured state objects that record progress, decisions, and remaining work. Each run reads from this shared state and writes back to it, ensuring that progress accumulates rather than resets.
Without persistence, every execution begins from scratch. With it, the loop becomes cumulative and capable of long-running work that spans multiple sessions and time windows.
None of these components is optional in a fully functional loop. Each one corresponds to a specific failure mode:
-
No stopping condition → infinite or aimless execution
-
No automations → no continuity
-
No isolation → interference and conflicts
-
No skills → repeated re-learning
-
No connectors → no real-world action
-
No sub-agents → weak verification
-
No memory → no accumulation of progress
Viewed this way, loop engineering is not the invention of new primitives, but the systematic composition of existing ones into a reliable, self-sustaining execution system.
How a loop engineering system operates end-to-end
Abstract concepts in loop engineering become clearer when traced through a concrete system. A useful way to understand the discipline is to follow a single loop from trigger to completion and observe how the building blocks interact in practice.
Consider a morning triage loop applied to a software repository, a common real-world pattern because it combines scheduling, execution, verification, and escalation in a single workflow.
Each morning, a scheduled automation triggers a run against the repository. The agent begins by executing a triage skill that inspects the previous day’s CI failures, open issues, and recent commits. It synthesizes this information into structured findings and writes them to a persistent state store, such as a task board or state file.
From here, the system determines which findings are actionable. For each actionable item, the loop creates an isolated worktree and dispatches a sub-agent to propose a fix. This separation ensures that work is parallelizable and that each change is isolated from others in progress.
A second sub-agent then evaluates the proposed change against project constraints encoded in skills and existing tests. This explicit separation between the producer and the verifier ensures that evaluation is not biased by the generation process itself.
Once a change passes verification, connectors allow the system to operate directly within external tools: opening a pull request, updating the relevant issue, and linking artifacts across systems. If the loop encounters uncertainty or cases outside its competence, those items are not forced through the system; instead, they are escalated to a human review queue.
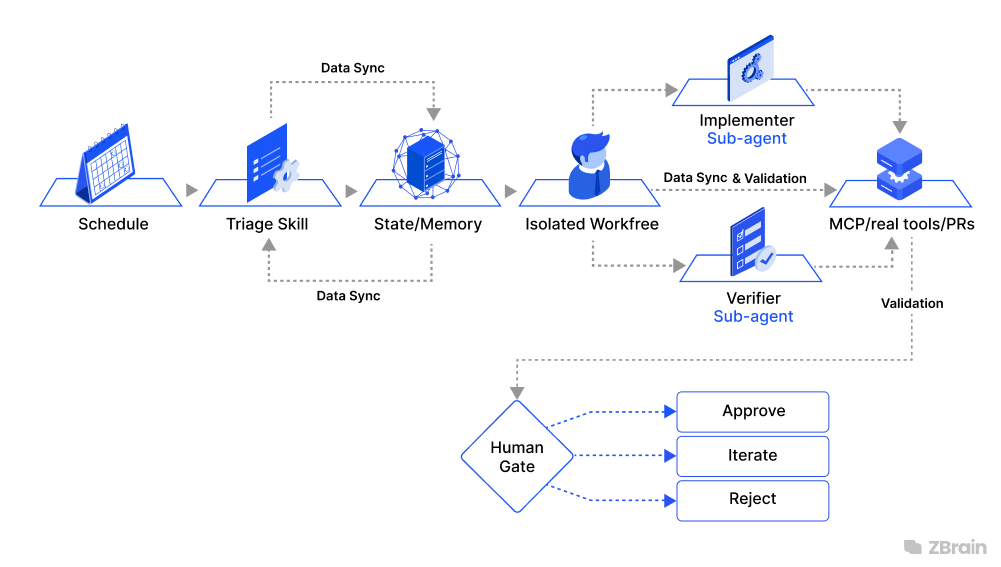
Throughout this process, persistence plays a central role. The state store acts as the system’s memory, recording what was attempted, what succeeded, and what remains unresolved. This ensures that the next run continues from a known state rather than restarting from scratch.
Loop engineering beyond software systems
The same structure applies outside of code repositories. In a documentation or operations workflow, an external event, such as an incoming message, request, or system signal, triggers a similar sequence.
An agent produces a draft change, a verification component checks structural correctness (such as links, formatting, or build success), and a human reviewer applies judgment where subjective evaluation is required. The same primitives trigger, execution, verification, and escalation are reused across domains, even though the tools and outputs differ.
What this architecture demonstrates
Across domains, the core insight remains consistent: the system is designed once, and individual steps are not manually prompted or managed in real time. The loop identifies work, executes it, verifies results, records state, and escalates exceptions automatically.
This is the practical expression of loop engineering, not as an abstract concept, but as a working system that continuously turns signals into completed, validated outcomes with minimal human intervention.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
How to implement loop engineering systems
Building a loop engineering system is less about selecting a specific product and more about expressing a stable set of capabilities across whatever environment you are working in.
Design around capabilities, not tools
The most important implementation principle is that loop capabilities are stable even when tooling changes. While product names and APIs differ, every production-grade loop relies on the same underlying building blocks: scheduling or triggers, workspace isolation, reusable skills, external connectors, sub-agent execution, and persistent state.
Designing in terms of these capabilities rather than tool-specific features makes the system portable. It reduces dependency on any single framework and ensures that the loop architecture remains intact even when underlying tools are replaced or evolve.
Understand the two cadence patterns
Loop systems typically operate in two primary cadence models, and it is important to be explicit about which one is being used.
The first is a scheduled loop, where execution occurs at fixed or recurring intervals regardless of system state. These loops are useful for routine tasks such as monitoring, triage, or periodic analysis.
The second is a condition-driven loop, where execution continues until a verifiable stopping condition is met. In this pattern, a separate evaluation step — often implemented as a lightweight verifier or model-based checker — determines whether the task is complete after each iteration. This effectively extends the maker–checker pattern to termination logic itself, ensuring that completion is validated rather than assumed.
Build versus buy
Historically, implementing loops required custom orchestration logic assembled from scripts and custom infrastructure. That is increasingly no longer necessary for standard use cases, as many of the core primitives are now available in modern agent frameworks and platforms.
For most teams, assembling loops from these existing primitives is the most efficient and maintainable approach. Custom orchestration becomes necessary only when workflows are highly specialized, when strict compliance or control requirements exist, or when system behavior cannot be expressed through available primitives.
In practice, the decision is not binary. It is a trade-off between speed of adoption and degree of control.
Adopt in stages
The most effective adoption path follows a gradual increase in system complexity, aligned with the stacked-loop model.
It typically begins with a minimal execution loop: an agent equipped with tools and a clearly defined stopping condition. This establishes basic autonomous execution.
The next stage introduces a verification loop, where outputs are evaluated against explicit criteria to reduce error propagation and improve reliability.
Once this is stable, an event-driven loop can be added to trigger execution based on external signals, enabling continuous or background operation rather than on-demand runs.
Finally, a feedback or improvement loop can be introduced, where traces from execution are analyzed to refine prompts, tools, and system configuration over time. This enables gradual system-level optimization based on observed performance.
Each stage provides standalone value, while also serving as a foundation for the next.
Cross-tool portability
A detailed comparison of how different ecosystems implement these primitives is provided in Appendix B. This comparison is intentionally descriptive rather than evaluative, as the goal is not to rank tools but to demonstrate that the same loop architecture can be expressed across multiple systems with different surface implementations.
Enterprise concerns: Governance, security, cost, and reliability
Most early discussions of loop engineering focus on how to build loops. For organizations, however, that is only the technical starting point. A loop that runs unattended is not just an automation but it is a system capable of taking consequential actions without real-time human supervision. This shifts the design problem from implementation to governance on how such systems are controlled, constrained, and made reliable in production environments.
The concerns below represent the core enterprise dimensions that determine whether loop engineering can be safely operated at scale. Where formal standards are still evolving, particularly in areas like security and auditability. The guidance here is grounded in first principles and should be treated as a set of design hypotheses to validate in context.
Human oversight as a design primitive
Human oversight is not an optional layer; it is a structural component of the system.
In a loop-based architecture, there are natural intervention points where human judgment provides value that automation cannot reliably replace. At the execution level, human approval is required for high-impact actions such as financial transactions, production deployments, or database modifications. Within verification workflows, humans may serve as evaluators in cases where correctness is subjective or context-dependent. At system boundaries, human gates ensure that outputs are reviewed before reaching end users. At the orchestration level, changes to loop behavior itself, such as modifications to prompts, tools, or policies, should pass through human review before deployment.
In mature systems, human-in-the-loop is not treated as a fallback mechanism but as a defined control surface integrated into the architecture.
Verification and accountability boundaries
Verification improves reliability but does not eliminate responsibility.
Separating execution from evaluation strengthens the system’s ability to detect errors, but it does not convert “validated output” into guaranteed correctness. A verification layer can only assess what it is designed to measure; it does not provide complete assurance.
For this reason, accountability remains with the engineering and operational stakeholders, not the system itself. The loop can support decision-making, but the responsibility for correctness, safety, and production readiness remains external to it.
Security and blast radius control
Security in loop engineering systems is fundamentally about limiting the impact of failure.
Three principles are central:
-
Least privilege ensures that each connector or tool operates with the minimum required permissions. Over-privileged systems significantly increase the impact of incorrect or malicious actions.
-
Containment ensures that execution environments are sandboxed and that agent actions cannot propagate unchecked across systems. This limits the blast radius of failures.
-
Supply chain awareness recognizes that skills, connectors, and reusable components are executable logic. They must be treated as dependencies with security implications, not static configuration. Each introduces potential risk into the system.
At a system level, the key question is: If this loop behaves incorrectly without supervision, what is the maximum possible impact? That boundary defines acceptable design.
Observability and traceability
Loop systems must be observable by design.
Every execution should produce a structured trace of actions, including tool calls, decisions, intermediate outputs, and verification results. These traces serve two functions. First, they provide auditability for individual runs, allowing operators to reconstruct system behavior. Second, they serve as aggregate training data for system improvement, enabling patterns of failure or inefficiency to be detected across runs.
Without this layer, loop systems are opaque and difficult to reason about. With it, they become analyzable, debuggable, and improvable.
Cost and resource control
Cost must be treated as a first-order design constraint, not an operational afterthought.
Loop systems can vary significantly in cost depending on how they are structured. In particular, sub-agent architectures introduce multiplicative cost effects because each additional agent incurs independent model and tool usage.
Effective systems enforce explicit budget constraints, selectively apply higher-cost verification only where it adds value, and track cost per completed task as a core efficiency metric. Without this discipline, systems may appear successful while remaining economically unsustainable.
Reliability and safety controls
Several structural mechanisms ensure that loops behave predictably under failure conditions.
Stopping conditions prevent uncontrolled execution and avoid infinite refinement cycles with no marginal benefit. Idempotency ensures that repeated execution of actions does not produce inconsistent or compounding side effects. Rollback mechanisms allow systems to recover from partial failure states. Scoped changes ensure that modifications remain constrained to intended boundaries.
Together, these mechanisms define the safety envelope within which loop systems can operate in shared and production environments.
Auditability and compliance
Taken together, persistent state and execution traces form a complete audit trail of system behavior.
For each run, it should be possible to answer three questions: what was done, why it was done, and what validated or approved the action. This is not optional in regulated environments instead it is a baseline requirement.
The ability to move from “the system executed” to “the system executed safely, correctly, and within defined policy constraints” is what separates experimental loop implementations from enterprise-grade loop engineering systems.
Failure patterns in loop engineering systems
Loop engineering is powerful because it allows agent systems to keep working without a human steering every step. That same property also changes the risk profile. A flawed prompt may produce one bad response; a flawed loop can repeat the mistake, escalate it across systems, or continue acting long after the original error should have been stopped.
For that reason, understanding failure modes is not a secondary concern. It is central to designing loops that are safe, observable, and economically viable. Most failures are not mysterious. They usually trace back to a weak or missing building block: an unclear stopping condition, insufficient verification, poor state management, excessive permissions, weak isolation, or inadequate cost controls.
The catalog below pairs common symptoms with their likely root causes and practical remedies. Read it less as a troubleshooting checklist and more as a design lens: each failure mode reveals a control the loop should have had before it was allowed to run unattended.
| Failure mode | What you see | Root cause | Remedy |
|---|---|---|---|
| Thrashing | The agent keeps changing code without converging. | Unclear goal, noisy validation signal, or editing too much at once. | Tighten the stopping condition, scope the diff, and strengthen the grader. |
| Infinite loop | The loop never stops. | No verifiable definition of “done.” | Write a concrete, checkable exit condition. |
| Hallucinated progress | The loop reports success, but it did not achieve it. | Weak or self-administered verification. | Use an independent grader; prefer deterministic checks where possible. |
| Token blowout | Cost runs away. | Unbounded runs, over-use of sub-agents. | Budget guards; reserve sub-agents for where a second opinion pays off. |
| Comprehension debt | You no longer understand the code that exists. | The loop ships faster than you read. | Read what the loop produced; treat review bandwidth as a real limit. |
| Cognitive surrender | You stop forming an opinion and accept whatever returns. | Comfort with a loop that runs itself. | Stay engaged; design the loop with judgment, not to avoid thinking. |
| Over-automation of judgment | The loop decides things that need human taste. | Automating where context and judgment were the value. | Keep humans where judgment, not mechanics, is what matters. |
Two failure modes deserve particular attention because they can intensify as loop systems become more capable.
The first is comprehension debt: the growing gap between what the system is doing and what the team actually understands about its behavior. A faster, smoother loop can widen this gap unless teams deliberately review its outputs, traces, decisions, and failure patterns.
The second is cognitive surrender: the tendency to stop forming independent judgment once the loop appears to operate successfully on its own. As confidence in the system increases, teams may gradually shift from supervising the loop to deferring to it.
The difficult truth is that the same mechanism can produce opposite outcomes. When designed and reviewed carefully, a loop helps teams move faster while deepening their understanding of the work. When used as a substitute for understanding, it accelerates drift. Two teams can build technically similar loops and experience very different results: one gains leverage over a system it understands well; the other slowly loses visibility into its own product.
That is what makes loop design harder than prompt engineering, not easier. The work has not disappeared; it has moved from writing better instructions to maintaining understanding, control, and accountability over systems that continue acting after the prompt is written.
How loop engineering changes team operating models
Loop engineering changes more than the technical architecture of agent systems. It changes how teams allocate work, where review capacity is spent, which roles become important, and how accountability is maintained when systems continue operating without a person steering every step.
For enterprise teams, this matters because the main constraint is rarely whether a loop can be built. The harder question is whether the organization can operate many loops responsibly: reviewing their outputs, understanding their behavior, assigning ownership, and ensuring that automation increases leverage without weakening judgment.
The valuable skill shifts from prompting to system design
As loop engineering matures, the premium moves from writing individual prompts to designing systems that generate, execute, evaluate, and continue work reliably. This is not a softer skill. It requires architectural judgment, operational discipline, and a clear understanding of where automation should stop, and human review should begin.
The engineer’s role shifts from steering every interaction to designing the conditions under which many interactions can happen safely. Good prompts still matter, but they become one component inside a broader system of triggers, tools, state, verification, and escalation.
Review bandwidth becomes the real scaling limit
Workspace isolation and parallel execution can remove many mechanical limits on throughput. Multiple agents can work at the same time without overwriting one another’s files or blocking a single developer’s workflow.
But this creates a new constraint: human review capacity.
A team can only run as many loops as it can responsibly inspect, evaluate, and approve. If loop output grows faster than review capacity, the result is not productivity; it is unmanaged accumulation. Pull requests pile up, traces go unread, exceptions are ignored, and teams begin to lose understanding of what the system is doing.
This is the orchestration tax of loop engineering. Every additional loop increases not only execution capacity, but also the burden of review, monitoring, and decision-making. Treating that burden as real is what prevents comprehension debt from accumulating.
Maturity develops in stages
Organizations typically adopt loop engineering through a series of maturity stages. These stages are not rigid, but they help leaders understand what capabilities and controls are required as autonomy increases.
Level 0: Manual prompting
A human drives every turn. The system assists, but the person remains the loop.
Level 1: Assisted execution
An agent can use tools to complete bounded tasks, but a human invokes the run and reviews the result.
Level 2: Verified execution
A verification layer is added. Graders, tests, rules, or human reviewers catch defined classes of error before output is accepted.
Level 3: Event-driven operation
Loops run in the background based on schedules, webhooks, alerts, or workflow events. The system begins to surface and act on work without being explicitly prompted each time.
Level 4: System-level improvement
Execution traces are analyzed to improve prompts, tools, policies, routing logic, and verification criteria over time. At this stage, fleets of loops may operate under defined human gates, budget limits, and governance controls.
Most organizations will begin between Levels 1 and 2. The larger gains usually appear at Levels 3 and 4, where loops become embedded in operational workflows. Those levels also require stronger oversight, clearer ownership, and more mature observability.
Ownership must become explicit
A loop engineering system cannot be owned informally once it touches production workflows. At scale, several responsibilities need clear owners.
Someone must own the loop design: what the system is allowed to do, what triggers it, and when it should stop. Someone must own verification: the graders, tests, rubrics, and acceptance criteria used to determine whether output is good enough. Someone must own observability: traces, logs, metrics, alerts, and incident review. Someone must own permissions and approval gates, especially for actions involving production systems, customer-facing output, data access, or financial impact.
In a small experiment, one person may cover all of these responsibilities. In an enterprise environment, treating them as one undifferentiated role creates risk. Loop engineering becomes sustainable only when responsibility is separated clearly enough that failures can be detected, explained, and corrected.
The cultural risk is loss of judgment
The most important operating-model risk is cultural, not technical. A well-designed loop can help a team move faster on work it understands deeply. A poorly governed loop can also help a team avoid understanding the work at all.
The difference is not visible in the architecture alone. Two teams can use similar tools and build similar loops, but produce opposite outcomes. One team uses loops to accelerate work while continuing to inspect traces, review decisions, and refine judgment. The other treats the loop as a substitute for understanding and gradually loses visibility into its own product.
Leadership has to make that distinction explicit. Loop engineering should increase organizational learning, not replace it. The goal is not to remove humans from the system, but to move human attention to the points where judgment, accountability, and domain understanding matter most.
Streamline your operational workflows with ZBrain AI agents designed to address enterprise challenges.
How to measure loop engineering performance
A loop engineering system that runs unattended needs to be measured as a system, not as a model. Without clear metrics, it becomes difficult to know whether the loop is improving throughput, reducing manual effort, maintaining quality, or simply creating more automated activity for humans to clean up later.
The purpose of measurement is not only to prove that a loop works. It is to determine whether the loop is becoming more reliable, more economical, and more aligned with the organization’s operating standards over time. The metrics below form a practical scorecard that teams can adapt to their own workflows.
Convergence rate
Convergence rate measures the percentage of loop runs that complete the intended task, satisfy the defined stopping condition, and pass verification without requiring human intervention.
This is the most direct measure of whether the loop can complete work independently. A high convergence rate indicates that the loop has enough context, tool access, verification, and stopping logic to resolve tasks within its intended scope. A low convergence rate suggests that the loop is either under-specified, poorly tooled, or being applied to work that still requires human judgment.
Escalation rate
Escalation rate measures how often work is routed to a human review or triage queue.
Escalation is not inherently bad; well-designed loops should escalate uncertainty rather than force low-confidence decisions. The important signal is whether escalation becomes more precise over time. As skills, memory, and verification improve, the loop should escalate fewer routine cases and reserve human attention for genuinely ambiguous, sensitive, or high-impact decisions.
Cost per resolved task
Cost per resolved task measures the total model, compute, and tool usage required to complete a unit of work.
This is the core economic metric for loop engineering. A loop that resolves tasks but consumes more resources than the work is worth is not operationally successful. Tracking cost per resolved task keeps efficiency visible and helps teams decide where to use expensive sub-agents, stronger models, or additional verification steps.
Human review time per task
Human review time per task measures the amount of human effort required to inspect, approve, correct, or complete the loop’s output.
This metric captures the orchestration overhead of loop engineering. If review time rises as loop usage grows, the system may be shifting work rather than reducing it. Rising review time can also indicate weak verification, unclear ownership, excessive escalation, or growing comprehension debt.
Defect and rework rate
Defect and rework rate measures the quality of completed work after it has passed through the loop.
This is the guardrail against false progress. A loop may appear successful because it closes tasks, passes graders, or opens pull requests, but downstream defects reveal whether the system is actually producing reliable outcomes. Rework should be tracked both as a quality measure and as feedback for improving stopping conditions, skills, graders, and escalation rules.
Trace quality and recurrence signals
Trace quality measures whether each run produces enough structured information to explain what happened, why decisions were made, which tools were used, and where failures occurred.
Recurrence signals measure how often the same failure pattern appears across traces. Repeated failures are especially valuable because they show where the loop’s design needs improvement. They may point to missing skills, weak verification criteria, insufficient context, unreliable tools, or unclear stopping conditions.
Together, trace quality and recurrence signals provide the evidence base for improving the loop over time.
Improvement over successive cycles
The most important measurement question is whether the loop is getting better across repeated cycles.
At higher maturity levels, loop engineering should produce visible improvement in convergence, escalation precision, cost efficiency, review burden, and defect rates. If those metrics do not improve over time, the system may be automated, but it is not meaningfully learning from its own operation.
The essential discipline is to measure loop performance at the system level. The goal is not to prove that the underlying model is capable in isolation, but to determine whether the full loop—triggers, tools, skills, verification, memory, state, and human gates—is becoming more reliable and valuable over time.
What comes next for loop engineering
Loop engineering is still early, so any view of its future should be treated as a set of informed possibilities rather than a settled roadmap. Even so, several directions are becoming visible as agent systems move from individual workflows toward larger operational environments.
Improvement moves deeper into the system
Today, most improvement loops focus on the components that are easiest to change: prompts, tool selection, grader configuration, routing logic, and context assembly. Over time, the same trace and evaluation data can be used to optimize deeper parts of the system.
For teams running open-weight models, execution traces and verification outcomes may become training signals for model fine-tuning or reinforcement learning. For other teams, the improvement may happen in surrounding systems: better memory structures, cleaner retrieval, more precise skills, stronger evaluation criteria, or more reliable tool policies.
The important point is that loop engineering is not tied to one optimization target. The loop is the improvement mechanism; what it improves can expand as the system matures.
Individual loops can become managed fleets
Most teams begin with one carefully bounded loop. The natural next step is multiple loops operating across repositories, workflows, business functions, or operational domains.
At that point, the challenge changes. The question is no longer only whether a single loop works, but whether many loops can be coordinated, governed, monitored, and audited together. This requires shared infrastructure: common policies, approval gates, trace standards, cost controls, observability pipelines, and ownership models.
In enterprise environments, this fleet layer is where loop engineering becomes an operating capability rather than a productivity experiment.
The strategic value may come from compounding learning
The long-term advantage of loop engineering is not simply that tasks are completed faster. It is that each run can produce feedback that improves future runs.
When teams preserve traces, review outputs, update skills, refine graders, and adjust orchestration logic, the system accumulates operational knowledge. Over time, that creates a compounding effect: human judgment improves the loop, and the loop returns better evidence for human judgment.
This is why loop engineering belongs on a leadership agenda as well as an engineering backlog. The organizations that benefit most will be those that treat loops as learning systems, not just automation scripts.
The right posture remains cautious
The case for loop engineering should not be confused with a case for unchecked autonomy. The discipline is still young, costs can rise quickly, and poorly governed loops can create the illusion of progress while increasing defects, review load, or comprehension debt.
There is also a broader organizational risk: if teams use loops to avoid understanding the work, automation can gradually weaken the very judgment it depends on. Direct prompting, manual review, and hands-on engineering will continue to matter. The goal is not to remove human engagement, but to shift it toward the points where it creates the most value.
Loop engineering rewards teams that remain actively involved in the systems they build. The strongest organizations will not be those that let loops run unchecked, but those that design loops they can continue to understand, inspect, and improve.
Endnote
The shift at the center of loop engineering is a shift in where leverage sits. The work moves from prompting agents one turn at a time to designing the systems that prompt, evaluate, continue, and constrain them. As models become more capable, the scarce skill is no longer only writing the right instruction; it is building the architecture around the agent, which includes the triggers, isolated workspaces, reusable skills, connectors, verification layers, memory, and stopping conditions that allow work to continue without a human steering every step.
That is also why loop engineering should be treated with care. The loop will not decide whether it is extending judgment or replacing it. It will simply follow the system it has been given. Designed well, it can compound capability, reduce repetitive coordination, and turn organizational knowledge into a durable operating advantage. Designed as a way to avoid understanding the work, it can compound errors, weaken accountability, and create distance between teams and the systems they own.
The best posture is therefore not blind automation, but disciplined engineering. Build the loop, but stay close enough to understand what it is doing, why it is doing it, and when it should stop. The leverage point has moved; the responsibility has not.
ZBrain helps enterprises build governed agentic workflows that use business context, connect with operational systems, and support controlled execution across processes. Explore ZBrain to build enterprise-ready agentic solutions.
Author’s Bio


CEO LeewayHertz
An early adopter of emerging technologies, Akash leads innovation in AI, driving transformative solutions that enhance business operations. With his entrepreneurial spirit, technical acumen and passion for AI, Akash continues to explore new horizons, empowering businesses with solutions that enable seamless automation, intelligent decision-making, and next-generation digital experiences.
Table of content
- What loop engineering is and where it sits
- Why loop engineering is emerging now
- Anatomy of a loop: The building blocks
- How a loop engineering system operates end-to-end
- How to implement loop engineering systems
- Enterprise concerns: Governance, security, cost, and reliability
- Failure patterns in loop engineering systems
- How loop engineering changes team operating models
- How to measure loop engineering performance
- What comes next for loop engineering
Share Article


Frequently Asked Questions
What is loop engineering?
Loop engineering is the practice of designing feedback systems around AI agents so they can continue working toward a defined goal without a human steering every step. Instead of prompting an agent one turn at a time, teams design the system that triggers agent runs, supplies context, verifies outputs, records state, escalates uncertainty, and determines when the work should stop.
How is loop engineering different from prompt engineering?
Prompt engineering focuses on improving the instruction given to a model. Loop engineering operates at a higher system level. It designs the control structure around the agent: when it should run, what tools it can use, how its output should be evaluated, what happens after each run, and how progress should carry forward over time. Good prompts still matter, but they become one component inside a broader feedback system.
How is loop engineering different from an agentic loop?
An agentic loop operates inside a single agent run. It is the cycle where the agent reasons, uses tools, observes results, and repeats until the task is complete or a stopping condition is met. Loop engineering operates above that level. It coordinates multiple runs over time, manages state across executions, triggers new work, applies verification, and escalates cases that require human judgment.
Is loop engineering just a scheduled automation or a cron job?
No. A scheduled automation runs predefined commands at a set time. A loop engineering system may run on a schedule, but the thing being scheduled is adaptive. The agent inspects the current state, chooses actions based on that state, evaluates results, and decides whether to continue, stop, retry, or escalate. From the outside, it may look like scheduled execution; internally, it is a state-aware feedback system.
Why is loop engineering becoming important now?
Loop engineering is becoming important because AI agents are increasingly capable of sustaining multi-step work without constant human intervention. As model capability improves, the main challenge shifts from producing a single good response to orchestrating repeated work safely and reliably. Teams now need systems for triggering, verifying, persisting, governing, and improving agent behavior over time.
What are the main building blocks of a loop engineering system?
A loop engineering system typically includes a clear stopping condition, triggers or automations, workspace isolation, reusable skills, connectors to external tools, sub-agents or verification components, and persistent state. Each building block addresses a specific failure mode. For example, stopping conditions prevent runaway execution, state prevents repeated work, and verification reduces the risk of unchecked errors.
Why does verification matter in loop engineering?
Verification matters because an unattended loop can make mistakes without a human noticing each step. A verification layer checks whether the output meets defined criteria before it is accepted or passed forward. Verification may include deterministic checks, such as tests and linting, or model-based evaluation against a rubric. In higher-stakes workflows, human review may remain part of the verification process.
What role does human oversight play in loop engineering?
Human oversight remains essential. Loop engineering does not remove people from the system; it moves human judgment to the points where it matters most. Humans may approve sensitive actions, review uncertain outputs, validate subjective decisions, or authorize changes to the loop itself. The goal is not unchecked autonomy, but controlled execution with clear escalation paths.
What are the biggest risks of loop engineering?
The main risks include unclear stopping conditions, weak verification, excessive permissions, poor observability, uncontrolled costs, and loss of human understanding. A flawed loop can repeat errors, generate unnecessary work, or take actions beyond its intended scope. These risks make governance, security, traceability, and human review central to enterprise adoption.
How should enterprises measure loop engineering performance?
Enterprises should measure loop engineering at the system level rather than only evaluating the model. Useful metrics include convergence rate, escalation rate, cost per resolved task, human review time per task, defect and rework rate, and trace quality. These metrics show whether the loop is completing work reliably, economically, and with appropriate oversight.
What is the convergence rate in loop engineering?
Convergence rate measures how often a loop can complete an assigned task, meet its defined stopping condition, and pass verification without human intervention. It is one of the clearest indicators of whether a loop is operating effectively within its intended scope.
Can loop engineering apply outside software development?
Yes. Although the term has gained attention through coding agents, the pattern applies to any domain where an agent can observe state, take actions, verify progress, and continue toward a defined outcome. Examples include documentation, customer support, operations, research, compliance workflows, and internal business process automation.
Is loop engineering ready for enterprise use?
Loop engineering is still an emerging discipline, but many of its underlying components are already used in enterprise AI systems. The readiness depends on scope, controls, and risk level. Low-risk workflows with clear stopping conditions and strong verification are better starting points. High-impact workflows require stronger governance, auditability, permissions management, and human approval gates.
What is the long-term value of loop engineering?
The long-term value of loop engineering lies in compounding improvement. Each run can produce traces, feedback, and operational knowledge that improve future runs. When designed well, loop engineering helps organizations move from isolated AI agent experiments to governed, workflow-aware systems that can execute, verify, learn, and improve over time.
Insights
The AI trust gap: Why governance architecture determines enterprise value
The trust gap surrounding enterprise AI is fundamentally an architectural challenge, and its solution is increasingly well understood.
The AI ROI illusion: Why enterprises struggle to measure AI impact
Organizations with stronger measurement discipline are better positioned to link AI deployments to measurable business outcomes, prioritize high-impact use cases across the enterprise, allocate capital more effectively, and continuously refine models using real-world performance feedback.
The agentic enterprise: Why AI success requires an operating model redesign
Organizations that redesign their operating models around agentic AI are beginning to outperform those that apply AI only incrementally.
Enterprise AI pilot-to-production gap: Root causes & how to address them
The underlying cause is structural. In many enterprises, AI pilots are developed on infrastructure that was not designed to support production deployment.
Solution architecture best practices: A guide for enterprise teams
The architecture design process culminates in a set of documented artifacts that communicate the solution to development, operations, and business teams.

Common solution architecture design challenges and solutions
Solution architecture must evolve from fragmented documentation practices to a structured, collaborative, and continuously validated design capability.

Why structured architecture design is the foundation of scalable enterprise systems
Structured architecture design guides enterprises from requirements to build-ready blueprints. Learn key principles, scalability gains, and TechBrain’s approach.
Intranet search engine guide: How it works, use cases, challenges, strategies and future trends
Effective intranet search is a cornerstone of the modern digital workplace, enabling employees to find trusted information quickly and work with greater confidence.
Company knowledge base: Why it matters and how it is evolving
A centralized company knowledge base is no longer a “nice-to-have” – it’s essential infrastructure. A knowledge base serves as a single source of truth: a unified repository where documentation, FAQs, manuals, project notes, institutional knowledge, and expert insights can reside and be easily accessed.
